

Author🐯 Tigerfive
容器编排之战
Kubernetes是谷歌严格保密十几年的秘密武器—Borg的一个开源版本,是Docker分布式系统解决方案。
2014年由Google公司启动
Borg
Borg是谷歌内部使用的大规模集群管理系统,基于容器技术,目的是实现资源管理的自动化,以及跨多个数据中心的资源利用率的最大化
容器编排引擎三足鼎立:
Mesos
Docker Swarm+compose
Kubernetes
早在 2015 年 5 月,Kubernetes 在 Google 上的搜索热度就已经超过了 Mesos 和 Docker Swarm,从那儿之后更是一路飙升,将对手甩开了十几条街,容器编排引擎领域的三足鼎立时代结束。
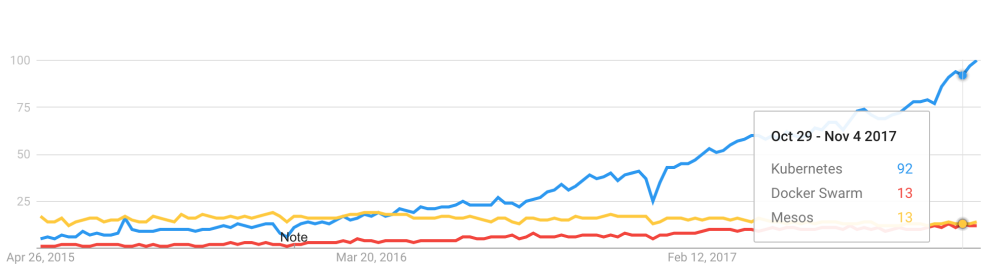
目前,AWS、Azure、Google、阿里云、腾讯云等主流公有云提供的是基于 Kubernetes 的容器服务;Rancher、CoreOS、IBM、Mirantis、Oracle、Red Hat、VMWare 等无数厂商也在大力研发和推广基于 Kubernetes 的容器 CaaS 或 PaaS 产品。可以说,Kubernetes 是当前容器行业最炙手可热的明星。
Google 的数据中心里运行着超过 20 亿个容器,而且 Google 十几年前就开始使用容器技术。
最初,Google 开发了一个叫 Borg 的系统(现在命名为 Omega)来调度如此庞大数量的容器和工作负载。在积累了这么多年的经验后,Google 决定重写这个容器管理系统,并将其贡献到开源社区,让全世界都能受益。这个项目就是 Kubernetes。简单的讲,Kubernetes 是 Google Omega 的开源版本。
跟很多基础设施领域先有工程实践、后有方法论的发展路线不同,Kubernetes 项目的理论基础则要比工程实践走得靠前得多,这当然要归功于 Google 公司在 2015 年 4 月发布的 Borg 论文了。
Borg 系统,一直以来都被誉为 Google 公司内部最强大的"秘密武器"。虽然略显夸张,但这个说法倒不算是吹牛。
因为,相比于 Spanner、BigTable 等相对上层的项目,Borg 要承担的责任,是承载 Google 公司整个基础设施的核心依赖。在 Google 公司已经公开发表的基础设施体系论文中,Borg 项目当仁不让地位居整个基础设施技术栈的最底层。
由于这样的定位,Borg 可以说是 Google 最不可能开源的一个项目。而幸运地是,得益于 Docker 项目和容器技术的风靡,它却终于得以以另一种方式与开源社区见面,这个方式就是 Kubernetes 项目。
所以,相比于"小打小闹"的 Docker 公司、"旧瓶装新酒"的 Mesos 社区,Kubernetes 项目从一开始就比较幸运地站上了一个他人难以企及的高度:在它的成长阶段,这个项目每一个核心特性的提出,几乎都脱胎于 Borg/Omega 系统的设计与经验。更重要的是,这些特性在开源社区落地的过程中,又在整个社区的合力之下得到了极大的改进,修复了很多当年遗留在 Borg 体系中的缺陷和问题。
所以,尽管在发布之初被批评是"曲高和寡",但是在逐渐觉察到 Docker 技术栈的"稚嫩"和 Mesos 社区的"老迈"之后,这个社区很快就明白了:k8s 项目在 Borg 体系的指导下,体现出了一种独有的"先进性"与"完备性",而这些特质才是一个基础设施领域开源项目赖以生存的核心价值。
为什么是编排
一个正在运行的 Linux 容器,可以分成两部分看待:
1. 容器的静态视图
一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分称为"容器镜像"(Container Image)
2. 容器的动态视图
一个由 Namespace+Cgroups 构成的隔离环境,这一部分称为"容器运行时"(Container Runtime)
作为一名开发者,其实并不关心容器运行时的差异。在整个"开发 - 测试 - 发布"的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。
这正是容器技术圈在 Docker 项目成功后不久,就迅速走向了"容器编排"这个"上层建筑"的主要原因:作为一家云服务商或者基础设施提供商,我只要能够将用户提交的 Docker 镜像以容器的方式运行起来,就能成为这个非常热闹的容器生态图上的一个承载点,从而将整个容器技术栈上的价值,沉淀在我的这个节点上。
更重要的是,只要从这个承载点向 Docker 镜像制作者和使用者方向回溯,整条路径上的各个服务节点,比如 CI/CD、监控、安全、网络、存储等等,都有可以发挥和盈利的余地。这个逻辑,正是所有云计算提供商如此热衷于容器技术的重要原因:通过容器镜像,它们可以和潜在用户(即,开发者)直接关联起来。
从一个开发者和单一的容器镜像,到无数开发者和庞大的容器集群,容器技术实现了从"容器"到"容器云"的飞跃,标志着它真正得到了市场和生态的认可。
这样,容器就从一个开发者手里的小工具,一跃成为了云计算领域的绝对主角;而能够定义容器组织和管理规范的"容器编排"技术,则当仁不让地坐上了容器技术领域的"头把交椅"。
最具代表性的容器编排工具:
1. Docker 公司的 Compose+Swarm 组合
2. Google 与 RedHat 公司共同主导的 Kubernetes 项目
理解容器编排
Docker平台以及周边生态系统包含很多工具来管理容器的生命周期。例如,Docker Command Line Interface(CLI)满足在单个主机上管理容器的需求,但是面对部署在多个主机上的容器时就无所适从了。为了超越单个容器管理,我们必须转向编排工具。容器编排工具将生命周期管理能力扩展到部署在大量机器集群上部署的复杂的、多容器工作负载。
容器编排工具为开发人员和基础设施团队提供了一个抽象层来处理大规模的容器化部署。容器编排工具提供的特征在众多提供者之间有所不同,然而常见的公共特征包含准备、发现、资源管理、监视和部署。
由于微服务将应用程序分解为不同的微应用程序,许多开发人员会请求更多的服务器节点进行部署。为了正确地管理微服务,开发者倾向于在每个VM中部署一个微服务,这进一步降低了资源利用率。在许多情况下,这会导致CPU和内存的过度分配。
在许多部署中,微服务的高可用性需求迫使工程师添加越来越多的服务实例来进行冗余。实际上,尽管它提供了所需的高可用性,但这将导致出现一些未充分利用的服务器实例。一般而言,与单一应用程序部署相比,微服务部署需要更多的基础设施。由于基础设施成本的增加,许多组织未能看到微服务的价值。
为了解决上面提到的问题,我们需要一个工具能做到以下几点:
活动自动化。例如有效地向基础设施分配容器,这一行为对开发人员和管理员都是透明的。
为开发人员提供一个抽象层,以便他们可以在不知道使用哪个机器托管他们的应用程序的情况下,将应用程序部署到数据中心。
对部署设置规则或约束。
提供更高的敏捷性,为开发人员和管理员提供最小的管理开销和最少的人为交互。
通过最大限度地利用可用资源,有效地构建、部署和管理应用程序。
典型的容器编排工具有助于虚拟化一组机器并将它们作为单个集群管理。容器编排工具也有助于将机器上的工作负载或容器移动到消费者透明的位置。很多工具目前既支持基于DOCKER的容器,也支持非容器化二进制文件部署,例如独立的Spring Boot应用程序。这些容器编排工具的基本功能是从应用程序中抽象出实际的服务器实例。
容器编排工具的一些关键能力概括如下:
集群管理:将虚拟机和物理机器的集群管理为一台大型机器。这些机器在资源能力方面可能有些差异,但大体上都是以Linux作为操作系统的机器。这些虚拟集群可以建立在云上、本地或两者的混合。
部署:能处理有大量机器的应用程序和容器的自动部署。支持多个版本的应用程序容器,并且还支持跨越大量集群机器的滚动升级。这些工具还能够处理故障回滚。
可伸缩性:支持应用实例的自动和手动伸缩,以性能优化为主要目标。
健康:它管理集群、节点和应用程序的健康。可以从集群中移除异常的机器和应用程序实例。
基础结构抽象化:开发人员不必担心机器、容量等问题。完全是容器编排工具来决定如何调度和运行应用程序。这些工具也抽象化机器的细节、能力、使用和位置。对于应用程序所有者来说,它们相当于一个容量几乎无限的大型机器。
资源优化:这些工具以有效的方式在一组可用机器上分配容器工作负载,从而降低成本,通过从简单的到复杂的算法可有效地提高利用率。
资源分配:基于应用程序开发人员设置的资源可用性和约束来分配服务器。资源分配将基于约束、规则、端口要求、应用依赖性、健康等等。
服务可用性:确保服务在集群中正常运行。在机器故障的情况下,容器编排会自动通过在集群中的其他机器上重新启动这些服务来处理故障。
敏捷性:敏捷性工具能够快速分配工作负载到可用资源,或者在资源需求发生变化时跨机器移动工作量。此外,可以根据业务临界性、业务优先级等来设置约束重新调整资源。
隔离:一些工具提供了资源隔离。因此,即使应用程序不是容器化的,也可以实现资源隔离。
Kubernetesh介绍
首先,他是一个全新的基于容器技术的分布式架构领先方案。Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg)。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。
Kubernetes是一个完备的分布式系统支撑平台,具有完备的集群管理能力,多扩多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、內建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及多粒度的资源配额管理能力。同时Kubernetes提供完善的管理工具,涵盖了包括开发、部署测试、运维监控在内的各个环节。
Kubernetes中,Service是分布式集群架构的核心,一个Service对象拥有如下关键特征:
拥有一个唯一指定的名字
拥有一个虚拟IP(Cluster IP、Service IP、或VIP)和端口号
能够体统某种远程服务能力
被映射到了提供这种服务能力的一组容器应用上
Service的服务进程目前都是基于Socket通信方式对外提供服务,比如Redis、Memcache、MySQL、Web Server,或者是实现了某个具体业务的一个特定的TCP Server进程,虽然一个Service通常由多个相关的服务进程来提供服务,每个服务进程都有一个独立的Endpoint(IP+Port)访问点,但Kubernetes能够让我们通过服务连接到指定的Service上。有了Kubernetes透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响我们队服务的正常调用,更重要的是这个Service本身一旦创建就不会发生变化,意味着在Kubernetes集群中,我们不用为了服务的IP地址的变化问题而头疼了。
容器提供了强大的隔离功能,所有有必要把为Service提供服务的这组进程放入容器中进行隔离。为此,Kubernetes设计了Pod对象,将每个服务进程包装到相对应的Pod中,使其成为Pod中运行的一个容器。为了建立Service与Pod间的关联管理,Kubernetes给每个Pod贴上一个标签Label,比如运行MySQL的Pod贴上name=mysql标签,给运行PHP的Pod贴上name=php标签,然后给相应的Service定义标签选择器Label Selector,这样就能巧妙的解决了Service于Pod的关联问题。
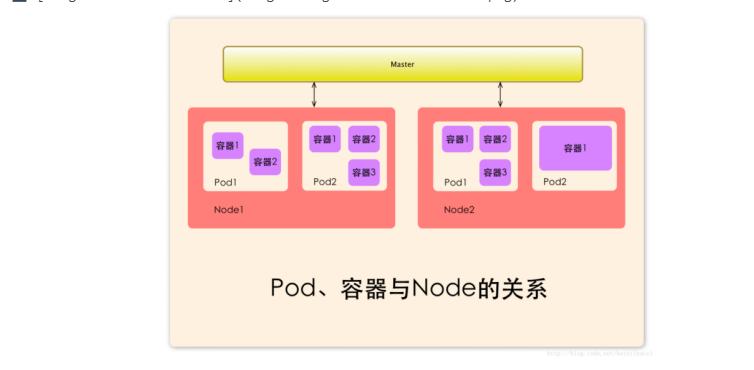
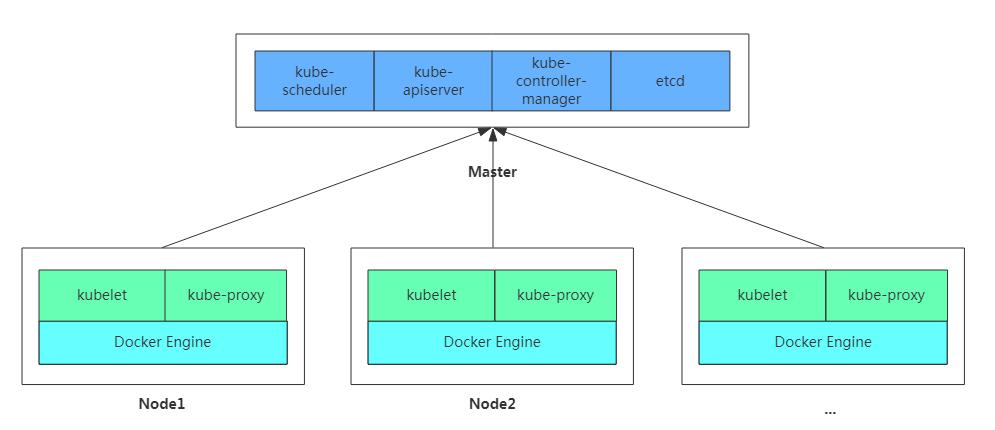
在集群管理方面,Kubernetes将集群中的机器划分为一个Master节点和一群工作节点Node,其中,在Master节点运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理能力,并且都是全自动完成的。Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。Node上运行着Kubernetes的kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁以及实现软件模式的负载均衡器。
在Kubernetes集群中,它解决了传统IT系统中服务扩容和升级的两大难题。你只需为需要扩容的Service关联的Pod创建一个Replication Controller简称(RC),则该Service的扩容及后续的升级等问题将迎刃而解。在一个RC定义文件中包括以下3个关键信息。
目标Pod的定义
目标Pod需要运行的副本数量(Replicas)
要监控的目标Pod标签(Label)
在创建好RC后,Kubernetes会通过RC中定义的的Label筛选出对应Pod实例并实时监控其状态和数量,如果实例数量少于定义的副本数量,则会根据RC中定义的Pod模板来创建一个新的Pod,然后将新Pod调度到合适的Node上启动运行,知道Pod实例的数量达到预定目标,这个过程完全是自动化。
Kubernetes优势:
- 容器编排
- 轻量级
- 开源
- 弹性伸缩
- 负载均衡
Kubernetes 核心概念详解
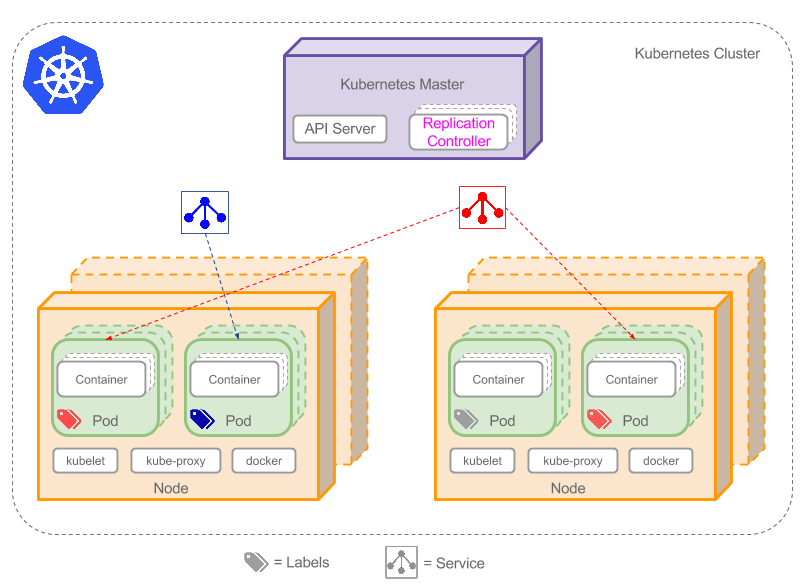
上图可以看到如下组件,使用特别的图标表示Service和Label:
• Pod
• Container(容器)
• Label( )(标签)
)(标签)
• Replication Controller(副本控制器)
• Service( )
)
• Node(节点)
• Kubernetes Master(Kubernetes控制节点)
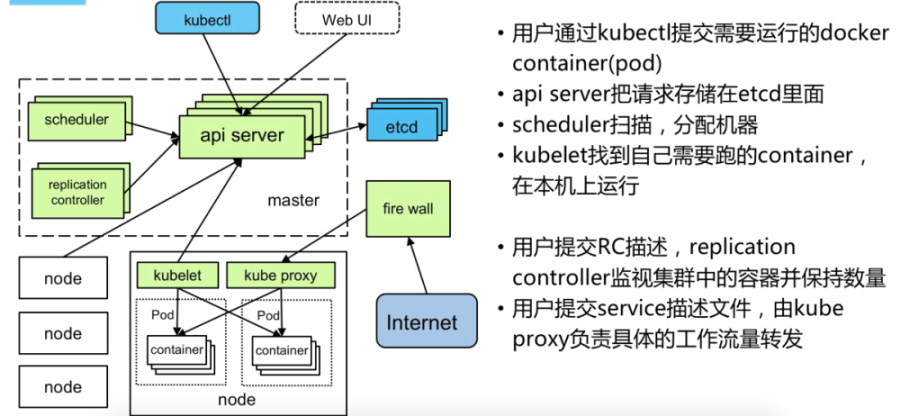
Master
Master主要负责资源调度,控制副本,和提供统一访问集群的入口。
Node
Node由Master管理,并汇报容器状态给Master,同时根据Master要求管理容器生命周期。
Node IP
Node节点的IP地址,是Kubernetes集群中每个节点的物理网卡的IP地址,是真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信;
Pod
Pod直译是豆荚,可以把容器想像成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚(一个Pod)。在k8s中我们不会直接操作容器,而是把容器包装成Pod再进行管理
运行于Node节点上, 若干相关容器的组合。Pod内包含的容器运行在同一宿主机上,使用相同的网络命名空间、IP地址和端口,能够通过localhost进行通信。Pod是k8s进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。
Pod 就是 k8s 世界里的"应用";而一个应用,可以由多个容器组成。
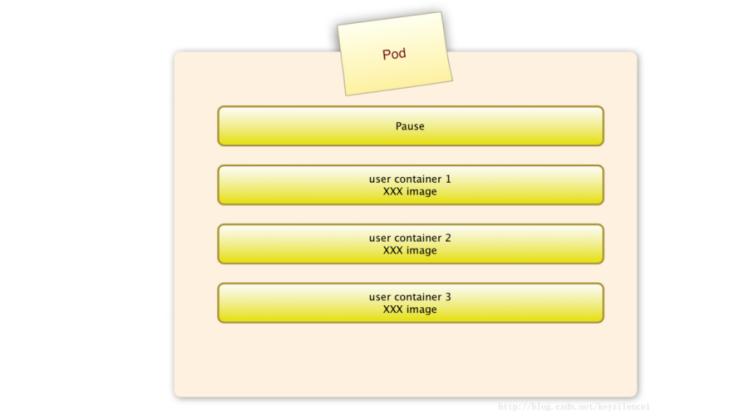
pause容器
每个Pod中都有一个pause容器,pause容器做为Pod的网络接入点,Pod中其他的容器会使用容器映射模式启动并接入到这个pause容器。
属于同一个Pod的所有容器共享网络的namespace。
一个Pod里的容器与另外主机上的Pod容器能够直接通信;
如果Pod所在的Node宕机,会将这个Node上的所有Pod重新调度到其他节点上;
Pod Volume:
Docker Volume对应Kubernetes中的Pod Volume;
资源限制:
每个Pod可以设置限额的计算机资源有CPU和Memory;
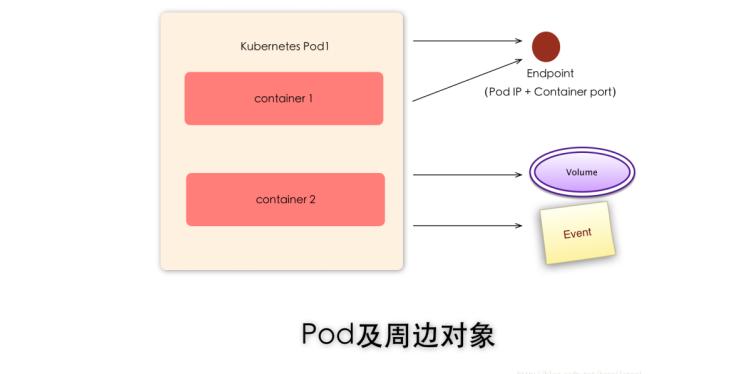
Event
是一个事件记录,记录了事件最早产生的时间、最后重复时间、重复次数、发起者、类型,以及导致此事件的原因等信息。Event通常关联到具体资源对象上,是排查故障的重要参考信息
Pod IP
Pod的IP地址,是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,位于不同Node上的Pod能够彼此通信,需要通过Pod IP所在的虚拟二层网络进行通信,而真实的TCP流量则是通过Node IP所在的物理网卡流出的;
Namespace
命名空间将资源对象逻辑上分配到不同Namespace,可以是不同的项目、用户等区分管理,并设定控制策略,从而实现多租户。命名空间也称为虚拟集群。
Replica Set
确保任何给定时间指定的Pod副本数量,并提供声明式更新等功能。
Deployment
Deployment是一个更高层次的API对象,它管理ReplicaSets和Pod,并提供声明式更新等功能。
官方建议使用Deployment管理ReplicaSets,而不是直接使用ReplicaSets,这就意味着可能永远不需要直接操作ReplicaSet对象,因此Deployment将会是使用最频繁的资源对象。
RC-Replication Controller
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余pod数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
部署和升级Pod,声明某种Pod的副本数量在任意时刻都符合某个预期值;
• Pod期待的副本数;
• 用于筛选目标Pod的Label Selector;
• 当Pod副本数量小于预期数量的时候,用于创建新Pod的Pod模板(template);
Service
Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,用户不需要了解后台Pod是如何运行。
一个service定义了访问pod的方式,就像单个固定的IP地址和与其相对应的DNS名之间的关系。
Service其实就是我们经常提起的微服务架构中的一个"微服务",通过分析、识别并建模系统中的所有服务为微服务——Kubernetes Service,最终我们的系统由多个提供不同业务能力而又彼此独立的微服务单元所组成,服务之间通过TCP/IP进行通信,从而形成了我们强大而又灵活的弹性网络,拥有了强大的分布式能力、弹性扩展能力、容错能力;
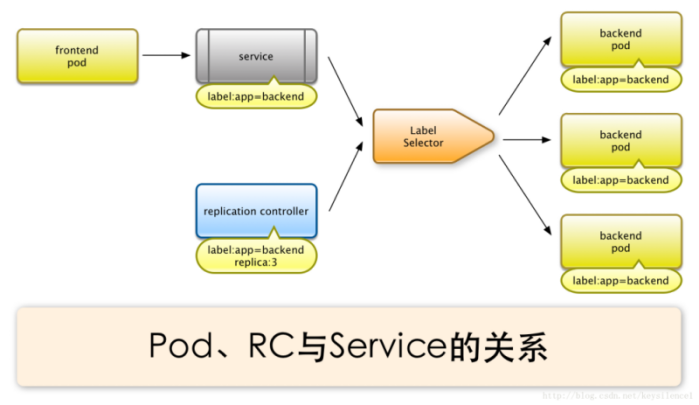
如图示,每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,多个Pod副本组成了一个集群来提供服务,一般的做法是部署一个负载均衡器来访问它们,为这组Pod开启一个对外的服务端口如8000,并且将这些Pod的Endpoint列表加入8000端口的转发列表中,客户端可以通过负载均衡器的对外IP地址+服务端口来访问此服务。运行在Node上的kube-proxy其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并且在内部实现服务的负载均衡与会话保持机制。Service不是共用一个负载均衡器的IP地址,而是每个Servcie分配一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP。
Cluster IP
Service的IP地址,特性:
仅仅作用于Kubernetes Servcie这个对象,并由Kubernetes管理和分配IP地址;
无法被Ping,因为没有一个"实体网络对象"来响应;
只能结合Service Port组成一个具体的通信端口;
Node IP网、Pod IP网域Cluster IP网之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与IP路由有很大的不同
(Cluster IP也叫internal IP集群内部资源提供服务 区别与 external IP对外提供服务,但只能在gc2上使用因特殊原因暂时不能用)
Label
Kubernetes中的任意API对象都是通过Label进行标识,Label的实质是一系列的K/V键值对。Label是Replication Controller和Service运行的基础,二者通过Label来进行关联Node上运行的Pod。
一个label是一个被附加到资源上的键/值对,譬如附加到一个Pod上,为它传递一个用户自定的并且可识别的属性.Label还可以被应用来组织和选择子网中的资源
selector是一个通过匹配labels来定义资源之间关系得表达式,例如为一个负载均衡的service指定所目标Pod
Label可以附加到各种资源对象上,一个资源对象可以定义任意数量的Label。给某个资源定义一个Label,相当于给他打一个标签,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象。我们可以通过给指定的资源对象捆绑一个或多个Label来实现多维度的资源分组管理功能,以便于灵活、方便的进行资源分配、调度、配置、部署等管理工作;
Node
Node是Kubernetes集群架构中运行Pod的服务节点(亦叫agent或minion)。Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。
Endpoint(IP+Port)
标识服务进程的访问点;
注:Node、Pod、Replication Controller和Service等都可以看作是一种"资源对象",几乎所有的资源对象都可以通过Kubernetes提供的kubectl工具执行增、删、改、查等操作并将其保存在etcd中持久化存储。
Volume
数据卷,挂载宿主机文件、目录或者外部存储到Pod中,为应用服务提供存储,也可以Pod中容器之间共享数据。
StatefulSet
StatefuleSet主要用来部署有状态应用,能够保证 Pod 的每个副本在整个生命周期中名称是不变的。而其他 Controller 不提供这个功能,当某个 Pod 发生故障需要删除并重新启动时,Pod 的名称会发生变化。同时 StatefuleSet 会保证副本按照固定的顺序启动、更新或者删除。
StatefulSet适合持久性的应用程序,有唯一的网络标识符(IP),持久存储,有序的部署、扩展、删除和滚动更新。
Kubernetes架构与组件
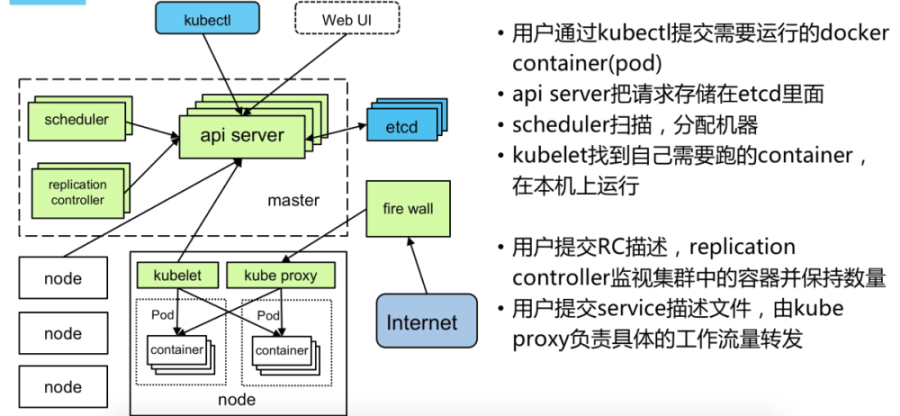
主从分布式架构,Master/Node
- 服务分组,小集群,多集群
- 服务分组,大集群,单集群
组件:
Kubernetes Master:
集群控制节点,负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都是发给它,它来负责具体的执行过程,我们后面所有执行的命令基本都是在Master节点上运行的;
包含如下组件:
1.Kubernetes API Server
作为Kubernetes系统的入口,其封装了核心对象的增删改查操作,以RESTful API接口方式提供给外部客户和内部组件调用。维护的REST对象持久化到Etcd中存储。
2.Kubernetes Scheduler
为新建立的Pod进行节点(node)选择(即分配机器),负责集群的资源调度。组件抽离,可以方便替换成其他调度器。
3.Kubernetes Controller
负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。
- Replication Controller
管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。 - Deployment Controller
管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和 Pod的更新。 - Node Controller
管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。 - Namespace Controller
管理维护Namespace,定期清理无效的Namespace,包括Namesapce下的API对象,比如Pod、Service等。 - Service Controller
管理维护Service,提供负载以及服务代理。 - EndPoints Controller
管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints。 - Service Account Controller
管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。 - Persistent Volume Controller
管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。 - Daemon Set Controller
管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。 - Job Controller
管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目 - Pod Autoscaler Controller
实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
Kubernetes Node:
除了Master,Kubernetes集群中的其他机器被称为Node节点,Node节点才是Kubernetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机,其上的工作负载会被Master自动转移到其他节点上去;
包含如下组件:
1.Kubelet
负责管控容器,Kubelet会从Kubernetes API Server接收Pod的创建请求,启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。
2.Kubernetes Proxy
负责为Pod创建代理服务,Kubernetes Proxy会从Kubernetes API Server获取所有的Service信息,并根据Service的信息创建代理服务,实现Service到Pod的请求路由和转发,从而实现Kubernetes层级的虚拟转发网络。
3.Docker Engine(docker),Docker引擎,负责本机的容器创建和管理工作;
数据库
etcd数据库,可以部署到master上,也可以独立部署
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息。
Kubernetes部署
二进制方式部署
部署kubernetes 集群-二进制方式(一)
部署方式:
方式1. minikube
Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,尝试Kubernetes或日常开发的用户使用。不能用于生产环境。
官方地址:https://kubernetes.io/docs/setup/minikube/
方式2. kubeadm
Kubeadm也是一个工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。
官方地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
方式3. 直接使用epel-release yum源,缺点就是版本较低
方式4. 二进制包
从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
官方也提供了一个互动测试环境供大家测试:https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/cluster-interactive/
https://kubernetes.io/docs/tutorials/kubernetes-basics/
目标任务:
1 Kubernetes集群部署架构规划
2 部署Etcd集群
3 在Node节点安装Docker
4 部署Flannel网络
5 在Master节点部署组件
6 在Node节点部署组件
7 查看集群状态
8 运行一个测试示例
9 部署Dashboard(Web UI)
固定IP、改名字、相互解析、关闭防火墙、先做个快照、时间同步
1、Kubernetes集群部署架构规划
操作系统:
CentOS7.6_x64
软件版本:
Docker 18.09.0-ce
Kubernetes 1.11
服务器角色、IP、组件:
k8s-master1
10.206.240.188 kube-apiserver,kube-controller-manager,kube-scheduler,etcd
k8s-master2
10.206.240.189 kube-apiserver,kube-controller-manager,kube-scheduler,etcd
k8s-node1
10.206.240.111 kubelet,kube-proxy,docker,flannel,etcd
k8s-node2
10.206.240.112 kubelet,kube-proxy,docker,flannel
Master负载均衡
10.206.176.19 LVS
镜像仓库
10.206.240.188 Harbor
拓扑图
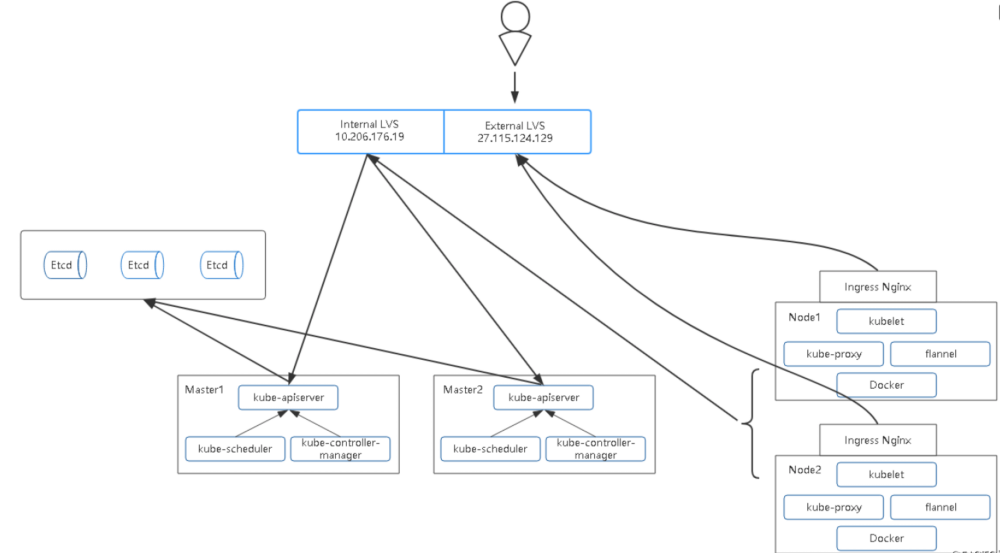
负载均衡器:
云环境:
可以采用slb
非云环境:
主流的软件负载均衡器,例如LVS、HAProxy、Nginx
这里采用Nginx作为apiserver负载均衡器,架构图如下:
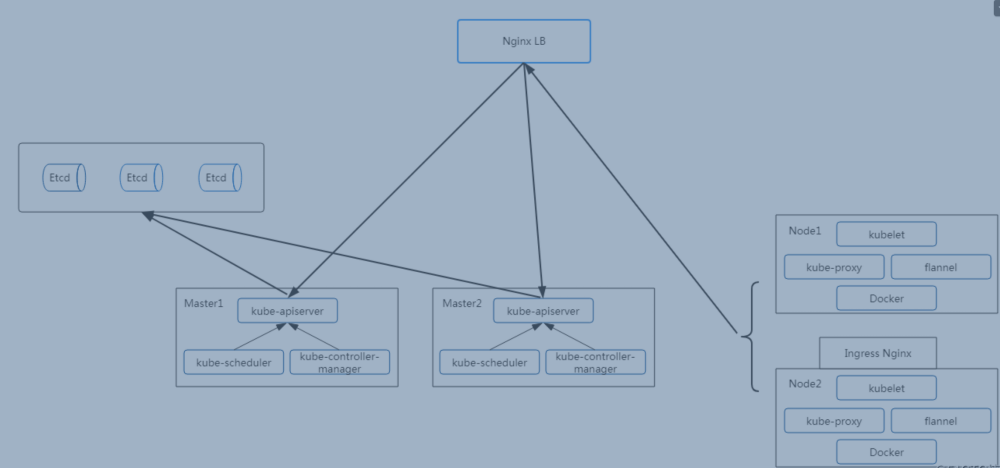
2. 安装nginx使用stream模块作4层反向代理配置如下:
user nginx;
worker_processes 4;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 10.206.240.188:6443;
server 10.206.240.189:6443;
}
server {
listen 6443;
proxy_pass k8s-apiserver;
}
}
3. 部署Etcd集群
使用cfssl来生成自签证书,任何机器都行,证书这块儿知道怎么生成、怎么用即可,暂且不用过多研究。
下载cfssl工具:
# wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
# wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
# wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
# chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
# mv cfssl_linux-amd64 /usr/local/bin/cfssl
# mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
# mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
生成Etcd证书:
创建以下三个文件:
# cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
# cat ca-csr.json
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
# cat server-csr.json
{
"CN": "etcd",
"hosts": [
"10.206.240.188",
"10.206.240.189",
"10.206.240.111"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
生成证书:
# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
# ls *pem
ca-key.pem ca.pem server-key.pem server.pem
安装Etcd:
二进制包下载地址:
https://github.com/coreos/etcd/releases/tag/v3.2.12
https://github.com/etcd-io/etcd/releases/download/v3.2.12/etcd-v3.2.12-linux-amd64.tar.gz
以下部署步骤在规划的三个etcd节点操作一样,唯一不同的是etcd配置文件中的服务器IP要写当前的:
解压二进制包:
# mkdir /opt/etcd/{bin,cfg,ssl} -p
# tar zxvf etcd-v3.2.12-linux-amd64.tar.gz
# mv etcd-v3.2.12-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
创建etcd配置文件:
# cat /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd01"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://10.206.240.189:2380"
ETCD_LISTEN_CLIENT_URLS="https://10.206.240.189:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://10.206.240.189:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://10.206.240.189:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://10.206.240.189:2380,etcd02=https://10.206.240.188:2380,etcd03=https://10.206.240.111:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
* ETCD_NAME 节点名称 修改
* ETCD_DATA_DIR 数据目录
* ETCD_LISTEN_PEER_URLS 集群通信监听地址 修改
* ETCD_LISTEN_CLIENT_URLS 客户端访问监听地址 修改
* ETCD_INITIAL_ADVERTISE_PEER_URLS 集群通告地址 修改
* ETCD_ADVERTISE_CLIENT_URLS 客户端通告地址 修改
* ETCD_INITIAL_CLUSTER 集群节点地址 修改
* ETCD_INITIAL_CLUSTER_TOKEN 集群Token
* ETCD_INITIAL_CLUSTER_STATE 加入集群的当前状态,new是新集群,existing表示加入已有集群
systemd管理etcd:
# cat /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd
ExecStart=/opt/etcd/bin/etcd \
--name=${ETCD_NAME} \
--data-dir=${ETCD_DATA_DIR} \
--listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \
--listen-client-urls=${ETCD_LISTEN_CLIENT_URLS},http://127.0.0.1:2379 \
--advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \
--initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \
--initial-cluster=${ETCD_INITIAL_CLUSTER} \
--initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \
--initial-cluster-state=new \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
把刚才生成的证书拷贝到配置文件中的位置:
# cp ca*pem server*pem /opt/etcd/ssl
启动并设置开启启动:
# systemctl start etcd
# systemctl enable etcd
都部署完成后,检查etcd集群状态:
# /opt/etcd/bin/etcdctl \
--ca-file=/opt/etcd/ssl/ca.pem --cert-file=/opt/etcd/ssl/server.pem --key-file=/opt/etcd/ssl/server-key.pem \
--endpoints="https://10.206.240.189:2379,https://10.206.240.188:2379,https://10.206.240.111:2379" \
cluster-health
member 18218cfabd4e0dea is healthy: got healthy result from https://10.206.240.111:2379
member 541c1c40994c939b is healthy: got healthy result from https://10.206.240.189:2379
member a342ea2798d20705 is healthy: got healthy result from https://10.206.240.188:2379
cluster is healthy
如果输出上面信息,就说明集群部署成功。
如果有问题第一步先看日志:/var/log/messages 或 journalctl -xeu etcd
报错:
Jan 15 12:06:55 k8s-master1 etcd: request cluster ID mismatch (got 99f4702593c94f98 want cdf818194e3a8c32)
解决:因为集群搭建过程,单独启动过单一etcd,做为测试验证,集群内第一次启动其他etcd服务时候,是通过发现服务引导的,所以需要删除旧的成员信息,所有节点作以下操作
[root@k8s-master1 default.etcd]# pwd
/var/lib/etcd/default.etcd
[root@k8s-master1 default.etcd]# rm -rf member/
在Node节点安装Docker
# yum install -y yum-utils device-mapper-persistent-data lvm2
# yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# yum install docker-ce -y
# curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://bc437cce.m.daocloud.io
# systemctl start docker
# systemctl enable docker
---
部署Flannel网络
工作原理:
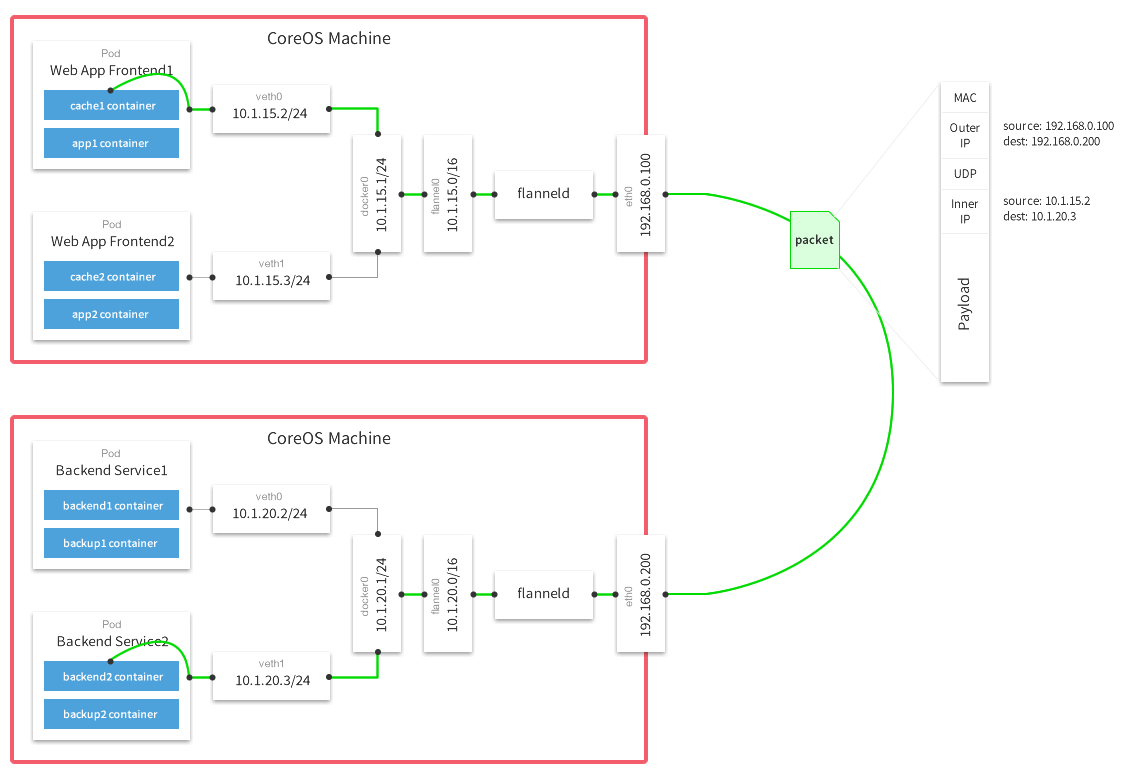
Falnnel要用etcd存储自身一个子网信息,所以要保证能成功连接Etcd,写入预定义子网段:
# /opt/etcd/bin/etcdctl \
--ca-file=ca.pem --cert-file=server.pem --key-file=server-key.pem \
--endpoints="https://10.206.240.189:2379,https://10.206.240.188:2379,https://10.206.240.111:2379" \
set /coreos.com/network/config '{ "Network": "172.17.0.0/16", "Backend": {"Type": "vxlan"}}'
先要切换到etc认证目录,即/opt/etcd/ssl/
以下部署步骤在规划的每个node节点都操作。
下载二进制包:
# wget https://github.com/coreos/flannel/releases/download/v0.10.0/flannel-v0.10.0-linux-amd64.tar.gz
# tar zxvf flannel-v0.10.0-linux-amd64.tar.gz
# mkdir -pv /opt/kubernetes/bin
# mv flanneld mk-docker-opts.sh /opt/kubernetes/bin
配置Flannel:
# mkdir -pv /opt/kubernetes/cfg/
# cat /opt/kubernetes/cfg/flanneld
FLANNEL_OPTIONS="--etcd-endpoints=https://10.206.240.189:2379,https://10.206.240.188:2379,https://10.206.240.111:2379 -etcd-cafile=/opt/etcd/ssl/ca.pem -etcd-certfile=/opt/etcd/ssl/server.pem -etcd-keyfile=/opt/etcd/ssl/server-key.pem"
systemd管理Flannel:
# cat /usr/lib/systemd/system/flanneld.service
[Unit]
Description=Flanneld overlay address etcd agent
After=network-online.target network.target
Before=docker.service
[Service]
Type=notify
EnvironmentFile=/opt/kubernetes/cfg/flanneld
ExecStart=/opt/kubernetes/bin/flanneld --ip-masq $FLANNEL_OPTIONS
ExecStartPost=/opt/kubernetes/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/subnet.env
Restart=on-failure
[Install]
WantedBy=multi-user.target
配置Docker启动指定子网段:
# cat /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/run/flannel/subnet.env
ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
从其他节点拷贝证书文件到node1和2上:因为node1和2上没有证书,但是flanel需要证书
# mkdir -pv /opt/etcd/ssl/
# scp /opt/etcd/ssl/* k8s-node2:/opt/etcd/ssl/
重启flannel和docker:
# systemctl daemon-reload
# systemctl start flanneld
# systemctl enable flanneld
# systemctl restart docker
检查是否生效:
# ps -ef |grep docker
root 20941 1 1 Jun28 ? 09:15:34 /usr/bin/dockerd --bip=172.17.34.1/24 --ip-masq=false --mtu=1450
# ip addr
3607: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 8a:2e:3d:09:dd:82 brd ff:ff:ff:ff:ff:ff
inet 172.17.34.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
3608: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP
link/ether 02:42:31:8f:d3:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.34.1/24 brd 172.17.34.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:31ff:fe8f:d302/64 scope link
valid_lft forever preferred_lft forever
确保docker0与flannel.1在同一网段。
测试不同节点互通,在当前节点访问另一个Node节点docker0 IP:
# ping 172.17.58.1
PING 172.17.58.1 (172.17.58.1) 56(84) bytes of data.
64 bytes from 172.17.58.1: icmp_seq=1 ttl=64 time=0.263 ms
64 bytes from 172.17.58.1: icmp_seq=2 ttl=64 time=0.204 ms
如果能通说明Flannel部署成功。如果不通检查下日志:journalctl -u flannel
部署kubernetes 集群-二进制方式(二)
在Master节点部署组件
两个Master节点部署方式一样
在部署Kubernetes之前一定要确保etcd、flannel、docker是正常工作的,否则先解决问题再继续。
生成证书
创建CA证书:
# cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
# cat ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
生成apiserver证书:
# cat server-csr.json
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1", //这个是后边dns要用的虚拟网络的网关,不用改,就用这个 切忌
"127.0.0.1",
"10.206.176.19",
"10.206.240.188",
"10.206.240.189",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
生成kube-proxy证书:
# cat kube-proxy-csr.json
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
最终生成以下证书文件:
# ls *pem
ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem server-key.pem server.pem
部署apiserver组件
下载二进制包:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.11.md
下载这个包(kubernetes-server-linux-amd64.tar.gz)就够了,包含了所需的所有组件。
[https://dl.k8s.io/v1.11.0/kubernetes-server-linux-amd64.tar.gz]
# mkdir /opt/kubernetes/{bin,cfg,ssl} -pv
# tar zxvf kubernetes-server-linux-amd64.tar.gz
# cd kubernetes/server/bin
# cp kube-apiserver kube-scheduler kube-controller-manager kubectl /opt/kubernetes/bin
从生成证书的机器拷贝证书到master1,master2:
# scp server.pem server-key.pem ca.pem ca-key.pem k8s-master1:/opt/kubernetes/ssl/
# scp server.pem server-key.pem ca.pem ca-key.pem k8s-master2:/opt/kubernetes/ssl/
创建token文件,后面会讲到:
# cat /opt/kubernetes/cfg/token.csv
674c457d4dcf2eefe4920d7dbb6b0ddc,kubelet-bootstrap,10001,"system:kubelet-bootstrap"
第一列:随机字符串,自己可生成
第二列:用户名
第三列:UID
第四列:用户组
创建apiserver配置文件:
# cat /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \
--v=4 \
--etcd-servers=https://10.206.240.189:2379,https://10.206.240.188:2379,https://10.206.240.111:2379 \
--bind-address=10.206.240.189 \
--secure-port=6443 \
--advertise-address=10.206.240.189 \
--allow-privileged=true \
--service-cluster-ip-range=10.0.0.0/24 \
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \
--authorization-mode=RBAC,Node \
--enable-bootstrap-token-auth \
--token-auth-file=/opt/kubernetes/cfg/token.csv \
--service-node-port-range=30000-50000 \
--tls-cert-file=/opt/kubernetes/ssl/server.pem \
--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \
--client-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \
--etcd-cafile=/opt/etcd/ssl/ca.pem \
--etcd-certfile=/opt/etcd/ssl/server.pem \
--etcd-keyfile=/opt/etcd/ssl/server-key.pem"
配置好前面生成的证书,确保能连接etcd。
参数说明:
* --logtostderr 启用日志
* --v 日志等级
* --etcd-servers etcd集群地址
* --bind-address 监听地址
* --secure-port https安全端口
* --advertise-address 集群通告地址
* --allow-privileged 启用授权
* --service-cluster-ip-range Service虚拟IP地址段 //这里就用这个网段,切忌不要改
* --enable-admission-plugins 准入控制模块
* --authorization-mode 认证授权,启用RBAC授权和节点自管理
* --enable-bootstrap-token-auth 启用TLS bootstrap功能,后面会讲到
* --token-auth-file token文件
* --service-node-port-range Service Node类型默认分配端口范围
systemd管理apiserver:
# cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-apiserver
ExecStart=/opt/kubernetes/bin/kube-apiserver $KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-apiserver
# systemctl start kube-apiserver
部署schduler组件
创建schduler配置文件:
# cat /opt/kubernetes/cfg/kube-scheduler
KUBE_SCHEDULER_OPTS="--logtostderr=true \
--v=4 \
--master=127.0.0.1:8080 \
--leader-elect"
参数说明:
* --master 连接本地apiserver
* --leader-elect 当该组件启动多个时,自动选举(HA)
systemd管理schduler组件:
# cat /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-scheduler
ExecStart=/opt/kubernetes/bin/kube-scheduler $KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-scheduler
# systemctl start kube-scheduler
部署controller-manager组件
创建controller-manager配置文件:
# cat /opt/kubernetes/cfg/kube-controller-manager
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=true \
--v=4 \
--master=127.0.0.1:8080 \
--leader-elect=true \
--address=127.0.0.1 \
--service-cluster-ip-range=10.0.0.0/24 \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \
--root-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem"
systemd管理controller-manager组件:
# cat /usr/lib/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-controller-manager
ExecStart=/opt/kubernetes/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-controller-manager
# systemctl start kube-controller-manager
所有组件都已经启动成功,通过kubectl工具查看当前集群组件状态:
# /opt/kubernetes/bin/kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
controller-manager Healthy ok
如上输出说明组件都正常。
-------
在Node节点部署组件
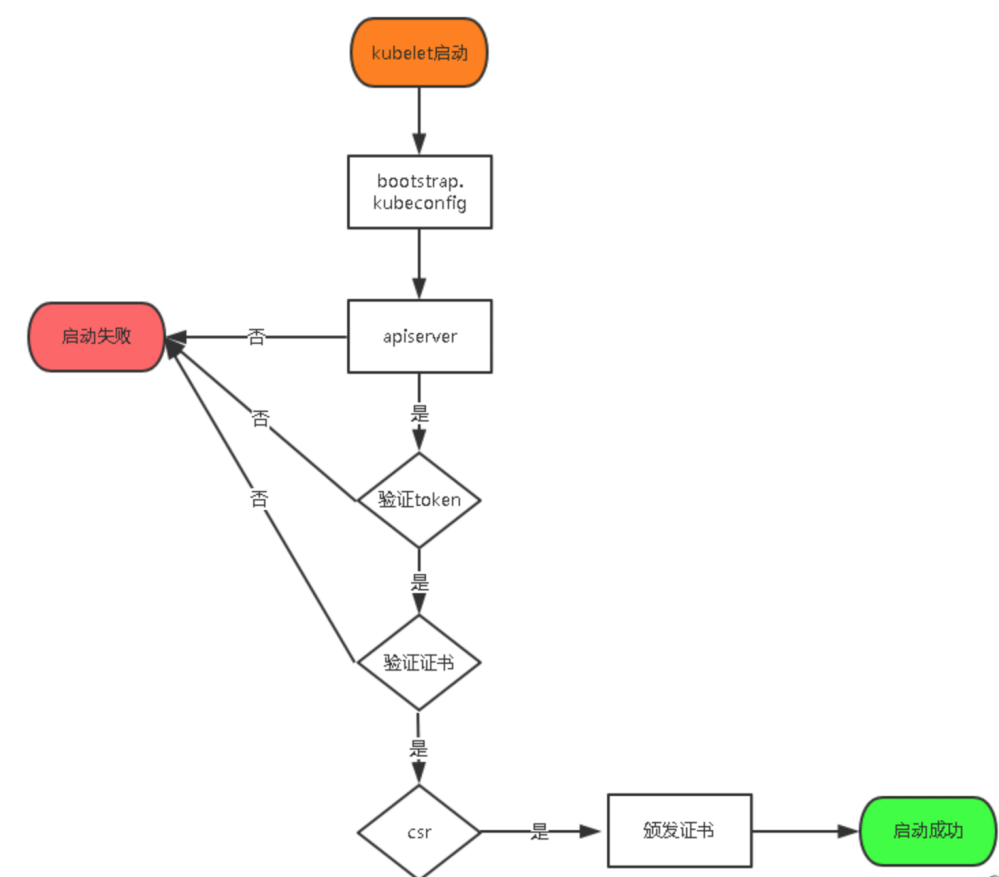
Master apiserver启用TLS认证后,Node节点kubelet组件想要加入集群,必须使用CA签发的有效证书才能与apiserver通信,当Node节点很多时,签署证书是一件很繁琐的事情,因此有了TLS Bootstrapping机制,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。
----------------------下面这些操作在master节点完成:---------------------------
将kubelet-bootstrap用户绑定到系统集群角色
# /opt/kubernetes/bin/kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
创建kubeconfig文件:
在生成kubernetes证书的目录下执行以下命令生成kubeconfig文件:
指定apiserver 内网负载均衡地址
# KUBE_APISERVER="https://10.206.176.19:6443"
# BOOTSTRAP_TOKEN=674c457d4dcf2eefe4920d7dbb6b0ddc
# 设置集群参数
# /opt/kubernetes/bin/kubectl config set-cluster kubernetes \
--certificate-authority=./ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
# 设置客户端认证参数
# /opt/kubernetes/bin/kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=bootstrap.kubeconfig
# 设置上下文参数
# /opt/kubernetes/bin/kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=bootstrap.kubeconfig
# 设置默认上下文
# /opt/kubernetes/bin/kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
#----------------------
# 创建kube-proxy kubeconfig文件
# /opt/kubernetes/bin/kubectl config set-cluster kubernetes \
--certificate-authority=./ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
# /opt/kubernetes/bin/kubectl config set-credentials kube-proxy \
--client-certificate=./kube-proxy.pem \
--client-key=./kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
# /opt/kubernetes/bin/kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
# /opt/kubernetes/bin/kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
# ls
bootstrap.kubeconfig kube-proxy.kubeconfig
将这两个文件拷贝到Node节点/opt/kubernetes/cfg目录下。 !!!!不能忽略
----------------------下面这些操作在所有node节点完成:---------------------------
部署kubelet组件
mkdir /opt/kubernetes/{bin,cfg,ssl} -pv
将前面下载的二进制包中的kubelet和kube-proxy拷贝到/opt/kubernetes/bin目录下。 !!!不能忽略
创建kubelet配置文件:
# vim /opt/kubernetes/cfg/kubelet
KUBELET_OPTS="--logtostderr=true \
--v=4 \
--hostname-override=10.206.240.112 \
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \
--config=/opt/kubernetes/cfg/kubelet.config \
--cert-dir=/opt/kubernetes/ssl \
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0"
参数说明:
* --hostname-override 在集群中显示的主机名
* --kubeconfig 指定kubeconfig文件位置,会自动生成
* --bootstrap-kubeconfig 指定刚才生成的bootstrap.kubeconfig文件
* --cert-dir 颁发证书存放位置
* --pod-infra-container-image 管理Pod网络的镜像
其中/opt/kubernetes/cfg/kubelet.config配置文件如下:
# vim /opt/kubernetes/cfg/kubelet.config
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 10.206.240.112
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS: ["10.0.0.2"]
clusterDomain: cluster.local.
failSwapOn: false
authentication:
anonymous:
enabled: true
webhook:
enabled: false
注释: clusterDns: //不要改,就是这个ip
systemd管理kubelet组件:
# vim /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
After=docker.service
Requires=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet
ExecStart=/opt/kubernetes/bin/kubelet $KUBELET_OPTS
Restart=on-failure
KillMode=process
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kubelet
# systemctl start kubelet
在Master审批Node加入集群:
启动后还没加入到集群中,需要手动允许该节点才可以。
在Master节点查看请求签名的Node:
# /opt/kubernetes/bin/kubectl get csr
# /opt/kubernetes/bin/kubectl certificate approve XXXXID
# /opt/kubernetes/bin/kubectl get node
部署kube-proxy组件
创建kube-proxy配置文件:
# cat /opt/kubernetes/cfg/kube-proxy
KUBE_PROXY_OPTS="--logtostderr=true \
--v=4 \
--hostname-override=10.206.240.111 \
--cluster-cidr=10.0.0.0/24 \
--kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig"
注释: --cluster-cidr //不要改,就是这个ip
systemd管理kube-proxy组件:
# cat /usr/lib/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-proxy
ExecStart=/opt/kubernetes/bin/kube-proxy $KUBE_PROXY_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-proxy
# systemctl start kube-proxy
查看集群状态
# /opt/kubernetes/bin/kubectl get node
NAME STATUS ROLES AGE VERSION
10.206.240.111 Ready <none> 28d v1.11.0
10.206.240.112 Ready <none> 28d v1.11.0
# /opt/kubernetes/bin/kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
运行一个测试示例
创建一个Nginx Web,判断集群是否正常工作:
# /opt/kubernetes/bin/kubectl run nginx --image=nginx --replicas=3
# /opt/kubernetes/bin/kubectl expose deployment nginx --port=88 --target-port=80 --type=NodePort
查看Pod,Service:
# /opt/kubernetes/bin/kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-64f497f8fd-fjgt2 1/1 Running 3 28d
nginx-64f497f8fd-gmstq 1/1 Running 3 28d
nginx-64f497f8fd-q6wk9 1/1 Running 3 28d
查看pod详细信息:
# /opt/kubernetes/bin/kubectl describe pod nginx-64f497f8fd-fjgt2
# /opt/kubernetes/bin/kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 28d
nginx NodePort 10.0.0.175 <none> 88:38696/TCP 28d
打开浏览器输入:http://10.206.240.111:38696
恭喜你,集群部署成功!
---
部署Dashboard (web UI)
部署Dashboard(Web UI)
部署UI有三个文件:
* dashboard-deployment.yaml // 部署Pod,提供Web服务
* dashboard-rbac.yaml // 授权访问apiserver获取信息
* dashboard-service.yaml // 发布服务,提供对外访问
# cat dashboard-deployment.yaml
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: kubernetes-dashboard
containers:
- name: kubernetes-dashboard
image: registry.cn-hangzhou.aliyuncs.com/kube_containers/kubernetes-dashboard-amd64:v1.8.1
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9090
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
# cat dashboard-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
name: kubernetes-dashboard
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
# cat dashboard-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 80
targetPort: 9090
创建:
# /opt/kubernetes/bin/kubectl create -f dashboard-rbac.yaml
# /opt/kubernetes/bin/kubectl create -f dashboard-deployment.yaml
# /opt/kubernetes/bin/kubectl create -f dashboard-service.yaml
等待数分钟,查看资源状态:
# /opt/kubernetes/bin/kubectl get all -n kube-system
NAME READY STATUS RESTARTS AGE
pod/kubernetes-dashboard-68ff5fcd99-5rtv7 1/1 Running 1 27d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes-dashboard NodePort 10.0.0.100 <none> 443:30000/TCP 27d
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/kubernetes-dashboard 1 1 1 1 27d
NAME DESIRED CURRENT READY AGE
replicaset.apps/kubernetes-dashboard-68ff5fcd99 1 1 1 27d
查看访问端口:
# /opt/kubernetes/bin/kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.0.0.100 <none> 443:30000/TCP 27d
打开浏览器,输入:http://10.206.240.111:30000
===============================
其他部署方式dashboard -- 未测试过
# /opt/kubernetes/bin/kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
# /opt/kubernetes/bin/kubectl delete -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
To access Dashboard from your local workstation you must create a secure channel to your Kubernetes cluster. Run the following command:
$ kubectl proxy
Now access Dashboard at:
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/.
kubeadm方式部署Kubernetes
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。
这个工具能通过两条指令完成一个kubernetes集群的部署:
# 创建一个 Master 节点
$ kubeadm init
# 将一个 Node 节点加入到当前集群中
$ kubeadm join <Master节点的IP和端口 >
1. 安装要求
在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统 CentOS7.x-86_x64
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
- 集群中所有机器之间网络互通
- 可以访问外网,需要拉取镜像
- 禁止swap分区
2.学习目标
- 在所有节点上安装Docker和kubeadm
- 部署Kubernetes Master
- 部署容器网络插件
- 部署 Kubernetes Node,将节点加入Kubernetes集群中
- 部署Dashboard Web页面,可视化查看Kubernetes资源
3. 准备环境
Kubernetes 架构图
关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
关闭selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
关闭swap:
$ swapoff -a $ 临时
$ vim /etc/fstab $ 永久
添加主机名与IP对应关系(记得设置主机名):
$ cat /etc/hosts
192.168.31.63 k8s-master
192.168.31.65 k8s-node1
192.168.31.66 k8s-node2
hostnamectl set-hostname hostname
将桥接的IPv4流量传递到iptables的链:
$ cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
$ sysctl --system
4. 所有节点安装Docker/kubeadm/kubelet
Kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker。
4.1 安装Docker
$ wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
$ yum -y install docker-ce-20.10.7-3.el7
$ systemctl enable docker && systemctl start docker
$ docker --version
Docker version 20.10.7, build f0df350
4.2 添加阿里云YUM软件源
$ cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
4.3 安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
$ yum install -y kubelet-1.14.0 kubeadm-1.14.0 kubectl-1.14.0
$ systemctl enable kubelet
5. 部署Kubernetes Master
在192.168.31.63(Master)执行。
$ kubeadm init \
--apiserver-advertise-address=192.168.31.63 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.14.0 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址。
使用kubectl工具:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ kubectl get nodes
6. 安装Pod网络插件(CNI)
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml [1.14]
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml [1.16]
确保能够访问到quay.io这个registery。 master执行
# kubectl get pods -n kube-system
7. 加入Kubernetes Node
在192.168.31.65/66(Node)执行。
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
$ kubeadm join 192.168.31.63:6443 --token l79g5t.6ov4jkddwqki1dxe --discovery-token-ca-cert-hash sha256:4f07f9068c543130461c9db368d62b4aabc22105451057f887defa35f47fa076
8. 测试kubernetes集群
在Kubernetes集群中创建一个pod,验证是否正常运行:
$ kubectl create deployment nginx --image=nginx
$ kubectl expose deployment nginx --port=80 --type=NodePort
$ kubectl get pod,svc
$ kubectl get pod,svc -o wide
访问地址:http://NodeIP:Port
9. 部署 Dashboard
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
镜像下载因为网络的原因:
镜像难以下载,需要修改以下两个地方
image: tigerfive/kubernetes-dashboard-amd64:v1.10.1
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30001
默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30001
selector:
k8s-app: kubernetes-dashboard
$ kubectl apply -f kubernetes-dashboard.yaml
访问地址:https://NodeIP:30001
创建service account并绑定默认cluster-admin管理员集群角色:
$ kubectl create serviceaccount dashboard-admin -n kube-system
$ kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
$ kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
使用输出的token登录Dashboard。
9. 部署 kuboard
部署
kubectl apply -f https://kuboard.cn/install-script/kuboard.yaml
kubectl apply -f https://addons.kuboard.cn/metrics-server/0.3.7/metrics-server.yaml
-----
[如果metric安装后报如下错误]
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get pods.metrics.k8s.io)
则执行下列命令解决
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous
--------
查看运行状态
kubectl get pods -l k8s.kuboard.cn/name=kuboard -n kube-system
输出结果如下所示:
NAME READY STATUS RESTARTS AGE
kuboard-54c9c4f6cb-6lf88 1/1 Running 0 45s
获取访问token
拥有的权限
此Token拥有 ClusterAdmin 的权限,可以执行所有操作
echo $(kubectl -n kube-system get secret $(kubectl -n kube-system get secret | grep kuboard-user | awk '{print $1}') -o go-template='{{.data.token}}' | base64 -d)
只读用户token
拥有的权限
view 可查看名称空间的内容
system:node 可查看节点信息
system:persistent-volume-provisioner 可查看存储类和存储卷声明的信息
适用场景
只读用户不能对集群的配置执行修改操作,非常适用于将开发环境中的 Kuboard 只读权限分发给开发者,以便开发者可以便捷地诊断问题
执行命令
执行如下命令可以获得 只读用户 的 Token
echo $(kubectl -n kube-system get secret $(kubectl -n kube-system get secret | grep kuboard-viewer | awk '{print $1}') -o go-template='{{.data.token}}' | base64 -d)
访问Kuboard
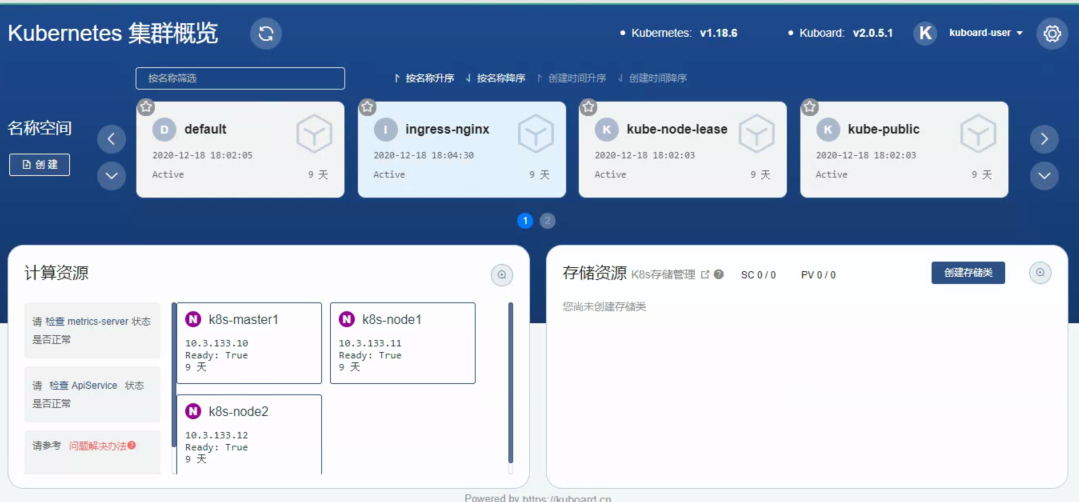
Kuboard Service 使用了 NodePort 的方式暴露服务,NodePort 为 32567;您可以按如下方式访问 Kuboard。
http://任意一个Worker节点的IP地址:32567/
输入前一步骤中获得的 token,可进入 Kuboard 集群概览页
为 kubernetes 集群提供企业级本地镜像仓库
registry库
生产环境下,势必不能够每个机器都导入一遍从海外下载回来的镜像,这方法都不是可以长期使用的。
可以通过搭建本地的私有镜像仓库(docker registry,这个镜像可以在国内直接下载)来解决这个问题。
注:除了第3、4步,其他部署本地仓库的方法和讲docker的时候方法是一样一样的
1、部署docker registry
在master上搭建registry。
1.1 拉取registry镜像
# docker pull docker.io/registry
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/registry latest d1e32b95d8e8 4 weeks ago 33.17 MB
1.2 启动registry
# docker run -d -p 5000:5000 --name=registry --restart=always --privileged=true --log-driver=none -v /home/data/registrydata:/tmp/registry registry
其中,/home/data/registrydata是一个比较大的系统分区,今后镜像仓库中的全部数据都会保存在这个外挂目录下。
里边的 /tmp/registry 在我下载的镜像中对应的是:/var/lib/registry,如果不确定是那个目录,大家最好使用 docker inspect registry查看一下Image相关的信息!
2、更改名称并推送
[root@K8s-node-2 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.access.redhat.com/rhel7/pod-infrastructure latest 34d3450d733b 2 weeks ago 205 MB
gcr.io/google_containers/kubernetes-dashboard-amd64 v1.5.1 1180413103fd 5 weeks ago 103.6 MB
[root@K8s-node-2 ~]# docker tag registry.access.redhat.com/rhel7/pod-infrastructure:latest registry:5000/pod-infrastructure:latest
[root@K8s-node-2 ~]# docker tag gcr.io/google_containers/kubernetes-dashboard-amd64:v1.5.1 registry:5000/kubernetes-dashboard-amd64:v1.5.1
[root@K8s-node-2 ~]# docker push registry:5000/pod-infrastructure:latest
[root@K8s-node-2 ~]# docker push registry:5000/kubernetes-dashboard-amd64:v1.5.1
[root@K8s-node-2 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.access.redhat.com/rhel7/pod-infrastructure latest 34d3450d733b 2 weeks ago 205 MB
registry:5000/pod-infrastructure latest 34d3450d733b 2 weeks ago 205 MB
gcr.io/google_containers/kubernetes-dashboard-amd64 v1.5.1 1180413103fd 5 weeks ago 103.6 MB
registry:5000/kubernetes-dashboard-amd64 v1.5.1 1180413103fd 5 weeks ago 103.6 MB
gcr.io/google_containers/kubedns-amd64 1.7 bec33bc01f03 5 months ago 55.06 MB
3、更改所使用的镜像名称
Dashboard是在yaml中定义的,要更改dashboard.yaml中对应的"image: gcr.io/google_containers/kubernetes-dashboard-amd64:v1.5.1"为"image: registry:5000/kubernetes-dashboard-amd64:v1.5.1"
pod-infrastructure是在node的kubelet配置文件中定义的:
要更改每个node中/etc/kubernetes/kubelet中对应的:
"KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest"
为"KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image= registry:5000/pod-infrastructure:latest ""。
更改之后需要重启kubelet服务。
4、重建dashboard应用
执行完上一节的"销毁应用"之后,再次执行"启动",即可完成dashboard的重建。
查看私有仓库里的所有镜像:
注意我这里是用的是ubuntu的例子
# curl 192.168.245.130:5000/v2/_catalog
{"repositories":["daocloud.io/ubuntu"]}
或者:
# curl http://192.168.245.130:5000/v2/daocloud.io/ubuntu/tags/list
{"name":"daocloud.io/ubuntu","tags":["v2"]}
Harbor仓库
Harbor简史
Harbor是由VMware公司开源的容器镜像仓库, 事实上, Harbor是在Docker Registry上进行了相应的企业级拓展, 从而获得了更加广泛的应用, 这些企业级拓展包括: 管理用户界面、基于角色访问控制、AD/LDAP集成以及审计日志, 足以满足基本企业需求.
Harbor主要功能
\1. 基于角色访问控制
在企业中, 通常有不同的开发团队负责不同的项目, 镜像像代码一样, 每个人角色不同需求也不同, 因此就需要访问权限控制, 根据角色分配相应的权限.
比如: 开发人员需要对项目构建这就用到读写权限(pull/push), 测试人员只需要读权限(pull), 运维一般管理镜像仓库, 具备权限分配能力, 项目经理具备所有权限
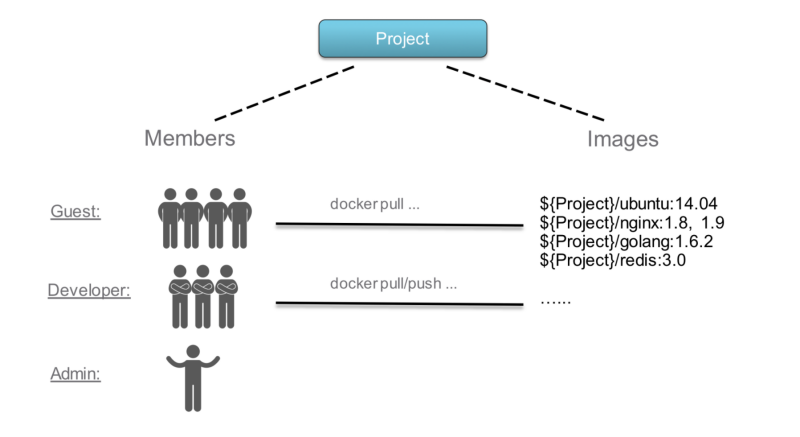
- Guest: 对指定项目只读权限
- Developer: 开发人员, 读写项目权限
- Admin: 项目管理, 所有权限
- Anonymous: 当用户未登陆时,该用户视为匿名, 不能访问私有项目, 只能访问公开项目
2.镜像复制
可以将仓库中的镜像同步到远程Harbor, 类似于MySQL的主从复制功能
3.镜像删除和空间回收
Harbor支持在web界面删除镜像, 回收无用的镜像, 释放磁盘空间
4.审计
对仓库的所有操作都有记录
- REST API
具备完整的API, 方便与外部集成
Harbor高可用方案
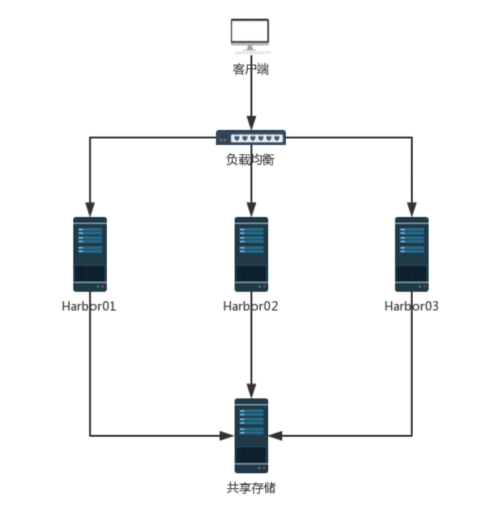
方案一: 共享存储
多个实例共享数据共享一个存储, 任何一个实例持久化存储的镜像, 其他实例都可以读取到, 通过前置负载均衡分发请求
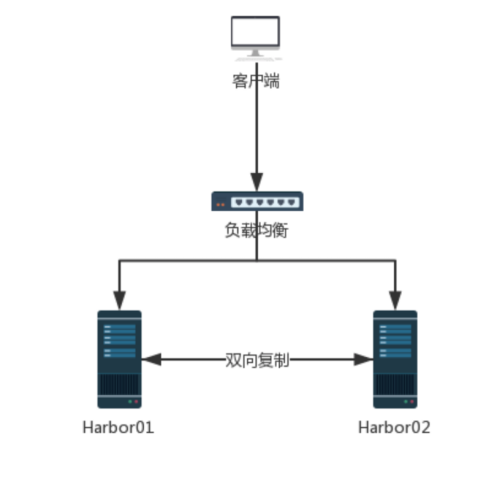
方案二: 复制同步
利用镜像复制功能, 实现双向复制保持数据一致, 通过前置负载均衡分发请求
Harbor组件
组件 功能
harbor-adminserver 配置管理中心
harbor-db MySQL数据库
harbor-jobservice 负责镜像复制
harbor-log 记录操作日志
harbor-UI Web管理页面和API
nginx 前端代理, 负责前端页面和镜像的上传/下载/转发
redis 会话
registry 镜像
Harbor部署
环境准备
192.168.1.175 harbor
192.168.1.205 master
Harbor部署:https方式
下载:https://storage.googleapis.com/harbor-releases/harbor-offline-installer-v1.5.3.tgz
下载此软件包需要翻墙, 请自行安装Google浏览器插件
部署docker
# curl -o /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# yum -y install docker-ce
# curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://bc437cce.m.daocloud.io
部署
GitHub:docker-compose1.22
# curl -L https://github.com/docker/compose/releases/download/1.22.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
# chmod a+x /usr/local/bin/docker-compose
或者
aliyun:docker-compose1.21
# curl -L https://mirrors.aliyun.com/docker-toolbox/linux/compose/1.21.2/docker-compose-Linux-x86_64 -o /usr/local/bin/docker-compose
# chmod a+x /usr/local/bin/docker-compose
自签发TLS证书
# mkdir /ca
# cd /ca
# openssl req \
-newkey rsa:4096 -nodes -sha256 -keyout ca.key \
-x509 -days 365 -out ca.crt
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:BJ
Locality Name (eg, city) [Default City]:BJ
Organization Name (eg, company) [Default Company Ltd]:qianfeng
Organizational Unit Name (eg, section) []:yunjisuan
Common Name (eg, your name or your server's hostname) []:harbor
Email Address []:tiger@qq.com
# openssl req -newkey rsa:4096 -nodes -sha256 -keyout harbor.io.key -out harbor.io.csr
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:BJ
Locality Name (eg, city) [Default City]:BJ
Organization Name (eg, company) [Default Company Ltd]:qianfeng
Organizational Unit Name (eg, section) []:yunjisuan
Common Name (eg, your name or your server's hostname) []:harbor
Email Address []:tiger@qq.com
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:直接回车
An optional company name []:直接回车
# openssl x509 -req -days 365 -in harbor.io.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out harbor.io.crt
部署配置
# tar xf harbor-offline-installer-v1.5.3.tgz
# cd harbor
# vim harbor.cfg //其他的不要改
hostname = harbor.io
ui_url_protocol = https
ssl_cert = /ca/harbor.io.crt
ssl_cert_key = /ca/harbor.io.key
方案二
# vim harbor.cfg //其他的不要改
hostname = 主机域名或IP
customize_crt = false
2.1之后不允许使用不安全模式,配置如下
# vim harbor.yml
hostname: 10.3.131.2
https:
# https port for harbor, default is 443
port: 443
# The path of cert and key files for nginx
certificate: /ca/harbor.io.crt
private_key: /ca/harbor.io.key
harbor_admin_password: Harbor12345
# ./prepare
# ./install.sh //如果重新安装,需要删除/data,删除已经load的docker镜像,然后重启docker
docker主机认证仓库
master:
# mkdir -p /etc/docker/certs.d/harbor.io
harbor:
# scp /ca/ca.crt master:/etc/docker/certs.d/harbor.io/
docker:
# docker login harbor.io
Username: admin
Password:Harbor12345
查看运行状态
# docker-compose ps
看到 harbor-adminserver、harbor-db、harbor-jobservice、harbor-log、harbor-ui、nginx、redis、registry都启动起来了就代表成功了
```
客户端
[20.10.7docker先修改该配置文件,重启测试是否可用,如果不可用,修改下列配置]
# cat /etc/docker/daemon.conf
{
"insecure-registries": ["http://10.3.131.2"]
}
# systemctl daemon-reload
# systemctl restart docker
server端:
[20.10.7docker先修改该配置文件,重启测试是否可用,如果不可用,修改下列配置]
[root@docker1 harbor]# cat /usr/lib/systemd/system/docker.service |grep ExecStart
ExecStart=/usr/bin/dockerd -H fd:// --insecure-registry 10.3.131.2 --containerd=/run/containerd/containerd.sock
# systemctl daemon-reload
# systemctl restart docker
# docker-compose down -v
# docker-compose up -d
# docker-compose ps
客户端测试
# docker login -u admin -p Harbor12345 http://10.3.131.2
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
原因
这是因为docker1.3.2版本开始默认docker registry使用的是https,我们设置Harbor默认http方式,所以当执行用docker login、pull、push等命令操作非https的docker regsitry的时就会报错。
```
更新Harbor配置
docker-compose down -v
vim harbor.cfg ## 修改要更新的配置
./prepare
docker-compose up -d
Harbor使用
上传
1.创建账户
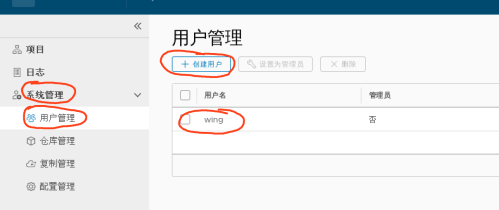
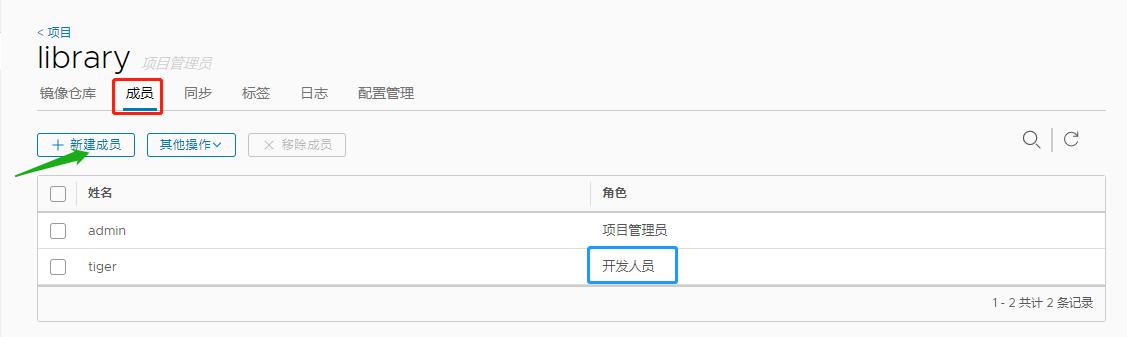
2.在web界面上在项目-->library仓库-->成员-->新建成员 添加开发人员tiger管理, 此时tiger就具备了pull/push权限
3. 在docker主机master中
# docker logout
Removing login credentials for https://index.docker.io/v1/
[root@docker ~]# docker login harbor.io
Username: tiger
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest be1f31be9a87 13 days ago 109MB
tomcat latest 41a54fe1f79d 4 weeks ago 463MB
# docker image tag daocloud.io/library/nginx:latest harbor.io/library/nginx
# docker push harbor.io/library/nginx
The push refers to repository [harbor.io/library/nginx]
92b86b4e7957: Pushed
94ad191a291b: Pushed
8b15606a9e3e: Pushed
latest: digest: sha256:204a9a8e65061b10b92ad361dd6f406248404fe60efd5d6a8f2595f18bb37aad size: 948
在web界面中查看镜像是否被上传到仓库中
下载
# docker login harbor.io
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
# docker pull harbor.io/library/nginx
Using default tag: latest
latest: Pulling from library/nginx
802b00ed6f79: Pull complete
5291925314b3: Pull complete
bd9f53b2c2de: Pull complete
Digest: sha256:204a9a8e65061b10b92ad361dd6f406248404fe60efd5d6a8f2595f18bb37aad
Status: Downloaded newer image for harbor.io/library/nginx:latest
# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
harbor.io/library/nginx latest be1f31be9a87 13 days ago 109MB
定期清理
存储库删除分为两步:
- 第一步: 在web中删除, 这是标记删除, 存储库中还存在
- 第二步: 确保所有人都没有用仓库的情况下, 执行以下指令, 若有人上传/下载镜像可能会出现错误
# docker-compose stop
# docker run -it --name gc --rm --volumes-from registry vmware/registry:2.6.2-photon garbage-collect /etc/registryconfig.yml
# docker-compose start
--------------------------
node配置
# cat /etc/docker/daemon.json
{
"insecure-registries": ["http://10.3.148.212"]
}
# systemctl daemon-reload
# systemctl restart docker
# docker login http://10.3.148.212
在集群中创建保存授权令牌的 Secret
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
kubectl create secret docker-registry tiger-registry \
--docker-server=http://10.3.148.212 \
--docker-username=admin \
--docker-password=Harbor12345 \
--docker-email=goudan@tiger.com
在这里:
<your-registry-server> 是你的私有 Docker 仓库全限定域名(FQDN)。 DockerHub 使用 https://index.docker.io/v1/。
<your-name> 是你的 Docker 用户名。
<your-pword> 是你的 Docker 密码。
<your-email> 是你的 Docker 邮箱。
这样你就成功地将集群中的 Docker 凭证设置为名为 regcred 的 Secret。
创建一个使用你的 Secret 的 Pod
apiVersion: v1
kind: Pod
metadata:
name: private-reg
spec:
containers:
- name: private-reg-container
image: 10.3.148.212/library/nginx:1.20
imagePullSecrets:
- name: tiger-registry
集群信息搜集
在master 查看 node状态:
[root@vm1 etc]# kubectl get nodes
NAME STATUS AGE
192.168.245.251 Ready 17h
192.168.245.252 Ready 17h
删除节点:无效且显示的也可以删除
[root@k8s-master ~]# kubectl delete node 192.168.245.252
node "192.168.245.252" deleted
[root@vm1 etc]# kubectl get node 192.168.245.251
NAME STATUS AGE
192.168.245.251 Ready 17h
注:节点IP可以用空格隔开写多个
使用 kubectl describe 命令,查看一个 API 对象的细节:
注意:Events(事件) 值得你特别关注
在 Kubernetes 执行的过程中,对 API 对象的所有重要操作,都会被记录在这个对象的 Events 里,并且显示在 kubectl describe 指令返回的结果中。
比如,对于这个 Pod,我们可以看到它被创建之后,被调度器调度(Successfully assigned)到了 node-1,拉取了指定的镜像(pulling image),然后启动了 Pod 里定义的容器(Started container)。
这个部分正是我们将来进行 Debug 的重要依据。如果有异常发生,一定要第一时间查看这些 Events,往往可以看到非常详细的错误信息。
[root@vm1 etc]# kubectl describe node 192.168.245.251
#注意:最后被查看的节点名称只能用get nodes里面查到的name!
Name: 192.168.245.251
Role:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=192.168.245.251
Taints: <none>
CreationTimestamp: Tue, 20 Mar 2018 05:25:09 -0400
....
....
查看集群信息:
[root@vm1 etc]# kubectl cluster-info
Kubernetes master is running at http://localhost:8080
查看各组件信息:
未使用安全连接
[root@vm1 etc]# kubectl -s http://localhost:8080 get componentstatuses
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
scheduler Healthy ok
使用安全连接:
[root@master /]# kubectl -s https://192.168.1.205:6443 get componentstatuses
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health": "true"}
查看service的信息:
[root@vm1 etc]# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.254.0.1 <none> 443/TCP 22h
查看所有名称空间内的资源:
# kubectl get pods --all-namespaces
同时查看多种资源信息:
[root@master ~]# kubectl get pod,svc -n kube-system
发布第一个容器化应用
发布第一个容器化应用
扮演一个应用开发者的角色,使用这个 Kubernetes 集群发布第一个容器化应用。
1. 作为一个应用开发者,你首先要做的,是制作容器的镜像。
2. 有了容器镜像之后,需要按照 Kubernetes 项目的规范和要求,将你的镜像组织为它能够"认识"的方式,然后提交上去。
什么才是 Kubernetes 项目能"认识"的方式?
就是使用 Kubernetes 的必备技能:编写配置文件。
这些配置文件可以是 YAML 或者 JSON 格式的。
Kubernetes 跟 Docker 等很多项目最大的不同,就在于它不推荐你使用命令行的方式直接运行容器(虽然 Kubernetes 项目也支持这种方式,比如:kubectl run),而是希望你用 YAML 文件的方式,即:把容器的定义、参数、配置,统统记录在一个 YAML 文件中,然后用这样一句指令把它运行起来:
# kubectl create -f 我的配置文件
# kubectl apply -f 我的配置文件
好处:
你会有一个文件能记录下 Kubernetes 到底"run"了什么。
使用YAML创建Pod
YAML 文件,对应到 k8s 中,就是一个 API Object(API 对象)。当你为这个对象的各个字段填好值并提交给 k8s 之后,k8s 就会负责创建出这些对象所定义的容器或者其他类型的 API 资源。
部署第一个应用
# cat Dockerfile
FROM daocloud.io/library/nginx:1.10
COPY index.html /usr/share/nginx/html
EXPOSE 80
CMD /bin/sh -c 'nginx -g "daemon off;"'
# docker build -t my_nginx:v1 .
把镜像分发到其他工作节点
编写yaml文件内容如下:
---
apiVersion: v1
kind: Pod
metadata:
name: my-nginx
labels:
app: web
spec:
containers:
- name: front-end
image: my_nginx:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
创建Pod:
# kubectl apply -f nginx-pod.yaml
kubectl get po -o wide
验证语法:
当你不确定声明的配置文件是否书写正确时,使用以下命令要验证:
# kubectl create -f ./hello-world.yaml --validate
注:使用--validate只是会告诉你它发现的问题,仍然会按照配置文件的声明来创建资源,除非有严重的错误使创建过程无法继续,如必要的字段缺失或者字段值不合法,不在规定列表内的字段会被忽略。
查看pod状态
通过get命令来查看被创建的pod。
如果执行完创建pod的命令之后,你的速度足够快,那么使用get命令你将会看到以下的状态:
## kubectl get po
NAME READY STATUS RESTARTS AGE
my-nginx 1/1 Running 0 2d17h
cat nginx-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
spec:
type: NodePort
ports:
- port: 88
targetPort: 80
nodePort: 30012
selector:
app: web
kubectl apply -f nginx-svc.yaml
kubectl get svc
kubectl describe svc my-nginx-svc
访问 node—IP:svc-port
---------------
注: Pod创建过程中如果出现错误,可以使用kubectl describe 进行排查。
各字段含义:
NAME: Pod的名称
READY: Pod的准备状况,右边的数字表示Pod包含的容器总数目,左边的数字表示准备就绪的容器数目。
STATUS: Pod的状态。
RESTARTS: Pod的重启次数
AGE: Pod的运行时间。
pod的准备状况指的是Pod是否准备就绪以接收请求,Pod的准备状况取决于容器,即所有容器都准备就绪了,Pod才准备就绪。这时候kubernetes的代理服务才会添加Pod作为分发后端,而一旦Pod的准备状况变为false(至少一个容器的准备状况为false),kubernetes会将Pod从代理服务的分发后端移除,即不会分发请求给该Pod。
一个pod刚被创建的时候是不会被调度的,因为没有任何节点被选择用来运行这个pod。调度的过程发生在创建完成之后,但是这个过程一般很快,所以你通常看不到pod是处于unscheduler状态的除非创建的过程遇到了问题。
pod被调度之后,分配到指定的节点上运行,这时候,如果该节点没有所需要的image,那么将会自动从默认的Docker Hub上pull指定的image,一切就绪之后,看到pod是处于running状态了:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
my-nginx-379829228-2zjv3 1/1 Running 0 1h
my-nginx-379829228-mm8f8 1/1 Running 0 1h
查看pods所在的运行节点:
# kubectl get pods -o wide
查看pods定义的详细信息:
# kubectl get pods -o yaml
# kubectl get pod nginx-8v3cg --output yaml
kubectl get支持以Go Template方式过滤指定的信息,比如查询Pod的运行状态
# kubectl get pods busybox --output=go-template --template={{.status.phase}}
Running
查看pod输出:
你可能会有想了解在pod中执行命令的输出是什么,和Docker logs命令一样,kubectl logs将会显示这些输出:
# kubectl logs pod名称
hello world
查看kubectl describe 支持查询Pod的状态和生命周期事件:
[root@k8s-master ~]# kubectl describe pod busybox
Name: busybox
Namespace: default
Node: k8s-node-1/116.196.105.133
Start Time: Thu, 22 Mar 2018 09:51:35 +0800
Labels: name=busybox
role=master
Status: Pending
IP:
Controllers: <none>
Containers:
busybox:
Container ID:
Image: docker.io/busybox
Image ID:
Port:
Command:
sleep
360000
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Volume Mounts: <none>
Environment Variables: <none>
Conditions:
Type Status
Initialized True
Ready False
PodScheduled True
No volumes.
QoS Class: BestEffort
Tolerations: <none>
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
7m 7m 1 {default-scheduler } Normal Scheduled Successfully assigne
d busybox to k8s-node-1 7m 1m 6 {kubelet k8s-node-1} Warning FailedSync Error syncing pod, s
kipping: failed to "StartContainer" for "POD" with ErrImagePull: "image pull failed for registry.access.redhat.com/rhel7/pod-infrastructure:latest, this may be because there are no credentials on this request. details: (open /etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt: no such file or directory)"
6m 13s 27 {kubelet k8s-node-1} Warning FailedSync Error syncing pod, skipping: failed to "StartContain
er" for "POD" with ImagePullBackOff: "Back-off pulling image \"registry.access.redhat.com/rhel7/pod-infrastructure:latest\""
各字段含义:
Name: Pod的名称
Namespace: Pod的Namespace。
Image(s): Pod使用的镜像
Node: Pod所在的Node。
Start Time: Pod的起始时间
Labels: Pod的Label。
Status: Pod的状态。
Reason: Pod处于当前状态的原因。
Message: Pod处于当前状态的信息。
IP: Pod的PodIP
Replication Controllers: Pod对应的Replication Controller。
Containers:Pod中容器的信息
Container ID: 容器的ID
Image: 容器的镜像
Image ID:镜像的ID
State: 容器的状态
Ready: 容器的准备状况(true表示准备就绪)。
Restart Count: 容器的重启次数统计
Environment Variables: 容器的环境变量
Conditions: Pod的条件,包含Pod准备状况(true表示准备就绪)
Volumes: Pod的数据卷
Events: 与Pod相关的事件列表
进入Pod对应的容器内部
[root@k8s-master /]# kubectl exec -it myweb-76h6w /bin/bash
删除pod:
# kubectl delete pod pod名1 pod名2 //单个或多个删除
# kubectl delete pod --all //批量删除
例:
[root@k8s-master /]# kubectl delete pod hello-world
pod "hello-world" deleted
重新启动基于yaml文件的应用
# kubectl delete -f XXX.yaml
# kubectl apply -f XXX.yaml
部署第一个小Demo
基础环境
系统版本:CentOS Linux release 7.6
kubernetes版本:kubernetes1.14.0
Docker版本: Docker CE 19.03.5
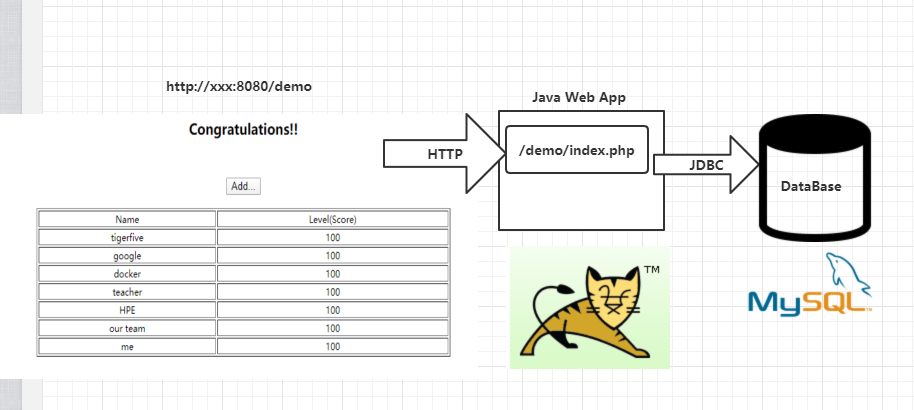
此 Java web项目相对比较简单, 是一个运行在Tomcat里的 Web App, 如下图所示, JSP页面通过 JDBC 直接访问 MySQL 数据库并展示数据。只要正确连接到了数据库,就会自动完成对应的 Table 表的创建与初始化数据的准备工作
启动mysql服务
首先为 MySql 服务创建一个 RC 定义文件 mysql-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: mysql
spec:
replicas: 1
selector:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: daocloud.io/library/mysql:5.7
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
创建好 mysql-rc.yaml 文件后,将他发布到 Kubernetes 集群后,我们在 Master 上执行下列命令:
# kubectl apply -f mysql-rc.yaml
replicationcontroller "mysql" created
查看创建的 RC:
# kubectl get rc
NAME DESIRED CURRENT READY AGE
mysql 1 1 1 103m
查看Pod创建情况
# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-lxt5v 1/1 Running 0 104m
创建 Kubernetes Service - MySql 定义文件 (mysql-svc.yaml)
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
运行 kubectl 命令,创建 Service
kubectl apply -f mysql-svc.yaml
serevice "mysql" created
查看刚刚创建的service
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.1.216.201 <none> 3306/TCP 3h50m
可以看到,MySql 服务分配了一个值为 10.1.216.201 的 Cluster IP的地址。
启动Tomcat应用
# cat myweb-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 2
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: myweb
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVICE_HOST
value: 10.1.216.201
------------
svc-name.namespace.svc.cluster.local
mysql.default.svc.cluster.local
注意: 创建的 myweb-rc.yaml 应注意 MYSQL_SERVICE_HOST 的配置。
# kubectl apply -f myweb-rc.yaml
replicationcontroller "myweb" created
# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-lxt5v 1/1 Running 0 111m
myweb-hs6nw 1/1 Running 0 3h51m
创建对应的 Service
# cat myweb-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
type: NodePort
ports:
- port: 8080
nodePort: 30005
selector:
app: myweb
# kubectl apply -f myweb-svc.yaml
servcice "myweb" created
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.1.216.201 <none> 3306/TCP 3h55m
myweb NodePort 10.1.153.70 <none> 8080:30005/TCP 3h53m
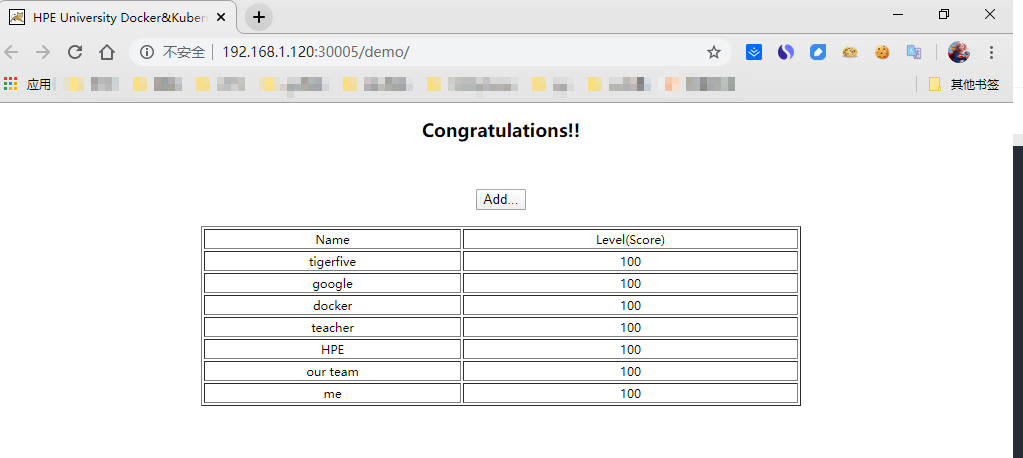
.png)
点击Add 添加提交记录
.png)
完成
yaml配置文件详解
除了某些强制性的命令,如:kubectl run或者expose等,会隐式创建rc或者svc,k8s还允许通过配置文件的方式来创建这些操作对象。
通常,使用配置文件的方式会比直接使用命令行更可取,因为这些文件可以进行版本控制,而且文件的变化和内容也可以进行审核,当使用及其复杂的配置来提供一个稳健、可靠和易维护的系统时,这些点就显得非常重要。
在声明定义配置文件的时候,所有的配置文件都存储在YAML或者JSON格式的文件中并且遵循k8s的资源配置方式。
kubectl可以创建、更新、删除和获得API操作对象,当前apiVersion、kind和name会组成一个API Path以供kubectl来调用。
YAML是专门用来写配置文件的语言,非常简洁和强大,使用比json更方便。它实质上是一种通用的数据串行化格式。
kubernetes中用来定义YAML文件创建Pod和创建Deployment等资源。
使用YAML用于K8s的定义的好处:
便捷性: 不必添加大量的参数到命令行中执行命令
可维护性:YAML文件可以通过源头控制,跟踪每次操作
灵活性: YAML可以创建比命令行更加复杂的结构
YAML语法规则:
1. 大小写敏感
2. 使用缩进表示层级关系
3. 缩进时不允许使用Tab键,只允许使用空格
4. 缩进的空格数不重要,只要相同层级的元素左侧对齐即可
5. "表示注释,从这个字符一直到行尾,都会被解析器忽略
注:在同一个yaml配置文家内可以同时定义多个资源
在 k8s 中,只需要知道两种结构类型:
1.Lists
2.Maps
YAML Maps
Map指的是字典,即一个Key:Value 的键值对信息。
例如:
---
apiVersion: v1
kind: Pod
注:--- 为可选的分隔符 ,当需要在一个文件中定义多个结构的时候需要使用。上述内容表示有两个键apiVersion和kind,分别对应的值为v1和Pod。
Maps的value既能够对应字符串也能够对应一个Maps。
例如:
---
apiVersion: v1
kind: Pod
metadata:
name: kube100-site
labels:
app: web
注:上述的YAML文件中,metadata这个KEY对应的值为一个Maps,而嵌套的labels这个KEY的值又是一个Map。实际使用中可视情况进行多层嵌套。
YAML处理器根据行缩进来知道内容之间的关联。上述例子中,使用两个空格作为缩进,但空格的数据量并不重要,只是至少要求一个空格并且所有缩进保持一致的空格数 。例如,name和labels是相同缩进级别,因此YAML处理器知道他们属于同一map;它知道app是lables的值因为app的缩进更大。
注意:在YAML文件中绝对不要使用tab键
YAML Lists
List即列表,就是数组
例如:
args:
- beijing
- shanghai
- shenzhen
- guangzhou
可以指定任何数量的项在列表中,每个项的定义以连字符(-)开头,并且与父元素之间存在缩进。
在JSON格式中,表示如下:
{
"args": ["beijing", "shanghai", "shenzhen", "guangzhou"]
}
当然Lists的子项也可以是Maps,Maps的子项也可以是List,例如:
---
apiVersion: v1
kind: Pod
metadata:
name: kube100-site
labels:
app: web
spec:
containers:
- name: front-end
image: nginx
ports:
- containerPort: 80
- name: flaskapp-demo
image: jcdemo/flaskapp
ports: 8080
如上述文件所示,定义一个containers的List对象,每个子项都由name、image、ports组成,每个ports都有一个KEY为containerPort的Map组成,转成JSON格式文件:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "kube100-site",
"labels": {
"app": "web"
},
},
"spec": {
"containers": [{
"name": "front-end",
"image": "nginx",
"ports": [{
"containerPort": "80"
}]
}, {
"name": "flaskapp-demo",
"image": "jcdemo/flaskapp",
"ports": [{
"containerPort": "5000"
}]
}]
}
}
k8s的pod中运行容器,一个包含简单的Hello World容器的pod可以通过YAML文件这样来定义:
apiVersion: v1
kind: Pod deployment service
metadata:
name: hello-world
spec: # 当前pod内容的声明
restartPolicy: Never
containers:
- name: hello
image: "ubuntu:14.04"
command: ["/bin/echo","hello","world"]
创建的pod名为metadata.name的值:hello-world,该名称必须是唯一的。
spec的内容为该pod中,各个容器的声明:
restartPolicy:Never表示启动后运行一次就终止这个pod。
containers[0].name为容器的名字。
containers[0].image为该启动该容器的镜像。
containers[0].command相当于Dockerfile中定义的Entrypoint,可以通过下面的方式来声明cmd的参数:
command: ["/bin/echo"]
args: ["hello","world"]
玩转Pod
Pod API属性详解
Pod API 对象
Pod是 k8s 项目中的最小编排单位。将这个设计落实到 API 对象上,容器(Container)就成了 Pod 属性里一个普通的字段。
问题:
到底哪些属性属于 Pod 对象,哪些属性属于 Container?
解决:
Pod 扮演的是传统环境里"虚拟机"的角色。是为了使用户从传统环境(虚拟机环境)向 k8s(容器环境)的迁移,更加平滑。
把 Pod 看成传统环境里的"机器"、把容器看作是运行在这个"机器"里的"用户程序",那么很多关于 Pod 对象的设计就非常容易理解了。
凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的。
共同特征是,它们描述的是"机器"这个整体,而不是里面运行的"程序"。
比如:
配置这个"机器"的网卡(即:Pod 的网络定义)
配置这个"机器"的磁盘(即:Pod 的存储定义)
配置这个"机器"的防火墙(即:Pod 的安全定义)
这台"机器"运行在哪个服务器之上(即:Pod 的调度)
kind:
指定了这个 API 对象的类型(Type),是一个 Pod,根据实际情况,此处资源类型可以是Deployment、Job、Ingress、Service等。
metadata:
包含Pod的一些meta信息,比如名称、namespace、标签等信息。
spec:
specification of the resource content 指定该资源的内容,包括一些container,storage,volume以及其他Kubernetes需要的参数,以及诸如是否在容器失败时重新启动容器的属性。可在特定Kubernetes API找到完整的Kubernetes Pod的属性。
容器可选的设置属性:
除了上述的基本属性外,还能够指定复杂的属性,包括容器启动运行的命令、使用的参数、工作目录以及每次实例化是否拉取新的副本。 还可以指定更深入的信息,例如容器的退出日志的位置。
容器可选的设置属性包括:
name、image、command、args、workingDir、ports、env、resource、volumeMounts、livenessProbe、readinessProbe、livecycle、terminationMessagePath、imagePullPolicy、securityContext、stdin、stdinOnce、tty
跟"机器"相关的配置
nodeSelector:
是一个供用户将 Pod 与 Node 进行绑定的字段,用法:
apiVersion: v1
kind: Pod
...
spec:
nodeSelector:
disktype: ssd
表示这个 Pod 永远只能运行在携带了"disktype: ssd"标签(Label)的节点上;否则,它将调度失败。
NodeName:
一旦 Pod 的这个字段被赋值,k8s就会被认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字。
这个字段一般由调度器负责设置,用户也可以设置它来"骗过"调度器,这个做法一般是在测试或者调试的时候才会用到。
HostAliases:
定义 Pod 的 hosts 文件(比如 /etc/hosts)里的内容,用法:
apiVersion: v1
kind: Pod
...
spec:
hostAliases:
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
...
这里设置了一组 IP 和 hostname 的数据。
此Pod 启动后,/etc/hosts 的内容将如下所示:
# cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
...
10.244.135.10 hostaliases-pod
10.1.2.3 foo.remote
10.1.2.3 bar.remote
注意:在 k8s 中,如果要设置 hosts 文件里的内容,一定要通过这种方法。否则,如果直接修改了 hosts 文件,在 Pod 被删除重建之后,kubelet 会自动覆盖掉被修改的内容。
凡是跟容器的 Linux Namespace 相关的属性,也一定是 Pod 级别的
原因:Pod 的设计,就是要让它里面的容器尽可能多地共享 Linux Namespace,仅保留必要的隔离和限制能力。这样,Pod 模拟出的效果,就跟虚拟机里程序间的关系非常类似了。
举例,一个 Pod 定义 yaml 文件如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
shareProcessNamespace: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
1. 定义了 shareProcessNamespace=true
表示这个 Pod 里的容器要共享 PID Namespace
2. 定义了两个容器:
一个 nginx 容器
一个开启了 tty 和 stdin 的 shell 容器
在 Pod 的 YAML 文件里声明开启它们俩,等同于设置了 docker run 里的 -it(-i 即 stdin,-t 即 tty)参数。
可以直接认为 tty 就是 Linux 给用户提供的一个常驻小程序,用于接收用户的标准输入,返回操作系统的标准输出。为了能够在 tty 中输入信息,需要同时开启 stdin(标准输入流)。
此 Pod 被创建后,就可以使用 shell 容器的 tty 跟这个容器进行交互了。
创建资源并连接到 shell 容器的 tty 上:
# kubectl attach -it nginx -c shell
在 shell 容器里执行 ps 指令,查看所有正在运行的进程:
# kubectl attach -it nginx -c shell
/ # ps ax
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
14 101 0:00 nginx: worker process
15 root 0:00 sh
21 root 0:00 ps ax
在容器里不仅可以看到它本身的 ps ax 指令,还可以看到 nginx 容器的进程,以及 Infra 容器的 /pause 进程。也就是说整个 Pod 里的每个容器的进程,对于所有容器来说都是可见的:它们共享了同一个 PID Namespace。
凡是 Pod 中的容器要共享宿主机的 Namespace,也一定是 Pod 级别的定义
比如:
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: gz2101
spec:
hostNetwork: true
hostIPC: true
hostPID: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
定义了共享宿主机的 Network、IPC 和 PID Namespace。这样,此 Pod 里的所有容器,会直接使用宿主机的网络、直接与宿主机进行 IPC 通信、看到宿主机里正在运行的所有进程。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
容器属性:
Pod 里最重要的字段"Containers":
"Containers"和"Init Containers"这两个字段都属于 Pod 对容器的定义,内容也完全相同,只是 Init Containers 的生命周期,会先于所有的 Containers,并且严格按照定义的顺序执行。
k8s 对 Container 的定义,和 Docker 相比并没有什么太大区别。
Docker中Image(镜像)、Command(启动命令)、workingDir(容器的工作目录)、Ports(容器要开发的端口),以及 volumeMounts(容器要挂载的 Volume)都是构成 k8s 中 Container 的主要字段。
其他的容器属性:
ImagePullPolicy 字段:
定义镜像的拉取策略。之所以是一个 Container 级别的属性,是因为容器镜像本来就是 Container 定义中的一部分。
默认值: Always
表示每次创建 Pod 都重新拉取一次镜像。
当容器的镜像是类似于 nginx 或者 nginx:latest 这样的名字时,ImagePullPolicy 也会被认为 Always。
值:Never 或者 IfNotPresent
表示 Pod 永远不会主动拉取这个镜像,或者只在宿主机上不存在这个镜像时才拉取。
Lifecycle 字段:
定义 Container Lifecycle Hooks。作用是在容器状态发生变化时触发一系列"钩子"。
例子:这是 k8s 官方文档的一个 Pod YAML 文件
在这个例子中,容器成功启动之后,在 /usr/share/message 里写入了一句"欢迎信息"(即 postStart 定义的操作)。而在这个容器被删除之前,我们则先调用了 nginx 的退出指令(即 preStop 定义的操作),从而实现了容器的"优雅退出"。
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
1. 定义了一个 nginx 镜像的容器
2. 设置了一个 postStart 和 preStop 参数
postStart:
是在容器启动后,立刻执行一个指定的操作。
注意:
postStart 定义的操作,虽然是在 Docker 容器 ENTRYPOINT 执行之后,但它并不严格保证顺序。
也就是说,在 postStart 启动时,ENTRYPOINT 有可能还没有结束。
如果 postStart执行超时或者错误,k8s 会在该 Pod 的 Events 中报出该容器启动失败的错误信息,导致 Pod 也处于失败的状态。
preStop:
是容器被杀死之前(比如,收到了 SIGKILL 信号)。
注意:
preStop 操作的执行,是同步的。
所以,它会阻塞当前的容器杀死流程,直到这个 Hook 定义操作完成之后,才允许容器被杀死,这跟 postStart 不一样。
一个Pod 对象在 Kubernetes 中的生命周期
Pod 生命周期的变化,主要体现在 Pod API 对象的Status 部分,这是除了 Metadata 和 Spec 之外的第三个重要字段。其中,pod.status.phase,就是 Pod 的当前状态,有如下几种可能的情况:
Pending:
此状态表示Pod 的 YAML 文件已经提交给了 Kubernetes,API 对象已经被创建并保存在 Etcd 当中。
但这个 Pod 里有些容器因为某种原因而不能被顺利创建。比如,调度不成功。
Running:
此状态表示Pod 已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中。
Succeeded:
此状态表示 Pod 里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。
Failed:
此状态表示 Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。
这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。
Unknown:
这是一个异常状态,表示 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver
这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题。
Pod 对象的 Status 字段,还可以再细分出一组 Conditions:
这些细分状态的值包括:PodScheduled、Ready、Initialized,以及 Unschedulable
它们主要用于描述造成当前 Status 的具体原因是什么。
比如, Pod 当前的 Status 是 Pending,对应的 Condition 是 Unschedulable,这表示它的调度出现了问题。
比如, Ready 这个细分状态表示 Pod 不仅已经正常启动(Running 状态),而且已经可以对外提供服务了。这两者之间(Running 和 Ready)是有区别的,仔细思考一下。
Pod 的这些状态信息,是判断应用运行情况的重要标准,尤其是 Pod 进入了非"Running"状态后,一定要能迅速做出反应,根据它所代表的异常情况开始跟踪和定位,而不是去手忙脚乱地查阅文档。
有基础的可以仔细阅读 $GOPATH/src/k8s.io/kubernetes/vendor/k8s.io/api/core/v1/types.go 里,type Pod struct ,尤其是 PodSpec 部分的内容。
---------
[root@k8s-master ~]# cat nginx.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: kube100-site
labels:
app: web
app1: abc234
spec:
containers:
- name: front-end
image: daocloud.io/library/nginx
ports:
- containerPort: 80
[root@k8s-master ~]# cat nginx_dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx-01
replicas: 2
template:
metadata:
labels:
app: nginx-01
spec:
containers:
- name: nginx-01
image: daocloud.io/library/nginx:latest
ports:
- containerPort: 80
Pod定义详解
YAML格式的Pod定义文件的完整内容如下:
apiVersion: vl
kind: Pod
metadata:
name: string
namespace: string
labels:
- name: string
annotations:
- name: string
spec:
containers:
- name: string
image: string
imagePullPolicy: [Always I Never I IfNotPresent]
command: [string]
args: [string]
workingDir: string
volumeMounts:
- name: string
mountPath:' string
readOnly: boolean
ports:
- name: string
containerPort: int
hostPort: int
protocol: string
env:
- name: string
value: string
resources:
limits:
cpu: string
memory: string
requests:
cpu: string
memory: string
livenessProbe:
exec:
command: [string]
httpGet:
path: string
port: number
host: string
scheme: string
httpHeaders:
- name: string
value: string
tcpSocket:
port: number
initialDelaySeconds: 0
timeoutSeconds: 0
periodSeconds: 0
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always I Never I OnFailure]
nodeSelector: object
imagePullSecrets:
- name: string
hostNetwork: false
volumes:
- name: string
emptyDir: {}
hostPath:
path: string
secret:
secretName: string
items:
- key: string
path: string
configMap:
name: string
items:
- key: string
path: string
对各属性的详细说明如表3.1所示。
表3.1 对Pod定义文件模板中各属性的详细说明


Pod 生命周期和重启策略
Pod 在整个生命周期过程中被系统定义为各种状态,熟悉 Pod 的各种状态对于我们理解如何设置 Pod 的调度策略、重启策略是很有必要的。
Pod 的状态如表所示 。

Pod 的重启策略( RestartPolicy )应用于 Pod 内的所有容器,井且仅在 Pod 所处的 Node 上由 kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时, kubelet 将根据 RestartPolicy 的设置来进行相应的操作 。
Pod 的重启策略包括 Always 、 OnFailure 和 Never , 默认值为 Always 。
- Always : 当容器失效时,由 kubelet 自动重启该容器。
- OnFailure : 当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
- Never : 不论容器运行状态如何, kubelet 都不会重启该容器。
kubelet 重启失效容器的时间间隔以 sync-frequency 乘以 2n 来计算;例如 1、 2 、 4 、 8 倍等,最长延时 5min ,并且在成功重启后的 10min 后重置该时间。
Pod 的 重启策略与控制方式息息相关,当前可用于管理 Pod 的控制器包括ReplicationController 、 Job 、 DaemonSet 及直接通过 kubelet 管理(静态 Pod ) 。每种控制器对 Pod的重启策略要求如下。
RC 和 Daemon Set :必须设置为 Always ,需要保证该容器持续运行。
Job: OnFailure 或 Never ,确保容器执行完成后不再重启。
kubelet : 在 Pod 失效时自动重启它,不论将 RestartPolicy 设置为什么值,也不会对 Pod进行健康检查。
结合 Pod 的状态和重启策略,下表列出一些常见的状态转换场景。
Pod健康检查和服务可用性检查[探针]
对 Pod 的健康状态检查可以通过两类探针来检查: LivenessProbe 和 ReadinessProbe 。kubelet 定期执行这两种探针来诊断容器的健康状况 。
(1) LivenessProbe 探针:用于判断容器是否存活( running 状态),如果 LivenessProbe 探针探测到容器不健康,则 kubelet 将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含 LivenessProbe 探针,那么 kubelet 认为该容器的 LivenessProbe 探针返回的值永远是“ Success"
(2) ReadinessProbe 探针:用于判断容器是否启动完成( ready 状态),可以接收请求。如果 ReadinessProbe 探针检测到失败,则 Pod 的状态将被修改。 系统将从Service 的 Endpoint 中删除包含该容器所在 Pod 的 Endpoint 。 这样就能保证客户端在访问 Service时 在访问 Service 时不会被转发到服务不可用的Pod实例上
LivenessProbe 和 ReadinessProbe 均可配置一下三种实现方式
(1) ExecAction :在容器内部执行一个命令 ,如果该命令的返回码为 0 ,则表明容器健康 。
在下面的例子中,通过执行“ cat /tmp/health ”命令来判断一个容器运行是否正常。而该Pod 运行之后,在创建/tmp/health 文件的 30s 之后将删除该文件,而 LivenessProbe 健康检查的初始探测时间( initialDelaySeconds )为 15s ,探测结果将是 Fail ,将导致 kubelet 杀掉该容器井重启它。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: test-liveness-exec
spec:
containers:
- name: liveness
image: nginx
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 15
periodSeconds: 5
它在启动之后做的第一件事是在 /tmp 目录下创建了一个 healthy 文件,以此作为自己已经正常运行的标志。而 30 s 过后,它会把这个文件删除掉。
与此同时,定义了一个这样的 livenessProbe(健康检查)。它的类型是 exec,它会在容器启动后,在容器里面执行一句我们指定的命令,比如:“cat /tmp/healthy”。这时,如果这个文件存在,这条命令的返回值就是 0,Pod 就会认为这个容器不仅已经启动,而且是健康的。这个健康检查,在容器启动 15 s 后开始执行(initialDelaySeconds: 15),每 5 s 执行一次(periodSeconds: 5)。
创建Pod:
# kubectl create -f test-liveness-exec.yaml
查看 Pod 的状态:
# kubectl get pod
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 0 10s
由于已经通过了健康检查,这个 Pod 就进入了 Running 状态。
30 s 之后,再查看一下 Pod 的 Events:
kubectl describe pod test-liveness-exec
发现,这个 Pod 在 Events 报告了一个异常:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
显然,这个健康检查探查到 /tmp/healthy 已经不存在了,所以它报告容器是不健康的。那么接下来会发生什么呢?
再次查看一下这个 Pod 的状态:
# kubectl get pod test-liveness-exec
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
这时发现,Pod 并没有进入 Failed 状态,而是保持了 Running 状态。这是为什么呢?
RESTARTS 字段从 0 到 1 的变化,就明白原因了:这个异常的容器已经被 Kubernetes 重启了。在这个过程中,Pod 保持 Running 状态不变。
注意:Kubernetes 中并没有 Docker 的 Stop 语义。所以虽然是 Restart(重启),但实际却是重新创建了容器。
这个功能就是 Kubernetes 里的Pod 恢复机制,也叫 restartPolicy。它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。
小提示:
Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。事实上,一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。这也就意味着,如果这个宿主机宕机了,这个 Pod 也不会主动迁移到其他节点上去。
而如果你想让 Pod 出现在其他的可用节点上,就必须使用 Deployment 这样的"控制器"来管理 Pod,哪怕你只需要一个 Pod 副本。这就是一个单 Pod 的 Deployment 与一个 Pod 最主要的区别。
(2) TCPSocketAction :通过容器的 IP 地址和端口号执行 TCP 检查,如果能够建立 TCP 连接,则表明容器健康。 在下面的例子中,通过与容器内的 localhost:80 建立 TCP 连接进行健康检查。
apiVersion: v1
kind: Pod
metadata:
name: pod-with-healthcheck
spec:
containers:
- name: nginx
image: daocloud.io/library/nginx
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 30
timeoutSeconds: 1
(3 )HTTPGetAction : 通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 2 00 且小于 400,则认为容器状态健康。 在下面的例子中, kubelet 定时发送 HTTP 请求到 localho s t:80/ status/healthz 来进行容器应用的健康检查。
apiVersion: v1
kind: Pod
metadata:
name: pod-with-healthcheck
namespace: default
spec:
containers:
- name: pod-with-healthcheck
image: daocloud.io/library/nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
livenessProbe:
httpGet:
port: 80
path: /_status/healthz
initialDelaySeconds: 30
periodSeconds: 3
对于每种探测方式,都需要设置initialDelay Seconds 和 timeoutSeonds 两个参数,它们 的含 义分别如下。 initialDelay Seconds : 启动容器后进行首次健康检查的等待时间 , 单位为 s 。 timeoutSeconds : 健康检查发送请求后等待响应的超时时间,单位为 s 。当超时发生时,kubelet 会认为容器己经无法提供服务,将会重启该容器。
Kubernetes 的 ReadinessProbe 机制可能无法满足某些复杂应用对容器内服务的可用状态判断,所以 Kubernets 从 1.11 版本开始,引入 Pod Ready++ 特性对 Readiness 探针机制扩充。在1.14版本时达到稳定,称其为 Pod Readiness Gates。
投射数据卷 Projected Volume
注:Projected Volume 是 Kubernetes v1.11 之后的新特性
什么是Projected Volume?
在 k8s 中,有几种特殊的 Volume,它们的意义不是为了存放容器里的数据,也不是用来进行容器和宿主机之间的数据交换。
而是为容器提供预先定义好的数据。
从容器的角度来看,这些 Volume 里的信息仿佛是被 k8s “投射”(Project)进入容器当中的。
k8s 支持的 Projected Volume 一共有四种:
Secret
ConfigMap
Downward API
ServiceAccountToken
Secret 详解
secret
secret用来保存小片敏感数据的k8s资源,例如密码,token,或者秘钥。这类数据当然也可以存放在Pod或者镜像中,但是放在Secret中是为了更方便的控制如何使用数据,并减少暴露的风险。
用户可以创建自己的secret,系统也会有自己的secret。
Pod需要先引用才能使用某个secret
Pod有2种方式来使用secret:
1. 作为volume的一个域被一个或多个容器挂载
2. 在拉取镜像的时候被kubelet引用。
內建的Secrets:
由ServiceAccount创建的API证书附加的秘钥
k8s自动生成的用来访问apiserver的Secret,所有Pod会默认使用这个Secret与apiserver通信
创建自己的Secret:
方式1:使用kubectl create secret命令
方式2:yaml文件创建Secret
命令方式创建secret:
假如某个Pod要访问数据库,需要用户名密码,分别存放在2个文件中:username.txt,password.txt
例子:
# echo -n 'admin' > ./username.txt
# echo -n '1f2d1e2e67df' > ./password.txt
kubectl create secret指令将用户名密码写到secret中,并在apiserver创建Secret
# kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
secret "db-user-pass" created
查看创建结果:
# kubectl get secrets
NAME TYPE DATA AGE
db-user-pass Opaque 2 51s
注:
opaque:英[əʊˈpeɪk] 美[oʊˈpeɪk] 模糊
# kubectl describe secrets/db-user-pass
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password.txt: 12 bytes
username.txt: 5 bytes
get或describe指令都不会展示secret的实际内容,这是出于对数据的保护的考虑,如果想查看实际内容使用命令:
# kubectl get secret db-user-pass -o json
yaml方式创建Secret:
创建一个secret.yaml文件,内容用base64编码
# echo -n 'admin' | base64
YWRtaW4=
# echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm
yaml文件内容:
# vim secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
创建:
# kubectl create -f ./secret.yaml
secret "mysecret" created
解析Secret中内容
# kubectl get secret mysecret -o yaml
apiVersion: v1
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
kind: Secret
metadata:
creationTimestamp: 2016-01-22T18:41:56Z
name: mysecret
namespace: default
resourceVersion: "164619"
selfLink: /api/v1/namespaces/default/secrets/mysecret
uid: cfee02d6-c137-11e5-8d73-42010af00002
type: Opaque
#base64解码:
# echo 'MWYyZDFlMmU2N2Rm' | base64 --decode
1f2d1e2e67df
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
使用Secret
secret可以作为数据卷挂载或者作为环境变量暴露给Pod中的容器使用,也可以被系统中的其他资源使用。比如可以用secret导入与外部系统交互需要的证书文件等。
在Pod中以文件的形式使用secret
创建一个Secret,多个Pod可以引用同一个Secret
修改Pod的定义,在spec.volumes[]加一个volume,给这个volume起个名字,spec.volumes[].secret.secretName记录的是要引用的Secret名字
在每个需要使用Secret的容器中添加一项spec.containers[].volumeMounts[],指定spec.containers[].volumeMounts[].readOnly = true,spec.containers[].volumeMounts[].mountPath要指向一个未被使用的系统路径。
修改镜像或者命令行使系统可以找到上一步指定的路径。此时Secret中data字段的每一个key都是指定路径下面的一个文件名
一个Pod中引用Secret的列子:
# vim pod_use_secret.yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
每一个被引用的Secret都要在spec.volumes中定义
如果Pod中的多个容器都要引用这个Secret那么每一个容器定义中都要指定自己的volumeMounts,但是Pod定义中声明一次spec.volumes就好了。
映射secret key到指定的路径
可以控制secret key被映射到容器内的路径,利用spec.volumes[].secret.items来修改被映射的具体路径
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
发生了什么呢?
username被映射到了文件/etc/foo/my-group/my-username而不是/etc/foo/username
而password没有被使用,这种方式每个key的调用需要单独用key像username一样调用
Secret文件权限
可以指定secret文件的权限,类似linux系统文件权限,如果不指定默认权限是0644,等同于linux文件的-rw-r--r--权限
设置默认权限位
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
defaultMode: 256
上述文件表示将secret挂载到容器的/etc/foo路径,每一个key衍生出的文件,权限位都将是0400
这里用十进制数256表示0400,可以使用八进制0400
同理可以单独指定某个key的权限
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
mode: 511
从volume中读取secret的值
以文件的形式挂载到容器中的secret,他们的值已经是经过base64解码的了,可以直接读出来使用。
# ls /etc/foo/
username
password
# cat /etc/foo/username
admin
# cat /etc/foo/password
1f2d1e2e67df
被挂载的secret内容自动更新
也就是如果修改一个Secret的内容,那么挂载了该Secret的容器中也将会取到更新后的值,但是这个时间间隔是由kubelet的同步时间决定的。最长的时间将是一个同步周期加上缓存生命周期(period+ttl)
特例:以subPath(https://kubernetes.io/docs/concepts/storage/volumes/#using-subpath)形式挂载到容器中的secret将不会自动更新
以环境变量的形式使用Secret
创建一个Secret,多个Pod可以引用同一个Secret
修改pod的定义,定义环境变量并使用env[].valueFrom.secretKeyRef指定secret和相应的key
修改镜像或命令行,让它们可以读到环境变量
apiVersion: v1
kind: Pod
metadata:
name: secret-env-pod
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
restartPolicy: Never
容器中读取环境变量,已经是base64解码后的值了:
# echo $SECRET_USERNAME
admin
# echo $SECRET_PASSWORD
1f2d1e2e67df
使用imagePullSecrets
创建一个专门用来访问镜像仓库的secret,当创建Pod的时候由kubelet访问镜像仓库并拉取镜像,具体描述文档在 这里
设置自动导入的imagePullSecrets
可以手动创建一个,然后在serviceAccount中引用它。所有经过这个serviceAccount创建的Pod都会默认使用关联的imagePullSecrets来拉取镜像,参考文档
自动挂载手动创建的Secret
参考文档:https://kubernetes.io/docs/tasks/inject-data-application/podpreset/
限制
需要被挂载到Pod中的secret需要提前创建,否则会导致Pod创建失败
secret是有命名空间属性的,只有在相同namespace的Pod才能引用它
单个Secret容量限制的1Mb,这么做是为了防止创建超大的Secret导致apiserver或kubelet的内存耗尽。但是创建过多的小容量secret同样也会耗尽内存,这个问题在将来可能会有方案解决
kubelet只支持由API server创建出来的Pod中引用secret,使用特殊方式创建出来的Pod是不支持引用secret的,比如通过kubelet的--manifest-url参数创建的pod,或者--config参数创建的,或者REST API创建的。
通过secretKeyRef引用一个不存在你secret key会导致pod创建失败
用例
Pod中的ssh keys
创建一个包含ssh keys的secret
kubectl create secret generic ssh-key-secret --from-file=ssh-privatekey=/path/to/.ssh/id_rsa --from-file=ssh-publickey=/path/to/.ssh/id_rsa.pub
创建一个Pod,其中的容器可以用volume的形式使用ssh keys
kind: Pod
apiVersion: v1
metadata:
name: secret-test-pod
labels:
name: secret-test
spec:
volumes:
- name: secret-volume
secret:
secretName: ssh-key-secret
containers:
- name: ssh-test-container
image: mySshImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
Pod中区分生产和测试证书
创建2种不同的证书,分别用在生产和测试环境
# kubectl create secret generic prod-db-secret --from-literal=username=produser --from-literal=password=Y4nys7f11
secret "prod-db-secret" created
# kubectl create secret generic test-db-secret --from-literal=username=testuser --from-literal=password=iluvtests
secret "test-db-secret" created
再创建2个不同的Pod
apiVersion: v1
kind: List
items:
- kind: Pod
apiVersion: v1
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: prod-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
- kind: Pod
apiVersion: v1
metadata:
name: test-db-client-pod
labels:
name: test-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: test-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
两个容器中都会有下列的文件
/etc/secret-volume/username
/etc/secret-volume/password
以“.”开头的key可以产生隐藏文件
kind: Secret
apiVersion: v1
metadata:
name: dotfile-secret
data:
.secret-file: dmFsdWUtMg0KDQo=
---
kind: Pod
apiVersion: v1
metadata:
name: secret-dotfiles-pod
spec:
volumes:
- name: secret-volume
secret:
secretName: dotfile-secret
containers:
- name: dotfile-test-container
image: k8s.gcr.io/busybox
command:
- ls
- "-l"
- "/etc/secret-volume"
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
会在挂载目录下产生一个隐藏文件,/etc/secret-volume/.secret-file
Secret实验
Secret:
作用是帮你把 Pod 想要访问的加密数据,存放到 Etcd 中。然后,就可以通过在 Pod 的容器里挂载 Volume 的方式,访问到这些 Secret 里保存的信息了。
Secret 典型的使用场景:
存放数据库的 Credential 信息
例子:
# cat test-projected-volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-secret-volume
image: busybox
args:
- sleep
- "86400"
volumeMounts:
- name: mysql-cred
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: mysql-cred
projected:
sources:
- secret:
name: user
- secret:
name: pass
定义了一个容器,它声明挂载的 Volume是 projected 类型 , 并不是常见的 emptyDir 或者 hostPath 类型,
而这个 Volume 的数据来源(sources),则是名为 user 和 pass 的 Secret 对象,分别对应的是数据库的用户名和密码。
这里用到的数据库的用户名、密码,正是以 Secret 对象的方式交给 Kubernetes 保存的。
方法1. 使用 kubectl create secret 指令创建Secret对象
# cat ./username.txt
admin
# cat ./password.txt
c1oudc0w!
# kubectl create secret generic user --from-file=./username.txt
# kubectl create secret generic pass --from-file=./password.txt
username.txt 和 password.txt 文件里,存放的就是用户名和密码;而 user 和 pass,则是为 Secret 对象指定的名字。
查看Secret 对象:
# kubectl get secrets
NAME TYPE DATA AGE
user Opaque 1 51s
pass Opaque 1 51s
方法2. 通过编写 YAML 文件的方式来创建这个 Secret 对象
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
user: YWRtaW4=
pass: MWYyZDFlMmU2N2Rm
Secret 对象要求这些数据必须是经过 Base64 转码的,以免出现明文密码的安全隐患。
转码操作:
# echo -n 'admin' | base64
YWRtaW4=
# echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm
注意:像这样创建的 Secret 对象,它里面的内容仅仅是经过了转码,并没有被加密。生产环境中,需要在 Kubernetes 中开启 Secret 的加密插件,增强数据的安全性。
用yaml方式创建的secret调用方法如下:
# cat test-projected-volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume1
spec:
containers:
- name: test-secret-volume1
image: busybox
args:
- sleep
- "86400"
volumeMounts:
- name: mysql-cred
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: mysql-cred
secret:
secretName: mysecret
创建这个 Pod:
# kubectl create -f test-projected-volume.yaml
验证这些 Secret 对象是不是已经在容器里了:
# kubectl exec -it test-projected-volume -- /bin/sh
注意:
报错:上面这条命令会报错如下
# kubectl exec -it test-projected-volume /bin/sh
error: unable to upgrade connection: Forbidden (user=system:anonymous, verb=create, resource=nodes, subresource=proxy)
解决:绑定一个cluster-admin的权限
# kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous
clusterrolebinding.rbac.authorization.k8s.io/system:anonymous created
/ # ls /projected-volume/
user
pass
/ # cat /projected-volume/user
root
/ # cat /projected-volume/pass
1f2d1e2e67df
结果中看到,保存在 Etcd 里的用户名和密码信息,已经以文件的形式出现在了容器的 Volume 目录里。
而这个文件的名字,就是 kubectl create secret 指定的 Key,或者说是 Secret 对象的 data 字段指定的 Key。
同步更新:
通过挂载方式进入到容器里的 Secret,一旦其对应的 Etcd 里的数据被更新,这些 Volume 里的文件内容,同样也会被更新,kubelet 组件在定时维护这些 Volume。
1. 生成新的密码数据:
# echo -n '111111' | base64
MTExMTEx
2 . 修改数据:
# cat mysecret.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
user: YWRtaW4=
pass: MTExMTEx
3. 更新数据:
# kubectl apply -f mysecret.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
secret/mysecret configured
4. 查看对应pod里的数据是否更新:
# kubectl exec -it test-projected-volume1 /bin/sh
/ # cat projected-volume/pass
111111/ #
注:这个更新可能会有一定的延时。所以在编写应用程序时,在发起数据库连接的代码处写好重试和超时的逻辑,绝对是个好习惯。
查看secret具体的值:
# kubectl get secret mysecret -o json
{
"apiVersion": "v1",
"data": {
"pass": "MTExMTEx",
"user": "YWRtaW4="
},
"kind": "Secret",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"v1\",\"data\":{\"pass\":\"MTExMTEx\",\"user\":\"YWRtaW4=\"},\"kind\":\"Secret\",\"metadata\":{\"annotations\":{},\"name\":\"mysecret\",\"namespace\":\"default\"},\"type\":\"Opaque\"}\n"
},
"creationTimestamp": "2019-01-21T07:31:05Z",
"name": "mysecret",
"namespace": "default",
"resourceVersion": "125857",
"selfLink": "/api/v1/namespaces/default/secrets/mysecret",
"uid": "82e20780-1d4e-11e9-baa8-000c29f01606"
},
"type": "Opaque"
}
ConfigMap详解
ConfigMap祥解
ConfigMap与 Secret 类似,用来存储配置文件的kubernetes资源对象,所有的配置内容都存储在etcd中。
与 Secret 的区别:
ConfigMap 保存的是不需要加密的、应用所需的配置信息。
ConfigMap 的用法几乎与 Secret 完全相同:可以使用 kubectl create configmap 从文件或者目录创建 ConfigMap,也可以直接编写 ConfigMap 对象的 YAML 文件。
创建ConfigMap
1. 创建ConfigMap
创建ConfigMap的方式有4种:
方式1:通过直接在命令行中指定configmap参数创建,即--from-literal
方式2:通过指定文件创建,即将一个配置文件创建为一个ConfigMap,--from-file=<文件>
方式3:通过指定目录创建,即将一个目录下的所有配置文件创建为一个ConfigMap,--from-file=<目录>
方式4:事先写好标准的configmap的yaml文件,然后kubectl create -f 创建
1.1 通过命令行参数--from-literal创建
创建命令:
[root@master yaml]# kubectl create configmap test-config1 --from-literal=db.host=10.5.10.116 --from-literal=db.port='3306'
configmap/test-config1 created
结果如下面的data内容所示:
[root@master yaml]# kubectl get configmap test-config1 -o yaml
apiVersion: v1
data:
db.host: 10.5.10.116
db.port: "3306"
kind: ConfigMap
metadata:
creationTimestamp: "2019-02-14T08:22:34Z"
name: test-config1
namespace: default
resourceVersion: "7587"
selfLink: /api/v1/namespaces/default/configmaps/test-config1
uid: adfff64c-3031-11e9-abbe-000c290a5b8b
1.2 通过指定文件创建
编辑配置文件app.properties内容如下:
[root@master yaml]# cat app.properties
property.1 = value-1
property.2 = value-2
property.3 = value-3
property.4 = value-4
[mysqld]
!include /home/tiger/mysql/etc/mysqld.cnf
port = 3306
socket = /home/tiger/mysql/tmp/mysql.sock
pid-file = /tiger/mysql/mysql/var/mysql.pid
basedir = /home/mysql/mysql
datadir = /tiger/mysql/mysql/var
创建(可以有多个--from-file):
# kubectl create configmap test-config2 --from-file=./app.properties
结果如下面data内容所示:
[root@master yaml]# kubectl get configmap test-config2 -o yaml
apiVersion: v1
data:
app.properties: |
property.1 = value-1
property.2 = value-2
property.3 = value-3
property.4 = value-4
[mysqld]
!include /home/tiger/mysql/etc/mysqld.cnf
port = 3306
socket = /home/tiger/mysql/tmp/mysql.sock
pid-file = /tiger/mysql/mysql/var/mysql.pid
basedir = /home/mysql/mysql
datadir = /tiger/mysql/mysql/var
kind: ConfigMap
metadata:
creationTimestamp: "2019-02-14T08:29:33Z"
name: test-config2
namespace: default
resourceVersion: "8176"
selfLink: /api/v1/namespaces/default/configmaps/test-config2
uid: a8237769-3032-11e9-abbe-000c290a5b8b
通过指定文件创建时,configmap会创建一个key/value对,key是文件名,value是文件内容。
如不想configmap中的key为默认的文件名,可以在创建时指定key名字:
# kubectl create configmap game-config-3 --from-file=<my-key-name>=<path-to-file>
1.3 指定目录创建
configs 目录下的config-1和config-2内容如下所示:
[root@master yaml]# tail configs/config-1
aaa
bbb
c=d
[root@master yaml]# tail configs/config-2
eee
fff
h=k
创建:
# kubectl create configmap test-config3 --from-file=./configs
结果下面data内容所示:
[root@master yaml]# kubectl get configmap test-config3 -o yaml
apiVersion: v1
data:
config-1: |
aaa
bbb
c=d
config-2: |
eee
fff
h=k
kind: ConfigMap
metadata:
creationTimestamp: "2019-02-14T08:37:05Z"
name: test-config3
namespace: default
resourceVersion: "8808"
selfLink: /api/v1/namespaces/default/configmaps/test-config3
uid: b55ffbeb-3033-11e9-abbe-000c290a5b8b
指定目录创建时,configmap内容中的各个文件会创建一个key/value对,key是文件名,value是文件内容。
假如目录中还包含子目录:
在上一步的configs目录下创建子目录subconfigs,并在subconfigs下面创建两个配置文件,指定目录configs创建名为test-config4的configmap:
# kubectl create configmap test-config4 --from-file=./configs
结果发现和上面没有子目录时一样,说明指定目录时只会识别其中的文件,忽略子目录
1.4 通过事先写好configmap的标准yaml文件创建
yaml文件内容如下: 注意其中一个key的value有多行内容时的写法
[root@master yaml]# cat configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: test-config4
namespace: default
data:
cache_host: memcached-gcxt
cache_port: "11211"
cache_prefix: gcxt
my.cnf: |
[mysqld]
log-bin = mysql-bin
haha = hehe
创建:
[root@master yaml]# kubectl apply -f configmap.yaml
configmap/test-config4 created
结果如下面data内容所示:
[root@master yaml]# kubectl get configmap test-config4 -o yaml
apiVersion: v1
data:
cache_host: memcached-gcxt
cache_port: "11211"
cache_prefix: gcxt
my.cnf: |
[mysqld]
log-bin = mysql-bin
haha = hehe
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"cache_host":"memcached-gcxt","cache_port":"11211","cache_prefix":"gcxt","my.cnf":"[mysqld]\nlog-bin = mysql-bin\nhaha = hehe\n"},"kind":"ConfigMap","metadata":{"annotations":{},"name":"test-config4","namespace":"default"}}
creationTimestamp: "2019-02-14T08:46:57Z"
name: test-config4
namespace: default
resourceVersion: "9639"
selfLink: /api/v1/namespaces/default/configmaps/test-config4
uid: 163fbe1e-3035-11e9-abbe-000c290a5b8b
查看configmap的详细信息:
# kubectl describe configmap
使用ConfigMap
2. 使用ConfigMap
使用ConfigMap有三种方式,一种是通过环境变量的方式,直接传递pod,另一种是通过在pod的命令行下运行的方式,第三种是使用volume的方式挂载入到pod内
示例ConfigMap文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm
2.1 通过环境变量使用
(1) 使用valueFrom、configMapKeyRef、name、key指定要用的key:
[root@master yaml]# cat testpod.yaml
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: daocloud.io/library/nginx
env:
- name: SPECIAL_LEVEL_KEY //这里是容器里设置的新变量的名字
valueFrom:
configMapKeyRef:
name: special-config //这里是来源于哪个configMap
key: special.how //configMap里的key
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.type
restartPolicy: Never
测试:
[root@master yaml]# kubectl exec -it dapi-test-pod /bin/bash
root@dapi-test-pod:/# echo $SPECIAL_TYPE_KEY
charm
(2) 通过envFrom、configMapRef、name使得configmap中的所有key/value对都自动变成环境变量:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: daocloud.io/library/nginx
envFrom:
- configMapRef:
name: special-config
restartPolicy: Never
这样容器里的变量名称直接使用configMap里的key名:
[root@master yaml]# kubectl exec -it dapi-test-pod -- /bin/bash
root@dapi-test-pod:/# env
HOSTNAME=dapi-test-pod
NJS_VERSION=1.15.8.0.2.7-1~stretch
NGINX_VERSION=1.15.8-1~stretch
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
KUBERNETES_PORT=tcp://10.96.0.1:443
PWD=/
special.how=very
HOME=/root
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT_443_TCP_PORT=443
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
TERM=xterm
SHLVL=1
KUBERNETES_SERVICE_PORT=443
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
special.type=charm
KUBERNETES_SERVICE_HOST=10.96.0.1
2.2 在启动命令中引用
在命令行下引用时,需要先设置为环境变量,之后可以通过$(VAR_NAME)设置容器启动命令的启动参数:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: busybox
command: [ "/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.type
restartPolicy: Never
2.3 作为volume挂载使用
(1) 把1.4中test-config4所有key/value挂载进来:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-configmap
spec:
replicas: 1
selector:
matchLabels:
app: nginx-configmap
template:
metadata:
labels:
app: nginx-configmap
spec:
containers:
- name: nginx-configmap
image: daocloud.io/library/nginx
ports:
- containerPort: 80
volumeMounts:
- name: config-volume4
mountPath: /tmp/config4
volumes:
- name: config-volume4
configMap:
name: test-config4
进入容器中/tmp/config4查看:
[root@master yaml]# kubectl exec -it nginx-configmap-7447bf77d6-svj2t /bin/bash
root@nginx-configmap-7447bf77d6-svj2t:/# ls /tmp/config4/
cache_host cache_port cache_prefix my.cnf
root@nginx-configmap-7447bf77d6-svj2t:/# cat /tmp/config4/cache_host
memcached-gcxt
可以看到,在config4文件夹下以每一个key为文件名value为值创建了多个文件。
(2) 假如不想以key名作为配置文件名可以引入items 字段,在其中逐个指定要用相对路径path替换的key:
volumes:
- name: config-volume4
configMap:
name: test-config4
items:
- key: my.cnf //原来的key名
path: mysql-key
- key: cache_host //原来的key名
path: cache-host
备注:
删除configmap后原pod不受影响;然后再删除pod后,重启的pod的events会报找不到cofigmap的volume;
pod起来后再通过kubectl edit configmap …修改configmap,过一会pod内部的配置也会刷新。
在容器内部修改挂进去的配置文件后,过一会内容会再次被刷新为原始configmap内容
(3) 还可以为以configmap挂载进的volume添加subPath字段:
volumeMounts:
- name: config-volume5
mountPath: /tmp/my
subPath: my.cnf
- name: config-volume5
mountPath: /tmp/host
subPath: cache_host
- name: config-volume5
mountPath: /tmp/port
subPath: cache_port
- name: config-volume5
mountPath: /tmp/prefix
subPath: cache_prefix
volumes:
- name: config-volume5
configMap:
name: test-config4
mountPath结合subPath(也可解决多个configmap挂载同一目录,导致覆盖)作用
有subPath时且subPath推荐筛选结果为true,mountPath指定到文件名
vim test-config11
apiVersion: v1
kind: ConfigMap
metadata:
name: test-config11
namespace: default
data:
host: 10.5.10.116
password: root
user: root
apiVersion: v1
kind: Pod
metadata:
name: nginx-config11
labels:
app: nginx-configmap
spec:
containers:
- name: nginx-configmap2
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: config-volume4
mountPath: "/tmp/config4/host"
subPath: host
volumes:
- name: config-volume4
configMap:
name: test-config11
items:
- key: host
path: host
- key: user
path: path/user
# kubectl apply -f configmap7.yml
pod/nginx-config11 created
# kubectl exec -it nginx-config11 -- ls /tmp/config4
host
# kubectl exec -it nginx-config11 -- cat /tmp/config4/host
10.5.10.116
有subPath时且subPath推荐筛选结果为true,mountPath指定到文件名,仅挂载host,其它key不挂载
注意在容器中的形式与(2)中的不同,(2)中是个链接,链到..data/<key-name>。
备注:
删除configmap后原pod不受影响;然后再删除pod后,重启的pod的events会报找不到cofigmap的volume。
pod起来后再通过kubectl edit configmap …修改configmap,pod内部的配置也会自动刷新。
在容器内部修改挂进去的配置文件后,内容可以持久保存,除非杀掉再重启pod才会刷回原始configmap的内容。
subPath必须要与configmap中的key同名。
mountPath如/tmp/prefix:
<1>当/tmp/prefix不存在时(备注:此时/tmp/prefix和/tmp/prefix/无异),会自动创建prefix文件并把value写进去;
<2>当/tmp/prefix存在且是个文件时,里面内容会被configmap覆盖;
<3>当/tmp/prefix存在且是文件夹时,无论写/tmp/prefix还是/tmp/prefix/都会报错。
3.configmap的热更新
更新 ConfigMap 后:
使用该 ConfigMap 挂载的 Env 不会同步更新
使用该 ConfigMap 挂载的 Volume 中的数据需要一段时间(实测大概10秒)才能同步更新
ENV 是在容器启动的时候注入的,启动之后 kubernetes 就不会再改变环境变量的值,且同一个 namespace 中的 pod 的环境变量是不断累加的,参考 Kubernetes中的服务发现与docker容器间的环境变量传递源码探究。为了更新容器中使用 ConfigMap 挂载的配置,可以通过滚动更新 pod 的方式来强制重新挂载 ConfigMap,也可以在更新了 ConfigMap 后,先将副本数设置为 0,然后再扩容。
Downward API
Downward API
用于在容器中获取 POD 的基本信息,kubernetes原生支持
Downward API提供了两种方式用于将 POD 的信息注入到容器内部:
环境变量:
用于单个变量,可以将 POD 信息和容器信息直接注入容器内部。
Volume挂载:
将 POD 信息生成为文件,直接挂载到容器内部中去。
环境变量的方式:
将Pod信息注入为环境变量
通过Downward API来将 POD 的 IP、名称以及所对应的 namespace 注入到容器的环境变量中去,然后在容器中打印全部的环境变量来进行验证
使用fieldRef获取 POD 的基本信息:
# cat test-env-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-env-pod
namespace: kube-system
spec:
containers:
- name: test-env-pod
image: daocloud.io/library/nginx:latest
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
注意: POD 的 name 和 namespace 属于元数据,是在 POD 创建之前就已经定下来了的,所以使用 metata 获取就可以了,但是对于 POD 的 IP 则不一样,因为POD IP 是不固定的,POD 重建了就变了,它属于状态数据,所以使用 status 去获取。
创建上面的 POD:
# kubectl create -f test-env-pod.yaml
pod "test-env-pod" created
POD 创建成功后,查看:
[root@master yaml]# kubectl exec -it test-env-pod -- /bin/bash -n kube-system
root@test-env-pod:/# env | grep POD
POD_IP=172.30.19.24
POD_NAME=test-env-pod
POD_NAMESPACE=kube-system
环境变量的方式:
将容器资源信息注入为容器环境变量
# cat test-env-pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod3
spec:
containers:
- name: dapi-test-container-nginx
image: daocloud.io/library/nginx:latest
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
env:
- name: MY_CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: dapi-test-container-nginx
resource: requests.cpu
- name: MY_CPU_LIMIT
valueFrom:
resourceFieldRef:
containerName: dapi-test-container-nginx
resource: limits.cpu
- name: MY_MEM_REQUEST
valueFrom:
resourceFieldRef:
containerName: dapi-test-container-nginx
resource: requests.memory
- name: MY_MEM_LIMIT
valueFrom:
resourceFieldRef:
containerName: dapi-test-container-nginx
resource: limits.memory
创建上面的 POD:
# kubectl create -f test-env-pod1.yaml
pod "test-env-pod1" created
# kubectl exec -it test-env-pod1 -- /bin/bash
root@test-env-pod1:/# echo $MY_MEM_REQUEST
33554432
root@test-env-pod1:/# echo $MY_MEM_LIMIT
67108864
root@test-env-pod1:/# echo $MY_CPU_LIMIT
1
root@test-env-pod1:/# echo $MY_CPU_REQUEST
1
注意 valueFrom这种特殊的DownwardAPI语法, 目前 resourceFieldRef 可以将容器的资源请求和资源限制等信息映射为容器内部的环境变量:
requests.cpu: 容器的 CPU 的请求指
limits.cpu 容器的 CPU 的限制值
requests.memory 容器的 MEM 的请求值
limits.memory 容器的 MEM 的限制值
resource: limits.hugepages-* 容器的巨页限制值(前提是启用了 DownwardAPIHugePages 特性门控)
resource: requests.hugepages-* 容器的巨页请求值(前提是启用了 DownwardAPIHugePages 特性门控)
resource: limits.ephemeral-storage 容器的临时存储的限制值
resource: requests.ephemeral-storage 容器的临时存储的请求值
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Volume挂载
通过Downward API将 POD 的 Label、Annotation 等信息通过 Volume 挂载到容器的某个文件中去,然后在容器中打印出该文件的值来验证。
# test-volume-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-volume-pod
namespace: kube-system
labels:
k8s-app: test-volume
node-env: test
annotations:
build: test
own: qikqiak
spec:
containers:
- name: test-volume-pod-container
image: daocloud.io/library/nginx:latest
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
volumes:
- name: podinfo
downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
将元数据 labels 和 annotaions 以文件的形式挂载到了/etc/podinfo目录下,创建上面的 POD :
# kubectl create -f test-volume-pod.yaml
pod "test-volume-pod" created
在实际应用中,如果你的应用有获取 POD 的基本信息的需求,就可以利用Downward API来获取基本信息,然后编写一个启动脚本或者利用initContainer将 POD 的信息注入到容器中去,然后在自己的应用中就可以正常的处理相关逻辑了。
目前 Downward API 支持的字段:
1. 可通过 fieldRef 获得的信息
对于大多数 Pod 级别的字段,你可以将它们作为环境变量或使用 downwardAPI 卷提供给容器。 通过这两种机制可用的字段有:
metadata.name Pod 的名称
metadata.namespace Pod 的命名空间
metadata.uid Pod 的唯一 ID
metadata.annotations['<KEY>'] Pod 的注解 <KEY> 的值(例如:metadata.annotations['myannotation'])
metadata.labels['<KEY>'] Pod 的标签 <KEY> 的值(例如:metadata.labels['mylabel'])
spec.serviceAccountName Pod 的服务账号名称
spec.nodeName Pod 运行时所处的节点名称
status.hostIP Pod 所在节点的主 IP 地址
status.podIP Pod 的主 IP 地址(通常是其 IPv4 地址)
此外,以下信息可以通过 downwardAPI 卷 fieldRef 获得,但不能作为环境变量获得:
metadata.labels Pod 的所有标签,格式为 标签键名="转义后的标签值",每行一个标签
metadata.annotations Pod 的全部注解,格式为 注解键名="转义后的注解值",每行一个注解
2. 可通过 resourceFieldRef 获得的信息
resource: limits.cpu 容器的 CPU 限制值
resource: requests.cpu 容器的 CPU 请求值
resource: limits.memory 容器的内存限制值
resource: requests.memory 容器的内存请求值
resource: limits.hugepages-* 容器的巨页限制值(前提是启用了 DownwardAPIHugePages 特性门控)
resource: requests.hugepages-* 容器的巨页请求值(前提是启用了 DownwardAPIHugePages 特性门控)
resource: limits.ephemeral-storage 容器的临时存储的限制值
resource: requests.ephemeral-storage 容器的临时存储的请求值
注意:Downward API 能够获取到的信息,一定是 Pod 里的容器进程启动之前就能够确定下来的信息。而如果你想要获取 Pod 容器运行后才会出现的信息,比如,容器进程的 PID,那就肯定不能使用 Downward API 了,而应该考虑在 Pod 里定义一个 sidecar 容器。
Secret、ConfigMap,以及 Downward API 这三种 Projected Volume 定义的信息,大多还可以通过环境变量的方式出现在容器里。但是,通过环境变量获取这些信息的方式,不具备自动更新的能力。一般情况下,建议使用 Volume 文件的方式获取这些信息。
Service Account详解
Service Account概念
ServiceAccount
官方文档地址:https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/
k8s中提供了良好的多租户认证管理机制,如RBAC、ServiceAccount还有各种Policy等。
什么是 Service Account ?
当用户访问集群(例如使用kubectl命令)时,apiserver 会将用户认证为一个特定的 User Account(目前通常是admin,除非系统管理员自定义了集群配置)。
Pod 容器中的进程也可以与 apiserver 联系。 当它们在联系 apiserver 的时候,它们会被认证为一个特定的 Service Account(例如default)。
使用场景:
Service Account它并不是给kubernetes集群的用户使用的,而是给pod里面的进程使用的,它为pod提供必要的身份认证。
Service account与User account不同之处:
1. User account是为人设计的,而service account则是为Pod中的进程调用Kubernetes API或其他外部服务而设计的
2. User account是跨namespace的,而service account则是仅局限它所在的namespace;
3. 每个namespace都会自动创建一个default service account
4. Token controller检测service account的创建,并为它们创建secret
5. 开启ServiceAccount Admission Controller后:
5.1 每个Pod在创建后都会自动设置spec.serviceAccount为default(除非指定了其他ServiceAccout)
5.2 验证Pod引用的service account已经存在,否则拒绝创建
5.3 如果Pod没有指定ImagePullSecrets,则把service account的ImagePullSecrets加到Pod中
5.4 每个container启动后都会挂载该service account的token和ca.crt到/var/run/secrets/kubernetes.io/serviceaccount/
# kubectl exec nginx-3137573019-md1u2 ls /run/secrets/kubernetes.io/serviceaccount
ca.crt
namespace
token
查看系统的config配置:
这里用到的token就是被授权过的SeviceAccount账户的token,集群利用token来使用ServiceAccount账户
[root@master yaml]# cat /root/.kube/config
默认的 Service Account
默认的 Service Account
默认在 pod 中使用自动挂载的 service account 凭证来访问 API,如 Accessing the Cluster(https://kubernetes.io/docs/tasks/access-application-cluster/access-cluster/#accessing-the-api-from-a-pod) 中所描述。
当创建 pod 的时候,如果没有指定一个 service account,系统会自动在与该pod 相同的 namespace 下为其指派一个default service account,并且使用默认的 Service Account 访问 API server。
例如:
获取刚创建的 pod 的原始 json 或 yaml 信息,将看到spec.serviceAccountName字段已经被设置为 default。
# kubectl get pods podename -o yaml
取消为 service account 自动挂载 API 凭证
注:
因为我们平时用不到取消默认service account,所以本实验未测试取消之后的效果,你如果感兴趣可以自行测试
Service account 是否能够取得访问 API 的许可取决于你使用的 授权插件和策略(https://kubernetes.io/docs/reference/access-authn-authz/authorization/#a-quick-note-on-service-accounts)。
在 1.6 以上版本中,可以选择取消为 service account 自动挂载 API 凭证,只需在 service account 中设置 automountServiceAccountToken: false:
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-robot
automountServiceAccountToken: false
...
只取消单个 pod 的 API 凭证自动挂载:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
serviceAccountName: build-robot
automountServiceAccountToken: false
...
pod 设置中的优先级更高:
如果在 pod 和 service account 中同时设置了 automountServiceAccountToken , pod 设置中的优先级更高。
ServiceAccount应用实例
Service Account(服务账号)测试示例
因为平时系统会使用默认service account,我们不需要自己创建,感觉不到service account的存在,本实验是使用自己手动创建的service account
1、创建serviceaccount
# kubectl create serviceaccount mysa
2、查看mysa
# kubectl describe sa mysa
Name: mysa
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: mysa-token-2zjlp
Tokens: mysa-token-2zjlp
Events: <none>
3、查看mysa自动创建的secret
# kubectl get secret
NAME TYPE DATA AGE
default-token-29dpx kubernetes.io/service-account-token 3 119d
mysa-token-2zjlp kubernetes.io/service-account-token 3 1m
4、使用mysa的sa资源配置pod
# cat mysa-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: my-pod
spec:
containers:
- name: my-pod
image: daocloud.io/library/nginx
ports:
- name: http
containerPort: 80
serviceAccountName: mysa
5、导入
# kubectl apply -f mysa-pod.yaml
6、查看
# kubectl describe pod nginx-pod
7、查看使用的token和secret(使用的是mysa的token)
# kubectl get pod nginx-pod -o jsonpath={".spec.volumes"}
# kubectl get pod nginx-pod -o jsonpath={".spec.volumes[0].name"}
Deployment 资源详解
使用yaml创建Deployment
k8s deployment资源创建流程:
1. 用户通过 kubectl 创建 Deployment。
2. Deployment 创建 ReplicaSet。
3. ReplicaSet 创建 Pod。
对象的命名方式是:子对象的名字 = 父对象名字 + 随机字符串或数字
Deployment是一个定义及管理多副本应用(即多个副本 Pod)的新一代对象,与Replication Controller相比,它提供了更加完善的功能,使用起来更加简单方便。
如果Pod出现故障,对应的服务也会挂掉,所以Kubernetes提供了一个Deployment的概念 ,目的是让Kubernetes去管理一组Pod的副本,也就是副本集 ,这样就能够保证一定数量的副本一直可用,不会因为某一个Pod挂掉导致整个服务挂掉。
Deployment 还负责在 Pod 定义发生变化时,对每个副本进行滚动更新(Rolling Update)。
这样使用一种 API 对象(Deployment)管理另一种 API 对象(Pod)的方法,在 k8s 中,叫作"控制器"模式(controller pattern)。Deployment 扮演的正是 Pod 的控制器的角色。
例1:
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kube100-site
spec:
replicas: 2
template:
metadata:
labels:
app: web
spec:
containers:
- name: front-end
image: nginx
ports:
- containerPort: 80
- name: flaskapp-demo
image: jcdemo/flaskapp
ports:
- containerPort: 5000
例2:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
例3:在上面yaml的基础上添加了volume
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.8
ports:
- containerPort: 80
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: nginx-vol
volumes:
- name: nginx-vol
emptyDir: {}
apiVersion:
注意这里apiVersion对应的值是extensions/v1beta1或者apps/v1
这个版本号需要根据安装的Kubernetes版本和资源类型进行变化,记住不是写死的。此值必须在kubectl apiversion中
# kubectl api-versions
admissionregistration.k8s.io/v1
admissionregistration.k8s.io/v1beta1
apiextensions.k8s.io/v1
apiextensions.k8s.io/v1beta1
apiregistration.k8s.io/v1
apiregistration.k8s.io/v1beta1
apps/v1
authentication.k8s.io/v1
authentication.k8s.io/v1beta1
authorization.k8s.io/v1
authorization.k8s.io/v1beta1
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
batch/v1
batch/v1beta1
certificates.k8s.io/v1beta1
coordination.k8s.io/v1
coordination.k8s.io/v1beta1
events.k8s.io/v1beta1
extensions/v1beta1
metrics.k8s.io/v1beta1
networking.k8s.io/v1
networking.k8s.io/v1beta1
node.k8s.io/v1beta1
policy/v1beta1
rbac.authorization.k8s.io/v1
rbac.authorization.k8s.io/v1beta1
scheduling.k8s.io/v1
scheduling.k8s.io/v1beta1
storage.k8s.io/v1
storage.k8s.io/v1beta1
v1
kind:
资源类型:这里指定为Deployment。
metadata:
指定一些meta信息,包括名字或标签之类的。
每一个 API 对象都有一个叫作 Metadata 的字段,这个字段是 API 对象的"标识",即元数据,也是我们从 Kubernetes 里找到这个对象的主要依据。
labels:
Labels是最主要的字段,是一组 key-value 格式的标签,k8s中的所有资源都支持携带label,默认情况下,pod的label会复制rc的label
k8s使用用户自定义的key-value键值对来区分和标识资源集合(就像rc、pod等资源),这种键值对称为label。
像 Deployment 这样的控制器对象,就可以通过这个 Labels 字段从 Kubernetes 中过滤出它所关心的被控制对象。
关于Annotations:
在 Metadata 中,还有一个与 Labels 格式、层级完全相同的字段叫 Annotations,它专门用来携带 key-value 格式的内部信息。所谓内部信息,指的是对这些信息感兴趣的,是 Kubernetes 组件本身,而不是用户。所以大多数 Annotations,都是在 Kubernetes 运行过程中,被自动加在这个 API 对象上。
可以通过-L参数来查看:
# kubectl get rc my-nginx -L app
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS APP
my-nginx11 nginx nginx app=nginx111 2 nginx
selector:
过滤规则的定义,是在 Deployment 的"spec.selector.matchLabels"字段。一般称之为:Label Selector。
pod的label会被用来创建一个selector,用来匹配过滤携带这些label的pods。
可以通过kubectl get请求这样一个字段来查看template的格式化输出:
# kubectl get rc my-nginx -o template --template="{{.spec.selector}}"
map[app:nginx11]
使用labels定位pods
[root@k8s-master ~]# kubectl get pods -l app=nginx11 -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx11-1r2p4 1/1 Running 0 11m 10.0.6.3 k8s-node-1
my-nginx11-pc4ds 1/1 Running 0 11m 10.0.33.6 k8s-node-2
检查你的Pod的IPs:
# kubectl get pods -l app=nginx -o json | grep podIP
"podIP": "10.245.0.15",
"podIP": "10.245.0.14",
spec :
一个 k8s 的 API 对象的定义,大多可以分为 Metadata 和 Spec 两个部分。前者存放的是这个对象的元数据,对所有 API 对象来说,这一部分的字段和格式基本上是一样的;而后者存放的,则是属于这个对象独有的定义,用来描述它所要表达的功能。
这里定义需要两个副本,此处可以设置很多属性,主要是受此Deployment影响的Pod的选择器
spec 选项的template其实就是对Pod对象的定义
可以在Kubernetes v1beta1 API 参考中找到完整的Deployment可指定的参数列表
replicas:
定义的 Pod 副本个数 (spec.replicas) 是:2
template:
定义了一个 Pod 模版(spec.template),这个模版描述了想要创建的 Pod 的细节。例子里,这个 Pod 里只有一个容器,这个容器的镜像(spec.containers.image)是 nginx:1.7.9,这个容器监听端口(containerPort)是 80。
volumes:
是属于 Pod 对象的一部分。需要修改 template.spec 字段
例3中,在 Deployment 的 Pod 模板部分添加了一个 volumes 字段,定义了这个 Pod 声明的所有 Volume。它的名字叫作 nginx-vol,类型是 emptyDir。
关于emptyDir 类型:
等同于 Docker 的隐式 Volume 参数,即:不显式声明宿主机目录的 Volume。所以,Kubernetes 也会在宿主机上创建一个临时目录,这个目录将来就会被绑定挂载到容器所声明的 Volume 目录上。
k8s 的 emptyDir 类型,只是把 k8s 创建的临时目录作为 Volume 的宿主机目录,交给了 Docker。这么做的原因,是 k8s 不想依赖 Docker 自己创建的那个 _data 目录。
volumeMounts:
Pod 中的容器,使用的是 volumeMounts 字段来声明自己要挂载哪个 Volume,并通过 mountPath 字段来定义容器内的 Volume 目录,比如:/usr/share/nginx/html。
hostPath:
k8s 也提供了显式的 Volume 定义,它叫做 hostPath。比如下面的这个 YAML 文件:
...
volumes:
- name: nginx-vol
hostPath:
path: /var/data
type: Directory
这样,容器 Volume 挂载的宿主机目录,就变成了 /var/data
使用 kubectl exec 指令,进入到这个 Pod 当中(即容器的 Namespace 中)查看这个 Volume 目录:
# kubectl exec -it nginx-deployment-5c678cfb6d-lg9lw -- /bin/bash
# ls /usr/share/nginx/html
创建Deployment:
将上述的YAML文件保存为deployment.yaml,然后创建Deployment:
# kubectl apply -f deployment.yaml
deployment "kube100-site" created
检查Deployment的列表:
通过 kubectl get 命令检查这个 YAML 运行起来的状态是不是与我们预期的一致:
# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kube100-site 2 2 2 2 2m
# kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-deployment-67594d6bf6-9gdvr 1/1 Running 0 10m
nginx-deployment-67594d6bf6-v6j7w 1/1 Running 0 10m
kubectl get 指令的作用,就是从 Kubernetes 里面获取(GET)指定的 API 对象。可以看到,在这里我还加上了一个 -l 参数,即获取所有匹配 app: nginx 标签的 Pod。需要注意的是,在命令行中,所有 key-value 格式的参数,都使用"="而非":"表示。
删除Deployment:
[root@k8s-master ~]# kubectl delete deployments my-nginx
deployment "my-nginx" deleted
Nodeselector: 定向调度
Kubernetes Master 上的 Scheduler 服务( kube-scheduler 进程)负责实现 Pod 的调度,整个调度过程通过执行一系列复杂的算法,最终为每个 Pod 计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道 Pod 最终会被调度到哪个节点上。在实际情况中,也可能需要将 Pod 调度到指定的一些 Node 上,可以通过 Node 的标签( Label) 和 Pod 的 node Selector 属性相匹配,来达到上述目的。
kubectl label nodes <node-name> <label-key>=<label-value>
这里 ,我们为 k8s-node-l 节点打上一个 zone- north 的标签, 表明它是“北方”的一个节点 :
# kubectl label nodes kBs-node-1 zone=north
NAME LABELS STATUS
kBs-node-1 kubernetes.io/hostname=kBs-node-1,zone=north Ready
上述命令行操作也可以通过修改资源定义文件的方式 , 并执行 kubectl replace -f xxx.yaml 命令来完成。
(2)然后,在 Pod 的定义中加上 nodeSelector 的设置,以 redis-master-controIler. yaml 为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
matchLabels:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: daocloud.io/library/redis
ports:
- containerPort: 80
nodeSelector:
zone: north
运行 kubectl create -f 命令创建 Pod , scheduler 就会将该 Pod 调度到拥有 zone=north 标签的Node 上 。
使用 kubectl get pods -o wide 命令可以验证 Pod 所在的 Node:
# kubectl get pods - o wide
NAME READY STATUS RESTARTS AGE node
redis-master-fOrqj 1/1 Running 0 19s k8s-node-1
如果我们给多个 Node 都定义了相同的标签(例如 zone=north ),则 scheduler 将会根据调度算法从这组 Node 中 挑选一个可用 的 Node 进行 Pod 调度 。
通过基于 Node 标签的调度方式,我们可以把集群中具有不同特点的 Node 贴上不同的标签,例如“role=frontend ” “ role=backend ” “ role=database ”等标签,在部署应用时就可以根据应用的需求设置 NodeSelector 来进行指定 Node 范围的调度 。
需要注意的是,如果我们指定了 Pod 的 nodeSelector 条件,且集群中不存在包含相应标签的Node , 则即使集群中还有其他可供使用的 Node ,这个 Pod 也无法被成功调度。
除了用户可以自行给 Node 添加标签, Kubernetes 也会给 Node 预定义一些标签,包括:
kubernetes.io/hostname
kubernetes.io/os
kubernetes.io/arch
beta.kubernetes.io/os
beta.kubernetes.io/arch
用户 也可以使用这些系统标签进行 Pod 的定向调度 。
Node Selector 通过标签的方式, 简单地实现了限制 Pod 所在节点的方法 。亲和性调度机制则极大地扩展了 Pod 的调度能力,主要 的增强功能如下 。
- 更具表达力(不仅仅是“符合全部”的简单情况) 。
- 可以使用软限制优先采用等限制方式,代替之前的硬限制,这样调度器在无法满足优先需求的情况下,会退而求其次 ,继续运行该 Pod 。
- 可以依据节点上正在运行的其他 Pod 的标签来进行限制,而非节点本身的标签 这样就可以定义一种规则来描述 Pod 之间的亲和或互斥关系 。
亲和性调度功能包括节点亲和性( NodeAffinity )和 Pod 亲和性 (PodAffinity )两个维度的设置。节点亲和性与 NodeSelector 类似,增强了上述前两点的优势: Pod 的亲和与互斥限制则通过 Pod 标签而不是节点标签来实现,也就是上面内容所陈述的方式,同时具有前两点提到的优点。
NodeSelector 将会继续使用,随着节点亲和性越来越能够表达 nodeSelector 表达的功能,最终 NodeSelector 会被废弃掉。
NodeAffinity: Node 亲和性调度
NodeAffinity 意为 Node 亲和性的调度策略,是用于替换 NodeSelector 的全新调度策略 。目前有两种节点亲和性表达。
- RequiredDuringSchedulinglgnoredDuringExecution:必须满足指定的规则才可以调度 Pod到Node上(功能与nodeSelector很像,但是使用的是不同的语法)相当于硬限制。
- PreferredDuringSchedulinglgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度 Pod 到 Node 上 ,但并不强求,相 当于软限制 。多个优先级规则还可以设置权重( weight )值,以定义执行的先后顺序。
IgnoredDuringExecution 的 意思是 :如果一个 Pod 所在的节点在 Pod 运行期间标签发生了变更,不再符合该 Pod 的节点亲和性需求,则系统将忽略 Node 上 Label 的变化,该 Pod 能继续在该节点运行。
下面的例子设置了 NodeAffinity 调度的如下规则 。
requiredDuringSchedulinglgnoredDuringExecution 要求只运行在 amd64 的节 点上( beta.kubemetes.io/arch In amd64 ) 。
preferredDuringSchedulinglgnoredDuringExecution 的要求是尽量运行在 “磁盘类 型为ssd”(disk-type In ssd )的节点上。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity+++++
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disk-type
operator: In
values:
- ssd
containers:
- name: with-node-affinity
image: registry.aliyuncs.com/google_containers/pause:3.1
从上面的配置中可 以看到 In 操作符, NodeAffrnity 语法支持的操作符包括 In 、 Notln 、 Exists 、DoesNotExist 、 Gt 、 Lt 。虽然没有节点排斥 的功能, 但是用 Notln 和 DoesNotExist 就可以实现排斥 的 功能了。
NodeAffinity 规则设置的注意事项如下。
- 如果同时定义了 nodeSelector 和 nodeAffinity ,那么必须两个条件都得到满足, Pod 才能最终运行在指定的 Node 上。
- 如果 nodeAffrnity 指定了多个 nodeSelectorTerms , 那么只需要其中 一个能够匹配成功即可 。
- 如果 nodeSelectorTerms 中有多个 matchExpressions , 则一个节点必须满足所有matchExpressions 才能运行该 Pod 。
PodAffinity : Pod亲和与互斥调度策略
Pod 间的亲和与互斥从 Kubemetes v 1.4 版本开始引 入。这一功能让用户从另外一个角度来限制 Pod 所能运行的节点 :根据节点上正在运行的 Pod 的标签而不是节点的标签进行判断和调度 , 要求对节点和 Pod 两个条件进行匹配 。 这种规则可以描述为:如果在具有标签 X 的 Node上运行了一个或者多个符合条件 Y 的 Pod , 那么 Pod 应该(如果是互斥的情况,那么就变成拒绝)运行在这个 Node 上。
这里 X 指的是一个集群 中的节点、机架、区域等概念,通过 Kubemetes 内置节点标签中的key 来进行声明 。 这个 key 的名字为 topologyKey ,意为表达节点所属的 topology 范围 。
kubemetes.io/hostname
failure-domain.beta.kubemetes.io/zone
failure-domain.beta.kubemetes.io/region
与节点不同的是, Pod 是属于某个命名空间的 ,所以条件 Y 表达的是一个或者全部命名空间中的一个 Label Selector 。
和节点亲和相同, Pod 亲和与互斥的条件设量也是叫 requiredDuringSchedulingIgnoredDuringExecution和 preferredDuringSchedulingIgnoredDuringExecution。 Pod 亲和性定义于 PodSpec 的 affinity 字段下的podAffinity 子宇段里。 Pod 间的互斥性则定义于同一层次的 podAntiAffmity 子字段中。
下面通过实例来说明 Pod 间的亲和性和互斥性策略设置。
1) 参照目标 Pod
首先,创建一个名为 pod-flag 的 Pod ,带有标签 security=S1 和 app=nginx ,后面的例子将使用 pod-flag 作为 Pod 亲和与互斥的目标 Pod 。
apiVersion: v1
kind: Pod
metadata:
name: pod-flad
labels:
security: "S1"
app: "nginx"
spec:
containers:
- name: nginx
image: daocloud.io/library/nginx
2) Pod 的亲和性调度
下面创建第 2 个 Pod 来说明 Pod 的亲和性调度,这里定义的亲和标签是 security=S1 ,对应上面的 Pod “ pod-flag ", topologyKey 的值被设置为 “ kubemetes . io/hostname ”
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: registry.aliyuncs.com/google_containers/pause:3.1
# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity 1/1 Running 0 8s 10.244.2.28 node2 <none> <none>
pod-flad 1/1 Running 0 13m 10.244.2.27 node2 <none> <none>
创建 Pod 之后,使用 kubectl get pods -o wide 命令可以看到,这两个 Pod 处于同一个 Node之上运行 。
有兴趣还可以测试一下 , 在创建这个 Pod 之前,删掉这个节点的 ku bemetes.io/hostname 标签,重复上面的创建步骤,将会发现 Pod 会一直处于 Pending 状态,这是因为找不到满足条件的 Node 了。
3) Pod 的互斥性调度
创建第 3 个 Pod , 我们希望它不能与参照目标 Pod 运行在同一个 Node 上 。
apiVersion: v1
kind: Pod
metadata:
name: anti-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
containers:
- name: anti-affinity
image: registry.aliyuncs.com/google_containers/pause:3.1
这里要求这个新 Pod 与 security=S 1 的 Pod 为同一个 zone ,但是不与 app=nginx 的 Pod 为同一个 Node 。创建 Pod 之后,同样用 kubectl get pods -o wide 来查看,会看到新的 Pod 被调度到了同一 Zone 内的不同的 Node 上去。
与节点亲和性类似, Pod 亲和性的操作符也包括 In、 Notln 、 Exists 、 DoesNotExist 、 Gt 、 Lt 。
原则上, topologyKey 可以使用任何合法的标签 Key 赋值,但是出于性能和安全方面的考虑,对 topo logyKey 有如下限制。
- 在 Pod 亲和性和 RequiredDuringScheduling 的 Pod 互斥性的定义中,不允许使用空的topologyKey 。
- 如果 Admission controller 包含了 LimitPo世IardAntiAffinityTopolo町,那么针对 RequiredDuringScheduling 的 Pod 互斥性定义就被限制为 kubemetes . io/hostname , 要使用自定义
的 topologyKey ,就要改写或禁用该控制器。
- 在 PreferredDuringScheduling 类型 的 Pod 互斥性定义中, 空的 topologyKey会被解释为 kubemetes.io/hostname 、failure-domain.beta. kubemetes.io/zone 及 failure-domain.beta.kubemetes.io/region 的组合。
- 如果不是上述情况,就可以采用任意合法的 topologyKey了 。
PodAffnity 规则设置的注意事项如下 。
- 除了设置 Label Selector 和 topologyKey ,用户还可 以指定 namespace 列表来进行限制,同样,使用 Label Selector 对 namespace 进行选择。 namespace 的定义和 Label Selector 及 topologyKey 同级。省略 namespace 的设置,表示使用定义了 affmity/anti-affinity 的Pod 所在的 namespace 。如果 namespace 设置为空值( ” η ,则表示所有 namespace 。
- 在所有关联 requiredDuringSchedulinglgnoredDuringExecution 的 matchExpressions 全都满足之后,系统才能将 Pod 调度到某个 Node 上。
Pod 间亲和性与反亲和性在与更高级别的集合(例如 ReplicaSet、StatefulSet、 Deployment 等)一起使用时,它们可能更加有用。 这些规则使得你可以配置一组工作负载,使其位于相同定义拓扑(例如,节点)中。
在下面的 Deployment 示例中,副本上设置了标签 app=store。 podAntiAffinity 规则告诉调度器避免将多个带有 app=store 标签的副本部署到同一节点上。 因此,每个独立节点上会创建一个缓存实例。
apiVersion: apps/v1
kind: Deployment
metadata:
name: pause
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: pause
image: registry.aliyuncs.com/google_containers/pause:3.1
因为我们只有两个工作节点,所以当第三个pod部署时就无法调度
# kubectl get po -l app=store -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pause-6988b4c8cb-kxqcf 0/1 Pending 0 74s <none> <none> <none> <none>
pause-6988b4c8cb-kz7wn 1/1 Running 0 74s 10.244.2.85 k8s3 <none> <none>
pause-6988b4c8cb-x5j2x 1/1 Running 0 74s 10.244.1.114 k8s2 <none> <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 36s (x3 over 114s) default-scheduler
0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate,
2 node(s) didn't match pod affinity/anti-affinity, 2 node(s) didn't match pod anti-affinity rules.
更多关于 Pod 亲和性和互斥性调度的信息可 以参考其设计文档,网址为 https://github.com/kubemetes/kubemetes/blob/master/docs/design/podaffinity.md 。
污点和容忍
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/taint-and-toleration/
节点亲和性(详见这里) 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点
Taint(污点)则相反,它使节点能够排斥一类特定的 Pod
您可以使用命令 kubectl taint 给节点增加一个污点。比如,
kubectl taint nodes node1 key1=value1:NoSchedule
vim pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector: # 定向调度是为了一定能调度到node1上
kubernetes.io/hostname: node1
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
# kubectl apply -f pod1.yaml
# kubectl get po nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 113s 10.244.0.4 node1 <none> <none>
Pod PriorityPreemption: Pod优先级调度 [不建议使用]
对于运行各种负载 (如 Service 、Job) 的中等规模或者大规模的集群来说,出于各种原因,我们需要尽可能提高集群的资源利用率。 而提高资源利用率的常规做法时采用优先级方案,即不同类型的负载对应不同的优级,同时允许集群中的所有负载所需的资源总量超过集群可提供的资源,在这种情况下,当发生资源不足的情况时,系统可以选择释放一些不重要的负载 (优先级最低的),保障最重要的负载能够获取足够的资源稳定运行。
在Kubernetes 1.8版本之前,当集群的可用资源不足的时,在用户提交新的Pod 创建请求后, 该Pod 会一直处于 Pending 状态,即使这个 Pod 是一个重要 (很有身份)的 Pod,也只能被动等待其他 Pod 被删除并释放资源,才能有机会被调度成功。 Kubernetes 1.8 版本引入基于 Pod 优先级抢占 (Pod Priority Preemption)的调度策略,此时 Kubernetes 会尝试释放目标节点上低优先级的 Pod,以腾出空间 安置高优先级的 Pod,这种调度方式被称为 “抢占式调度”。在 Kubernetes 1.11版本中,该特性升级为 Beta 版本,默认开启,在后续的 Kubernets 1.14 版本中正式 release。 如何声明一个负载相对其他负载“更重要”? 我们可以通过下列几个维度来定义:
。 Priority,优先级
。 Qos, 服务质量等级
。 系统定义的其他度量指标
优先级抢占调度策略的和行为分别是驱逐(Eviction)与抢占(Preemtion),这两种行为的使用场景不同,效果不同。 Eviction 是 kubelet 进程的行为,即当一个Node 发生资源不足 (under resource pressure) 的情况时,该节点上的 kubelet 进程会执行驱逐动作,此时 Kubelet 会综合考虑 Pod 的优先级、资源申请量与实际使用量等信息来计算那些 Pod 需要驱逐; 当同样优先级的 Pod 需要被驱逐时,实际使用的资源量超过申请量最大倍数的高耗能 Pod 会被首先驱逐。对于 Qos 等级为 “Best Effort” 的 Pod 来说, 由于没有定义资源申请(CPU/Memory Request),所以他们实际使用的资源可能非常大。 Preemption 则是 Scheduler 执行的行为,当一个新的 Pod 因为资源无法满足而不能被调度时,Scheduler 可能 (有权决定)选择驱逐部分低优先级的 Pod 实例来满足此 Pod 的调度目标,这就是 Preemption 机制
需要注意的是,Scheduler 可能会驱逐 Node A上的一个 Pod 以满足 Node B 上的一个新 Pod 的调度任务。比如下边的这个例子:
一个低优先级的 Pod A 在 Node A (属于机架 R)上运行,此时有一个高优先级的 Pod B 等待调度,目标节点是同属机架 R 的 Node B,他们中的一个或全部都定义了 anti-affinity 规则,不允许在同一个机架上运行,此时 Scheduler 只好“丢车保帅”,驱逐低优先级的 Pod A 以满足高优先级的 Pod B 的调度
Pod 优先级调度示例如下:
首先,有集群管理员创建 PriorityClasses,PriorityClass 不属于任何命名空间
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 100000
globalDefault: false
description: "This priority class should be used for Test pods only."
上述Yaml定义了一个名为 high-priority 的优先级类别,优先级为 100000,数字越大,优先级越高,超过1亿的数字被系统保留,用于指派给系统组件
我们可以看下任意 Pod 中引用上述 Pod 优先级类别:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
调度器里维护着一个调度队列。所以,当 Pod 拥有了优先级之后,高优先级的 Pod 就可能会比低优先级的 Pod 提前出队,从而尽早完成调度过程。**这个过程,就是“优先级”这个概念在 Kubernetes 里的主要体现。**而当一个高优先级的 Pod 调度失败的时候,调度器的抢占能力就会被触发。这时,调度器就会试图从当前集群里寻找一个节点,使得当这个节点上的一个或者多个低优先级 Pod 被删除后,待调度的高优先级 Pod 就可以被调度到这个节点上。这个过程,就是“抢占”这个概念在 Kubernetes 里的主要体现。
为了方便叙述,我接下来会把待调度的高优先级 Pod 称为“抢占者”(Preemptor)。
当上述抢占过程发生时,抢占者并不会立刻被调度到被抢占的 Node 上。事实上,调度器只会将抢占者的 spec.nominatedNodeName 字段,设置为被抢占的 Node 的名字。然后,抢占者会重新进入下一个调度周期,然后在新的调度周期里来决定是不是要运行在被抢占的节点上。这当然也就意味着,即使在下一个调度周期,调度器也不会保证抢占者一定会运行在被抢占的节点上。
这样设计的一个重要原因是,调度器只会通过标准的 DELETE API 来删除被抢占的 Pod,所以,这些 Pod 必然是有一定的“优雅退出”时间(默认是 30s)的。而在这段时间里,其他的节点也是有可能变成可调度的,或者直接有新的节点被添加到这个集群中来。所以,鉴于优雅退出期间,集群的可调度性可能会发生的变化,把抢占者交给下一个调度周期再处理,是一个非常合理的选择。
而在抢占者等待被调度的过程中,如果有其他更高优先级的 Pod 也要抢占同一个节点,那么调度器就会清空原抢占者的 spec.nominatedNodeName 字段,从而允许更高优先级的抢占者执行抢占,并且,这也就是得原抢占者本身,也有机会去重新抢占其他节点。这些,都是设置 nominatedNodeName 字段的主要目的。
优先级抢占的调度方式可能会导致调度陷入 “死循环” 状态。当 Kubernetes 集群配置了多个调度器 (Scheduler)时,这一行为可能会发生。
参考:
https://my.oschina.net/jxcdwangtao/blog/1559580
http://docs.kubernetes.org.cn/769.html
实验示例可参考 https://www.jianshu.com/p/97c31d6030db
DaemonSet: 在每个Node上调度一个Pod
DaemonSet 是 Kubemetes v1.2 版本新增的一种资源对象,用于管理在集群中每个 Node 上仅运行一份 Pod 的副本实例,如图 2.4 所示。
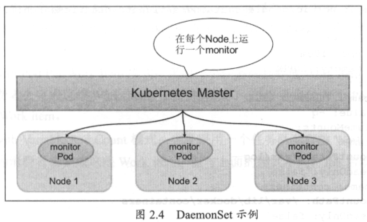
这种用法适合一些有这种需求的应用。
- 在每个 Node 上运行一个 GlusterFS 存储或者 Ceph 存储的 Daemon 进程。
- 在每个 Node 上运行一个日志采集程序,例如 Fluentd 或者 Logstach 。
- 在每个 Node 上运行一个性能监控程序,采集该 Node 的运行性能数据,例如 Prometheus Node Exporter 、 collectd 、 New Relic agent 或者 Ganglia gmond 等。
DaemonSet 的 Pod 调度策略与 RC 类似,除了使用系统内置的算法在每台 Node 上进行调度,也可以在 Pod 的定义中使用 NodeSelector 或 NodeAffinity 来指定满足条件的 Node 范围进行调度。
下面的例子定义为在每台 Node 上启动一个 fluentd 容器,配置文件 fluentd-ds. yaml 的内容如下,其中挂载了物理机的两个目录“/var/log ”和“/var/lib/docker/containers ”:
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-cloud-logging
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
selector:
matchLabels:
k8s-app: fluentd-cloud-logging
template:
metadata:
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
containers:
- name: fluentd-cloud-logging
#image: gcr.io/google_containers/fluentd-elasticsearch:1.17
image: googlecontainersmirrors/fluentd-elasticsearch:1.17
resources:
limits:
cpu: 100m
memory: 200Mi
env:
- name: FLUENTD_ARGS
value: -q
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: false
- name: containers
mountPath: /var/lib/docker/containers
readOnly: false
volumes:
- name: containers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
使用 kubectl create 命令创建该 DaemonSet:
# kubectl create -f fluentd-ds.yaml
daemons et "fluentd-cloud-logging" created
查看创建好的 DaemonSet 和 Pod , 可 以看到在每个 Node 上都创建了一个 Pod:
# kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
fluentd-cloud-logging-dfg6v 1/1 Running 0 5d2h
fluentd-cloud-logging-nln9v 1/1 Running 0 5d2h
fluentd-cloud-logging-xpmqq 1/1 Running 0 5d2h
Job
Kubemetes 从 1.2 版本开始支持批处理类型 的应用,我们可以通过 Kubemetes Job 资源对象来定义并启动一个批处理任务。 批处理任务通常并行( 或者串行)启动多个计算进程去处理一批工作项( work item ),处理完成后 , 整个批处理任务结束。按照批处理任务实现方式的不同 ,批处理任务可以分为如图 2.5 所示的几种模式。
- Job Template Expansion模式 :一个 Job 对象对应一个待处理的 Work item ,有几个 Work item 就产生几个独立的 Job , 通常适合 Work item 数量少 、每个 Work item 要处理的数据量比较大的场景, 比如有一个 1OOGB 的文件作为一个 Work item , 总共 10 个文件需要处理。
- Queue with Pod Per Work Item 模式: 采用一个任务队列存放 Work item ,一个 Job 对象作为消费者去完成这些 Work item , 在这种模式下 , Job 会启动 N 个 Pod ,每个 Pod 对应一个 Work item 。
- Queue with Variable Pod Count 模式:也是采用一个任务队列存放 Work item ,一个 Job对象作为消费者去完成这些 Work item , 但与上面的模式不同 ,Job 启动 的 Pod 数量是可变的。
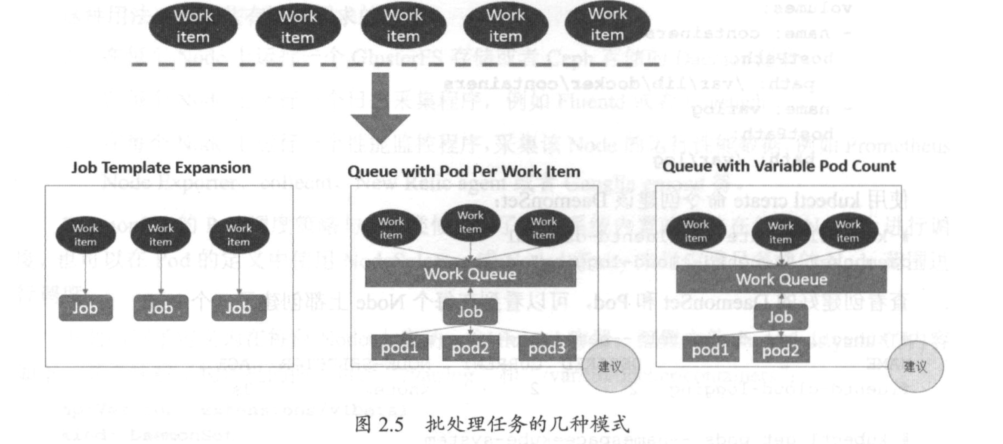
还有一种被称为 Single Job with Static Work Assignment 的模式,也是一个 Job 产生多个 Pod的模式,但它采用程序静态方式分配任务项,而不是采用队列模式进行动态分配 。
如表 2.16 所示是这几种模式的一个对比 。
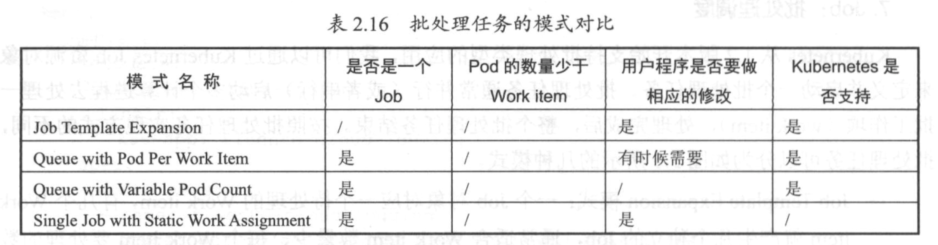
考虑到批处理的并行问题, Kubemetes 将 Job 分以下三种类型。
1) Non-parallel Jobs
通常一个 Job 只启动一个 Pod ,则除非 Pod 异常,才会重启 该 Pod ,一旦此 Pod 正常结束 ,Job 将结束 。
2) Parallel Jobs with a fixed completion count
并行 Job 会启动多个 Pod ,此时需要设定 Job 的.spec.completions 参数为一个正数, 当正常结束的 Pod 数量达至此参数设定的值后, Job 结束。 此外, Job 的. spec. parallelism 参数用来控制并行度,即同时启动几个 Job 来处理 Work Item 。
3) Parallel Jobs with a work queue
任务队列方式的并行 Job 需要一个独立的 Queue, Work item 都在一个 Queue 中存放,不能设置 Job 的 .spec.completions 参数,此时 Job 有以下特性。
。 每个 Pod 能独立判断和决定是否还有任务项需要处理。
。 如果某个 Pod 正常结束,则 Job 不会再启动新的 Pod 。
。 如果一个 Pod 成功结束,则此时应该不存在其他 Pod 还在干活的情况,它们应该都处于即将结束、退出的状态。
。 如果所有 Pod 都结束了,且至少有一个 Pod 成功结束,则整个 Job 算是成功结束。
下面我们分别说说常见的三种批处理模型在 Kubemetes 中的例子。
首先是 Job Template Expansion 模式,由于这种模式下每个 Work item 对应一个 Job 实例,所以这种模式首先定义一个 Job 模板,模板里主要的参数是 Work item 的标识,因为每个 Job处理不同的 Work item 。如下所示的 Job 模板(文件名为 job.yaml.txt )中的$ITEM 可以作为任务项的标识:
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox
command: ["sh", "-c", "echo Processing item $ITEM && sleep 5"]
restartPolicy: Never
通过模板文件创建三个对应的Job定义文件并创建Job:
# mkdir job
# for i in tiger five six
> do
> cat job.yaml.txt | sed "s/\$ITEM/$i/" > ./job/job-$i.yaml
> done
# ls job
job-five.yaml job-six.yaml job-tiger.yaml
# kubectl apply -f job/
job.batch/process-item-five created
job.batch/process-item-six created
job.batch/process-item-tiger created
查看运行状态
# kubectl get job -l jobgroup=jobexample
NAME COMPLETIONS DURATION AGE
process-item-five 1/1 14s 49s
process-item-six 1/1 22s 49s
process-item-tiger 1/1 14s 49s
其次,我们看看Queue with Pod Per Work Item 模式,在这种模式下需要一个任务队列存放Work Item, 比如RabbitMQ,客户端程序先把要处理的任务变成 Work item 放入到任务队列,然后编写 Worker 程序并打包镜像并定义 Job 中的Work Pod,Woker 程序的实现逻辑是从任务队列中拉取一个 Work Item并处理,处理完成后即结束进程,图2.6 给出了并行度为 2 的一个Demo示意图
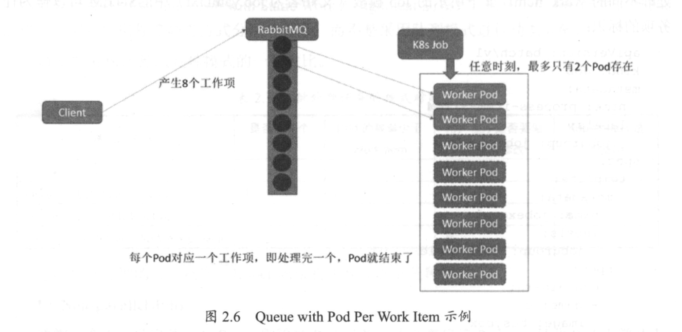
最后,我们再看看 Queue with Variable Pod Count 模式,如图所示。 由于这种模式下, Worker程序需要知道队列中是否还有等待处理的 Work item,如果有就取出来处理,否则就认为所有的工作完成并结束进程, 所以任务队列通常采用 Redis或者数据库来实现
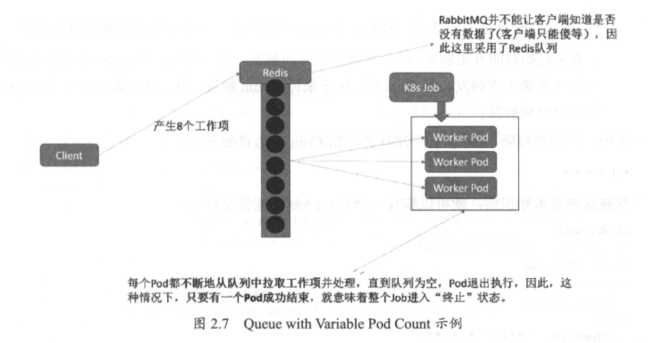
Cronjob
kubernetes 从 v1.5 版本开始增加了一种新类型的 Job,类型 Linux Cron 的定时任务 Cron Job,下面我们来看看如何定义和使用这种新类型的 Job。
首先确保 kubernetes 的版本为 1.8 及以上
其次,需要掌握 Cron Job 的定时表达式,他基本照搬了Linux Cron 的表达式,格式如下
Minutes Hours Dayofmonth Month DayofWeek
其中每个域都可以出现的字符如下:
。 Minutes: 可出现 “,” “-” “*” “/” 这四个字符, 有效范围为 0~59的整数
。 Hours: 可出现 “,” “-” “*” “/” 这四个字符,有效范围为 0~23的整数
。 DayofMonth: 可出现 “,” “-” “*” “/” “?” “L” “W” “C” 这八个字符,有效范围为0~31的整数
。 Month: 可出现 “,” “-” “*” “/” 这四个字符,有效范围为 1~12 的整数或 JAN~DEC。
。 DayofWeek: 可出现 “,” “-” “*” “/” “?” “L” “C” “#” 这八个字符,有效范围为 1~7 的整数或 SUN~SAT,1表示星期天,2表示星期一,以此类推
下图未Linux Cron的格式,供参考
| 字段 | 是否必填 | 允许值 | 允许特殊字符 | 备注 |
|---|---|---|---|---|
| Minutes | 是 | 0–59 | * , - |
|
| Hours | 是 | 0–23 | * , - |
|
| Day of month | 是 | 1–31 | * , - ? L W |
?``L``W只有部分软件实现了 |
| Month | 是 | 1–12 or JAN–DEC | * , - |
|
| Day of week | 是 | 0–6 or SUN–SAT | * , - ? L # |
?``L``#只有部分软件实现了 |
表达式中的特殊字符 “*” 与 “/” 的含义如下:
。 *:表示匹配该域的任意值, 假如再Minutes 域使用 “*” 。则表示每分钟都会触发事件
。 /:表示从起始时间开始触发,然后每隔固定时间触发一次,例如在 Minutes 域设定为5/20 ,则意味这第1次触发在 5min 时,接下来每 20 min触发一次,将在第25 min、第45 min等时刻分别触发。[未验证成功,和Linux cron 不一样]
可以通过 https://tool.lu/crontab/ 验证计划任务是否按预期方式执行
掌握了基本知识后,就可以编写一个 Cron Job 的配置文件了:
cat cron-job.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo "Hello from the Kubernetes cluster for tigerfive"
restartPolicy: OnFailure
该示例定义了一个名为 hello的 Cron Job, 任务每隔 1min 执行一次,运行的镜像是 busybox,执行的命令是 shell 脚本,脚本执行时会在控制台输出当前时间和字符串 “Hello from the Kubernetes cluster for tigerfive”
接下来执行 Kubectl apply 命令完成创建
# kubectl apply -f cron-job.yaml
cronjob.batch/hello created
然后每个 1民执行 kubectl get cronjob hello 查看任务状态, 发现的确每分钟调度一此:
# kubectl get cronjob hello
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 56s 38m
# kubectl get cronjob hello
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 27s 39m
# kubectl get cronjob hello
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 21s 40m
还可以通过查找 Cron Job 对应的容器, 验证每隔一分钟产生一个容器的事实。如下所示 :
docker ps -a |grep k8s_hello_hello-
e52325728edc busybox "/bin/sh -c 'date; e…" 52 seconds ago Exited (0) 52 seconds ago k8s_hello_hello-1588864200-fwsww_default_655d08fa-7645-44dc-92c1-8cb8c1a6383d_0
...
458d88c92778 busybox "/bin/sh -c 'date; e…" 27 seconds ago Exited (0) 27 seconds ago k8s_hello_hello-1588861860-w49rb_default_ef7a9fd8-b9e4-4d18-a7ce-d1f116e5a423_0
...
fa45b5a3eb90 busybox "/bin/sh -c 'date; e…" 3 minutes ago Exited (0) 3 minutes ago k8s_hello_hello-1588864020-x67n5_default_fa131079-3f82-4793-8773-b0f389622fcc_0
108acb81d36a busybox "/bin/sh -c 'date; e…" 2 minutes ago Exited (0) 2 minutes ago k8s_hello_hello-1588864080-552s5_default_fdec65c0-a975-46a9-a8a1-2e2701f325bd_0
9a3ee80b232c busybox "/bin/sh -c 'date; e…" About a minute ago Exited (0) About a minute ago k8s_hello_hello-1588861800-cttm8_default_125fb1dc-531a-48d3-b67a-d2f31557f55e_0
查看其中一个容器的日志:
# docker logs e803a7a6c067
Sat May 16 08:10:15 UTC 2020
Hello from the Kubernetes cluster for tigerfive
运行下列命令,可以更直观地了解Cron Job定期触发任务执行的历史和调度
# kubectl get job --watch
NAME COMPLETIONS DURATION AGE
hello-1588864380 1/1 10s 2m24s
hello-1588864440 1/1 12s 84s
hello-1588864500 1/1 9s 24s
process-item-five 1/1 14s 87m
process-item-six 1/1 22s 87m
process-item-tiger 1/1 14s 87m
其中 COMPLETIONS 列为 1/1 的每一行都是一个成功的 Job,以第1行的“ hello-1588864440” 的 Job 为例,他对应的 Pod 可以通过下列方式找到:
# kubectl get pods |grep hello-1588864380-rl9tf
hello-1588864440-rl9tf 0/1 Completed 0 89s
当不需要某个 Cron Job时,可以通过下面的命令删除它:
# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 15s 73m
# kubectl delete cronjob hello
cronjob.batch "hello" deleted
在 Kubernets 1.9 版本后,kubectl 命令增加了别名 cj 来表示 cronjob,同时 kubectl set image/env 命令 可以作用在 CronJob 对象上了
控制器模式解析
控制器模式
k8s 项目通过一个称作"控制器模式"(controller pattern)的设计方法,来统一地实现对各种不同的对象或者资源进行的编排操作。
Pod 这个API 对象,实际上就是对容器的进一步抽象和封装而已。
容器镜像虽然好用,但是容器这样一个"沙盒"的概念,对于描述应用来说太过简单。好比,集装箱固然好用,如果它四面都光秃秃的,吊车还怎么把这个集装箱吊起来并摆放好呢?
所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架"吊车",可以更轻松地操作它。
而 k8s 操作这些"集装箱"的逻辑,都由控制器(Controller)完成。
回顾 Deployment 这个最基本的控制器对象。之前讲过一个 nginx-deployment 的例子:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
这个 Deployment 定义的编排动作为:
确保携带了 app=nginx 标签的 Pod 的个数,永远等于 spec.replicas 指定的个数,即 2 个。如果在这个集群中,携带 app=nginx 标签的 Pod 的个数大于 2 的时候,就会有旧的 Pod 被删除;反之,就会有新的 Pod 被创建。
究竟是 Kubernetes 项目中的哪个组件,在执行这些操作呢?
kube-controller-manager 组件:
这个组件,就是一系列控制器的集合
查看所有控制器:
在Kubernetes 项目的 pkg/controller 目录下 //注意:非二进制方式安装的集群找不到此目录
# cd kubernetes/pkg/controller/
# ls -d */
deployment/ job/ podautoscaler/
cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/
cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/
...
这个目录下面的每一个控制器,都以独有的方式负责某种编排功能。而Deployment,正是这些控制器中的一种。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
通用编排模式:控制循环
这些控制器被统一放在 pkg/controller 目录下,是因为它们都遵循 k8s 项目中的一个通用编排模式,即:控制循环(control loop)。
比如,现有一种待编排的对象 X,它有一个对应的控制器。可以用一段 Go 语言风格的伪代码描述这个控制循环:
for {
实际状态 := 获取集群中对象 X 的实际状态(Actual State)
期望状态 := 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
实际状态来源:
实际状态来自于 Kubernetes 集群本身。
比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
期望状态来源:
来自于用户提交的 YAML 文件
比如,Deployment 对象中 Replicas 字段的值。很明显,这些信息往往都保存在 Etcd 中。
以 Deployment 为例,描述它对控制器模型的实现:
1. Deployment 控制器从 Etcd 中获取到所有携带了"app: nginx"标签的 Pod,然后统计它们的数量,这就是实际状态;
2. Deployment 对象的 Replicas 字段的值就是期望状态;
3. Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod
调谐:
一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的"对比"阶段完成的。
这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作"Reconcile Loop"(调谐循环)或者"Sync Loop"(同步循环)。
在其他文档中碰到这些词,它们其实指的都是同一个东西:控制循环。
调谐结果:
调谐的最终结果,往往都是对被控制对象的某种写操作。
比如,增加 Pod,删除已有的 Pod,或者更新 Pod 的某个字段。这也是 Kubernetes 项目"面向 API 对象编程"的一个直观体现。
像 Deployment 这种控制器的设计原理,就是"用一种对象管理另一种对象"的"艺术"。
其中,这个控制器对象本身,负责定义被管理对象的期望状态。比如,Deployment 里的 replicas=2 这个字段。
而被控制对象的定义,则来自于一个"模板"。比如,Deployment 里的 template 字段。
Deployment 这个 template 字段里的内容,跟一个标准的 Pod 对象的 API 定义,丝毫不差。而所有被这个 Deployment 管理的 Pod 实例,都是根据这个 template 字段的内容创建出来的。
像 Deployment 定义的 template 字段,在 k8s 中有一个专有的名字,叫作 PodTemplate(Pod 模板)。
对 Deployment 以及其他类似的控制器,做一个总结:
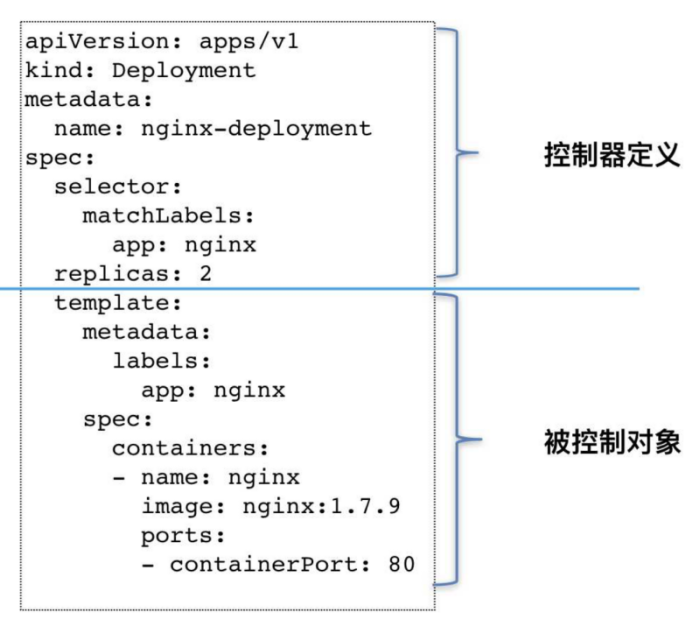
如图,类似 Deployment 的一个控制器,都是由两部分组成:
上半部分的控制器定义(包括期望状态)
下半部分的被控制对象的模板组成的。
这就是为什么,在所有 API 对象的 Metadata 里,都有一个字段叫作 ownerReference,用于保存当前这个 API 对象的拥有者(Owner)的信息。
对于这个 nginx-deployment 来说,它创建出来的 Pod 的 ownerReference 就是 nginx-deployment 吗?或者说,nginx-deployment 所直接控制的,就是 Pod 对象么?
很多不同类型的容器编排功能,比如 StatefulSet、DaemonSet 等等,都有这样一个甚至多个控制器的存在,并遵循控制循环(control loop)的流程,完成各自的编排逻辑。这些控制循环最后的执行结果,要么就是创建、更新一些 Pod(或者其他的 API 对象、资源),要么就是删除一些已经存在的 Pod(或者其他的 API 对象、资源)。
但也正是在这个统一的编排框架下,不同的控制器可以在具体执行过程中,设计不同的业务逻辑,从而达到不同的编排效果。
这个实现思路,正是 k8s 进行容器编排的核心原理。
pod 滚动升级[命令行]
deployment_nginx.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.12.2
ports:
- containerPort: 80
- 创建deployment
kubectl apply -f deployment_nginx.yml
kubectl get deployment
kubectl get rs
kubectl get pods
- deployment信息
可以看到这个deloyment下的详情,nginx是1.12.2
kubectl get deployment -o wide
- deployment的升级
针对目前的nginx1.12升级成1.13的命令,老的下面自动移除了,全部都在新的下面。
kubectl set image deployment nginx-deployment nginx=nginx:1.13 --record # --record 将升级命令记录到历史记录里
kubectl get deployment
kubectl get deployment -o wide
kubectl get pods
- deployment 查看历史版本
kubectl rollout history deployment nginx-deployment
- deployment 回滚到之前的版本
又变成了nginx 1.12.2
kubectl rollout undo deployment nginx-deployment # 回滚到上一版本
kubectl rollout undo deployment nginx-deployment --to-revision=1 # 回滚到指定版本
- deployment 端口暴露
kubectl get node
kubectl get node -o wide
kubectl expose deployment nginx-deployment --port=80 #指定要暴露的端口
#查看node节点暴露的端口
kubectl get svc
rolling update,可以使得服务近乎无缝地平滑升级,即在不停止对外服务的前提下完成应用的更新。
1、replication controller 与 deployment 的区别
1、replication controller
Replication Controller为Kubernetes的一个核心内容,应用托管到Kubernetes之后,需要保证应用能够持续的运行,Replication Controller就是这个保证的key,主要的功能如下:
-
确保pod数量:它会确保Kubernetes中有指定数量的Pod在运行。如果少于指定数量的pod,Replication Controller会创建新的,反之则会删除掉多余的以保证Pod数量不变。
-
确保pod健康:当pod不健康,运行出错或者无法提供服务时,Replication Controller也会杀死不健康的pod,重新创建新的。
-
弹性伸缩 :在业务高峰或者低峰期的时候,可以通过Replication Controller动态的调整pod的数量来提高资源的利用率。同时,配置相应的监控功能(Hroizontal Pod Autoscaler),会定时自动从监控平台获取Replication Controller关联pod的整体资源使用情况,做到自动伸缩。
-
滚动升级:滚动升级为一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定,在初始化升级的时候就可以及时发现和解决问题,避免问题不断扩大。
HPA(Horizontal Pod Autoscaler)是Openshift中的一个非常重要的对象,它定义了系统如何根据收集对应的Pod的状态(CPU/Memory)对DeploymentConfig、ReplicationController对象进行扩容与缩容。 HPA依赖于收集到的Pod资源的使用状态,所以要使HPA生效,Openshift必须安装好cluster metrics应用。 被监控的pod必须设置好了spec.containers.resources.requests属性,HPA才能正常工作。 仅支持CPU/Memory使用率的判断,如果自定义监控项,只能使用经验值,不能使用使用率。 支持对象:DeploymentConfig、ReplicationController、Deployment、Replica Set
2、Deployment
Deployment同样为Kubernetes的一个核心内容,主要职责同样是为了保证pod的数量和健康,90%的功能与Replication Controller完全一样,可以看做新一代的Replication Controller。但是,它又具备了Replication Controller之外的新特性:
-
Replication Controller全部功能:Deployment继承了上面描述的Replication Controller全部功能。
-
事件和状态查看:可以查看Deployment的升级详细进度和状态。
-
回滚:当升级pod镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本。
-
版本记录: 每一次对Deployment的操作,都能保存下来,给予后续可能的回滚使用。
-
暂停和启动:对于每一次升级,都能够随时暂停和启动。
-
多种升级方案:
1、Recreate:删除所有已存在的pod,重新创建新的;
2、RollingUpdate:滚动升级,逐步替换的策略,同时滚动升级时,支持更多的附加参数,例如 设置最大不可用pod数量,最小升级间隔时间等等。
3、deployment的常用命令
查看部署状态
kubectl rollout status deployment/review-demo --namespace=scm
kubectl describe deployment/review-demo --namespace=scm
或者这种写法
kubectl rollout status deployments review-demo --namespace=scm
kubectl describe deployments review-demo --namespace=scm
2、升级
滚动升级通过kubectl rolling-update 命令一键完成。
kubectl set image deployment/review-demo review-demo=library/review-demo:0.0.1 --namespace=scm
或者
kubectl edit deployment/review-demo --namespace=scm
编辑.spec.template.spec.containers[0].image的值
3、终止升级
kubectl rollout pause nginx-deployment
4、继续升级
kubectl rollout resume deployment/review-demo --namespace=scm
5、回滚
kubectl rollout undo deployment/review-demo --namespace=scm
6、查看deployments版本
kubectl rollout history deployments --namespace=scm
回滚到指定版本
kubectl rollout undo deployment/review-demo --to-revision=2 --namespace=scm
7、升级历史
kubectl describe deployment/review-demo --namespace=scm
Name: review-demo
Namespace: scm
CreationTimestamp: Tue, 31 Jan 2017 16:42:01 +0800
Labels: app=review-demo
Selector: app=review-demo
Replicas: 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
OldReplicaSets: <none>
NewReplicaSet: review-demo-2741031620 (3/3 replicas created)
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set review-demo-2741031620 to 1
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set review-demo-1914295649 to 2
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set review-demo-2741031620 to 2
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set review-demo-1914295649 to 1
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set review-demo-2741031620 to 3
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set review-demo-1914295649 to 0
8、deployment文件
# 创建命名空间
kubectl create namespace scm
apiVersion: v1
kind: Namespace
metadata:
name: scm
labels:
name: scm
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-demo
namespace: scm
labels:
app: nginx-demo
spec:
replicas: 3
#minReadySeconds: 60 #这里需要估一个比较合理的值,从容器启动到应用正常提供服务
strategy: # 设置最大不可用 pod 数量,最小升级间隔时间等
rollingUpdate: # 由于replicas 为3,则整个升级,pod 个数在2-4个之间
maxSurge: 1 # 更新时允许最大激增的容器数,默认 replicas 的 1/4 向上取整
maxUnavailable: 1 # 更新时允许最大 unavailable(不可用) 容器数,默认 replicas 的 1/4 向下取整
template:
metadata:
labels:
app: nginx-demo
spec:
terminationGracePeriodSeconds: 60 # k8s 将会给应用发送 SIGTERM(终止进程 软件终止信号)信号,可以用来正确、优雅地关闭应用,默认为30秒
containers:
- name: nginx-demo
image: nginx
imagePullPolicy: IfNotPresent
livenessProbe: # kubernetes认为该pod是存活的,不存活则需要重启
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30 # 容器启动30秒后开始第一次检测
timeoutSeconds: 5 # http检测请求的超时时间
successThreshold: 1 # 检测到有1次成功则认为服务是`检测通过`
failureThreshold: 5 # 检测到有连续5次失败则认为服务是`检测失败`
readinessProbe: # kubernetes认为该pod是启动成功的
httpGet:
path: /
port: 80
scheme: HTTP # 链接格式样式
initialDelaySeconds: 60 # 等于应用程序的最小启动时间
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
resources:
#keep request = limit to keep this container in guaranteed class
requests:
cpu: 50m
memory: 200Mi
limits:
cpu: 500m
memory: 500Mi
env:
- name: PROFILE
value: "test"
ports:
- name: http
containerPort: 80
9、几个重要参数说明
1、maxSurge与maxUnavailable
maxSurge: 1 表示滚动升级时会先启动1个pod
maxUnavailable: 1 表示滚动升级时允许的最大Unavailable的pod个数
由于replicas为3,则整个升级,pod个数在2-4个之间
2、terminationGracePeriodSeconds
k8s将会给应用发送SIGTERM信号,可以用来正确、优雅地关闭应用,默认为30秒。
如果需要更优雅地关闭,则可以使用k8s提供的pre-stop lifecycle hook 的配置声明,将会在发送SIGTERM之前执行。
3、livenessProbe 与 readinessProbe
livenessProbe是kubernetes认为该pod是存活的,不存在则需要kill掉,然后再新启动一个,以达到replicas指定的个数。
readinessProbe是kubernetes认为该pod是启动成功的,这里根据每个应用的特性,自己去判断,可以执行command,也可以进行httpGet。比如对于使用java web服务的应用来说,并不是简单地说tomcat启动成功就可以对外提供服务的,还需要等待spring容器初始化,数据库连接连接上等等。对于spring boot应用,默认的actuator带有/health接口,可以用来进行启动成功的判断。
其中readinessProbe.initialDelaySeconds可以设置为系统完全启动起来所需的最少时间,livenessProbe.initialDelaySeconds可以设置为系统完全启动起来所需的最大时间+若干秒。
这几个参数配置好了之后,基本就可以实现近乎无缝地平滑升级了。对于使用服务发现的应用来说,readinessProbe可以去执行命令,去查看是否在服务发现里头应该注册成功了,才算成功。
示例:假设现在运行的redis-master的pod是1.0版本,现在需要升级到2.0版本。
创建redis-master-controller-v1.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master-v1
labels:
name: redis-master
version: v1
spec:
replicas: 1
selector:
name: redis-master
version: v1
template:
metadata:
labels:
name: redis-master
version: v1
spec:
containers:
- name: master
image: kubeguide/redis-master:1.0
ports:
- containerPort: 6379
创建redis-master-controller-v2.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master-v2
labels:
name: redis-master
version: v2
spec:
replicas: 1
selector:
name: redis-master
version: v2
template:
metadata:
labels:
name: redis-master
version: v2
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
更新:
kubectl rolling-update redis-master-v1 -f redis-master-controller-v2.yaml
需要注意到是:
rc 的名字(name)不能与旧的rc的名字相同
在selector中至少有一个Label与旧的Label不同。以标识其为新的RC
网络策略说明一组 Pod 之间是如何被允许互相通信,以及如何与其它网络 Endpoint 进行通信。 NetworkPolicy 资源使用标签来选择 Pod,并定义了一些规则,这些规则指明允许什么流量进入到选中的 Pod 上。
pod 滚动升级二[yaml文件]
1、升级
第一次部署时使用 httpd:2.2.31,然后更新到 httpd:2.2.32。
httpd.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd
spec:
replicas: 3
selector:
matchLabels:
run: httpd
template:
metadata:
labels:
run: httpd
spec:
containers:
- name: httpd
image: httpd:2.2.31
ports:
- containerPort: 80
启动:
kubectl apply -f httpd.yml
查看:
kubectl get deployments httpd -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
httpd 3/3 1 3 24m httpd httpd:2.2.31 run=httpd
IMAGES为 httpd:2.2.31。
把配置文件中的 httpd:2.2.31 改为 httpd:2.2.32,再次启动:
kubectl apply -f httpd.yml
查看:
kubectl get deployments httpd -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
httpd 3/3 1 3 26m httpd httpd:2.2.32 run=httpd
IMAGES 变为 httpd:2.2.32。
查看 deployment httpd 的详细信息:
kubectl describe deployments httpd
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Normal ScalingReplicaSet 3m33s deployment-controller Scaled up replica set httpd-94c4dcb56 to 1
Normal ScalingReplicaSet 2m48s deployment-controller Scaled down replica set httpd-8c6c4bd9b to 2
Normal ScalingReplicaSet 2m48s deployment-controller Scaled up replica set httpd-94c4dcb56 to 2
Normal ScalingReplicaSet 2m43s deployment-controller Scaled down replica set httpd-8c6c4bd9b to 1
Normal ScalingReplicaSet 2m43s deployment-controller Scaled up replica set httpd-94c4dcb56 to 3
Normal ScalingReplicaSet 2m38s deployment-controller Scaled down replica set httpd-8c6c4bd9b to 0
上面的日志信息就描述了滚动升级的过程:
- 启动一个新版 pod
- 把旧版 pod 数量降为 2
- 再启动一个新版,数量变为 2
- 把旧版 pod 数量降为 1
- 再启动一个新版,数量变为 3
- 把旧版 pod 数量降为 0
这就是滚动的意思,始终保持副本数量为3,控制新旧 pod 的交替,实现了无缝升级。
2、回滚
kubectl apply 每次更新应用时,kubernetes 都会记录下当前的配置,保存为一个 revision,这样就可以回滚到某个特定的版本。
创建3个配置文件,内容中唯一不同的就是镜像的版本号。
httpd.v1.yml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: httpd
spec:
revisionHistoryLimit: 10 # 指定保留最近的几个revision
replicas: 3
template:
metadata:
labels:
run: httpd
spec:
containers:
- name: httpd
image: httpd:2.2.34
ports:
- containerPort: 80
httpd.v2.yml
...
image: httpd:2.4.10
...
httpd.v3.yml
...
image: httpd:2.4.11
...
部署:
kubectl apply -f /vagrant/httpd.v1.yml --record
kubectl apply -f /vagrant/httpd.v2.yml --record
kubectl apply -f /vagrant/httpd.v3.yml --record
--record 的作用是将当前命令记录到 revision 中,可以知道每个 revision 对应的是哪个配置文件。
查看 deployment:
kubectl get deployments -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES
httpd 0/3 1 0 4m4s httpd httpd:2.4.12
查看 revision 历史记录:
kubectl rollout history deployment httpd
deployment.extensions/httpd
REVISION CHANGE-CAUSE
1 kubectl apply --filename=httpd.v1.yml --record=true
2 kubectl apply --filename=httpd.v2.yml --record=true
3 kubectl apply --filename=httpd.v3.yml --record=true
CHANGE-CAUSE 就是 --record 的结果。
回滚到 revision 1:
kubectl rollout undo deployment httpd --to-revision=1
再查看 deployment:
kubectl get deployments -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES
httpd 0/3 1 0 4m4s httpd httpd:2.2.34
版本已经回退了。
查看 revision 历史记录:
kubectl rollout history deployment httpd
deployment.extensions/httpd
REVISION CHANGE-CAUSE
2 kubectl apply --filename=httpd.v2.yml --record=true
3 kubectl apply --filename=httpd.v3.yml --record=true
4 kubectl apply --filename=httpd.v1.yml --record=true
revision 记录也发生了变化。
pod 权限管理 RBAC[理解]
K8s 在 1.3 版本中发布了alpha版的基于角色的访问控制 RBAC (Role-based Access Control)的授权模式。相对于基于属性的访问控制 ABAC(Attribute-based Access Control),RBAC主要是引入了角色(Role)和角色绑定(RoleBinding)的抽象概念。在ABAC中,K8s集群中的访问策略只能跟用户直接关联;而在RBAC中,访问策略可以跟某个角色关联,具体的用户在跟一个或多个角色相关联。
RBAC 引入了 4 个新的顶级资源对象 :Role、ClusterRole、RoleBinding和 ClusterRoleBinding。 同其他 API 资源对象 一样,用户可以使用 kubectl 或者 API 调用等方式操作这些资源对象。

新的 RBAC 具有如下优势。
- 对集群中的资源和非资源权限均有完整的覆盖。
- 整个
RBAC完全由 几个API对象完成,同其他API对象一样 ,可以用kubectl或API进行操作。 - 可以在运行时进行调整,无须重新启动 API Server。
- 要使用 RBAC 授权模式 ,则 需要在 API Server 的启动 参数中 加上
--authorization-mode=RBAC。
1、角色( Role)
一个角色就是一组权限的集合,这里的权限都是许可形式的,不存在拒绝的规则。在一个命名空间中,可以用角色来定义一个角色,如果是集群级别的,就需要使用ClusterRole了。角色只能对命名空间内的资源进行授权,下面例子中定义的角色具备读取Pod的权限:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" 空字符串,标明 core API 组
resources: ["pods"]
verbs: ["get", "watch", "list"]
rules 中的参数说明如下。
- apiGroups: 支持的API组列表,例如 “apiVersion: batch/v1”、“apiVersion: extensions/v1beta1”、“apiVersion:apps/v1beta1” 等。
- resources: 支持的资源对象列表,例如 pods、 deployments、 jobs等。
- verbs: 对资源对象 的操作方法列表 , 例如 get、 watch、 list、 delete、 replace、 patch 等
2、集群角色(ClusterRole)
集群角色除了具有和角色一致的命名空间内资源的管理能力,因其集群级别的生效范围,还可以用于以下特殊元素的授权管理上:
- 集群范围的资源,如 Node。
- 非资源型的路径,如 “/healthz”。
- 包含全部命名空间的资源,例如
pods(用于kubectl get pods --all-namespaces这样的操作授权)
下面的集群角色可以让用户有权访问任意一个或所有命名空间的 secrets(视其绑定方式而定):
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" 被忽略,因为 ClusterRoles 不受名字空间限制
name: secret-reader
rules:
- apiGroups: [""]
# 在 HTTP 层面,用来访问 Secret 对象的资源的名称为 "secrets"
resources: ["secrets"]
verbs: ["get", "watch", "list"]
3、角色绑定(RoleBinding)和 集群角色绑定(ClusterRoleBinding)
角色绑定或集群角色绑定用来把一个角色绑定到一个目标上,绑定目标可以是User(用户)、Group(组)或者Service Account。使用RoleBinding可以为某个命名空间授权,使用ClusterRoleBinding可以为集群范围内授权。
RoleBinding 可以引用 Role 进行授权。下例中的 RoleBinding 将在 default 命名空间中把 pod-reader 角色授予用户 jane,这一操作让 jane 可以读取 default命名空间中的 Pod:
apiVersion: rbac.authorization.k8s.io/v1
# 此角色绑定允许 "jane" 读取 "default" 名字空间中的 Pods
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
# 你可以指定不止一个“subject(主体)”
- kind: User
name: jane # "name" 是不区分大小写的
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" 指定与某 Role 或 ClusterRole 的绑定关系
kind: Role # 此字段必须是 Role 或 ClusterRole
name: pod-reader # 此字段必须与你要绑定的 Role 或 ClusterRole 的名称匹配
apiGroup: rbac.authorization.k8s.io
1、RoleBinding 也可以引用 ClusterRole进行授权
RoleBinding 可以引用 ClusterRole,对属于同一命名空间内 ClusterRole 定义的资源主体进行授权。一种很常用的做法就是,集群管理员为集群范围预定义好一组角色(ClusterRole),然后在多个命名空间中重复使用这些ClusterRole。这样可以大幅提高授权管理工作效率,也使得各个命名空间下的基础性授权规则与使用体验保持一致。
例如下面,虽然 secret-reader 是一个集群角色,但是因为使用了RoleBinding,所以 dave 只能读取 development 命名空间中的 secret。
apiVersion: rbac.authorization.k8s.io/v1
# 此角色绑定使得用户 "dave" 能够读取 "default" 名字空间中的 Secrets
# 你需要一个名为 "secret-reader" 的 ClusterRole
kind: RoleBinding
metadata:
name: read-secrets
# RoleBinding 的名字空间决定了访问权限的授予范围。
# 这里仅授权在 "development" 名字空间内的访问权限。
namespace: development
subjects:
- kind: User
name: dave # 'name' 是不区分大小写的
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
ClusterRoleBinding,集群角色绑定中的角色只能是集群角色。用于进行集群级别或者对所有命名空间都生效的授权。
下面的例子中允许 manager 组的用户读取任意 namespace 中的 secret:
apiVersion: rbac.authorization.k8s.io/v1
# 此集群角色绑定允许 “manager” 组中的任何人访问任何名字空间中的 secrets
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager # 'name' 是不区分大小写的
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
下图展示了上述对 Pod 的 get/watch/list 操作进行授权的 Role 和 RoleBinding 逻辑关系。
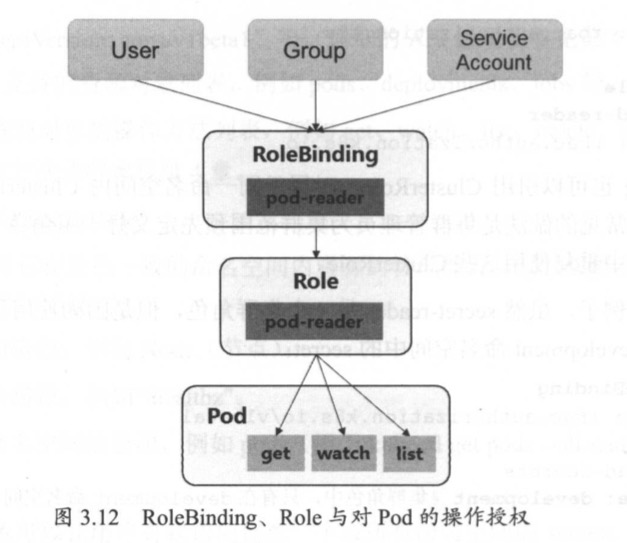
2、对资源的引用方式
多数资源可以用其名称的字符串来表达,也就是Endpoint中的URL相对路径,例如pods。然而,某些k8s API包含下级资源,例如Pod的日志(logs)。Pod日志的Endpoint是GET/api/v1/namespaces/{namespace}/pods/{name}/log。
在这个例子中,Pod 是一个命名空间内的资源,log 就是一个下级资源。要在 RBAC 角色中体现,则需要用斜线“/”来分隔资源和下级资源。
若想授权让某个主体同时能够读取 Pod 和 Pod log,则可以配置 resources 为一个数组:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: default
name: pod-and-pod-logs-reader
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "list"]
资源还可以通过名字(ResourceName)进行引用(这里指的是资源实例的名子)。在指定ResourceName后,使用get、delete、update和patch动词的请求,就会被限制在这个资源实例的范围内。
例如下面的声明让一个主体只能对一个configmap进行get和update操作:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: default
name: configmap-updater
rules:
- apiGroups: [""]
resources: ["configmap"]
resourceNames: ["my-configmap"]
verbs: ["update", "get"]
可想而知,resourceName这种用法对list、watch、create或deletecollection操作是无效的。这是因为必须要通过URL进行鉴权,而资源名称在list、watch、create或deletecollection请求中只是请求Body数据的一部分。
3、常用的角色(Role)示例
下面的例子只展示了rules部分的内容。
(1)允许读取核心API组中的Pod资源
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
(2)允许读写"extensions"和"apps"两个API组中的"deployments"资源
rules:
- apiGroups: ["extensions", "apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
(3)允许读取"pods"及读写"jobs"
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
- apiGroups: ["batch", "extensions"]
resources: ["jobs"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
(4)允许读取一个名为"my-config"的ConfigMap(必须绑定到一个RoleBinding来限制到一个namespace下的ConfigMap)
rules:
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["my-config"]
verbs: ["get"]
(5)读取核心组的"node"资源(Node属于集群级的资源,所以必须存在于ClusterRole中,并使用ClusterRoleBinding进行绑定)
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
(6)允许对非资源端点/healthz及其所有子路径进行GET和POST操作(必须使用ClusterRole和ClusterRoleBinding)
rules:
- nonResourceURLs: ["/healthz", "/healthz/*"]
verbs: ["get", "post"]
4、常用的角色绑定(RoleBinding)示例
注意,下面的例子中只包含subjects部分的内容。
(1)用户名"alice@example.com"
subjects:
- kind: User
name: "alice@example.com"
apiGroup: rbac.authorization.k8s.io
(2)组名"frontend-admins"
subjects:
- kind: Group
name: "frontend-admins"
apiGroup: rbac.authorization.k8s.io
(3)kube-system命名空间中的默认Service Account
subjects:
- kind: ServiceAccount
name: default
namespace: kube-system
(4)"qa"命名空间中的所有Service Account
subjects:
- kind: Group
name: system:serviceaccounts:qa
apiGroup: rbac.authorization.k8s.io
(5)所有Service Account
subjects:
- kind: Group
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
(6)所有认证用户(v1.5版本以上)
subjects:
- kind: Group
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
(7)所有未认证用户(v1.5版本以上)
subjects:
- kind: Group
name: system:unauthenticated
apiGroup: rbac.authorization.k8s.io
(8)全部用户(v1.5版本以上)
subjects:
- kind: Group
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
- kind: Group
name: system:unauthenticated
apiGroup: rbac.authorization.k8s.io
5、默认的角色和角色绑定
API Server 创建了一系列的默认 ClusterRole 和 ClusterRoleBinding 对象, 其中许多对象以 “system:” 前缀开头,代表其中绑定的资源是作为基础设施适用和占有的。修改这些资源会导致整个集群不可用。一个例子是 system:node 。这个ClusterRole角色拥有一系列的kubelet权限,如果这个集群角色被修改了,可能会让kubelet出现异常。
所有默认的集群角色 (ClusterRole) 和其角色绑定(role binding)都带有如下标记
kubernetes.io/bootstrapping=rbac-defaults
下面对一些常见的默认ClusterRole和ClusterRoleBinding对象进行说明。
4、对系统角色的说明如下表所示
| 默认的 ClusterRole | 默认的 ClusterRoleBinding | 描述 |
|---|---|---|
| system:basic-user | system:authenticated和system:unauthenticated组 | 让用户能够读取自身的信息 |
| system:discovery | system:authenticated和system:unauthenticated组 | 对API发现Endpoint的只读访问,用于API级别的发现和协商 |
1、对用户角色的说明如下表所示:
| 默认的ClusterRole | 默认的ClusterRoleBinding | 描述 |
|---|---|---|
| cluster-admin | system:masters组 | 让超级用户可以对任何资源执行任何操作。如果在ClusterRoleBinding中使用,则影响的是整个集群的所有namespace中的任何资源;如果使用的是RoleBinding,则能控制这一绑定的namespace中的资源,还包括namespace本身。 |
| cluster-status | None | 可以对基础集群状态信息进行只读访问。 |
| admin | None | 允许admin访问,可以限制在一个namespace中使用RoleBinding。如果在RoleBinding中使用,则允许对namespace中大多数资源进行读写访问,其中包含创建角色和角色绑定的能力。这一角色不允许操作namespace本身,也不能写入资源限额。 |
| edit | None | 允许对命名空间内的大多数资源进行读写操作,不允许查看或修改角色,以及角色绑定。 |
| view | None | 允许对多数对象进行只读操作,但是对角色、角色绑定及secret是不可访问的。 |
注:有些默认角色不是以"system:"为前缀的,这部分角色是针对用户的。其中包含超级用户角色(cluster-admin),有的用于集群一级的角色(cluster-staus),还有针对namespace的角色(admin,edit,view)。
2、对核心Master组件角色的说明如下表所示
| 默认的ClusterRole | 默认的ClusterRoleBinding | 描述 |
|---|---|---|
| system:kube-scheduler | system:kube-scheduler用户 | 能够访问kube-scheduler组件所需的资源 |
| system:kube-controller-manager | system:kube-controller-manager用户 | 能够访问kube-controller-manager组件所需的资源,不同的控制所需的不同权限参见下表。 |
| system:node | system:nodes组 | 允许访问kubelet所需的资源,包括对secret的读取,以及对Pod的写入。未来会把上面的两个权限限制在分配到本Node的对象上。今后的鉴权过程,kubelet必须以system:node及一个system:node形式的用户名进行。参看https://pr.k8s.io/40476 |
| system:node-proxier | system:kube-proxy用户 | 允许访问kube-proxy所需的资源 |
| system:kube-scheduler | system:kube-scheduler用户 | 能够访问kube-scheduler组件所需的资源 |
3、对其他组件角色的说明如下表所示
| 默认的ClusterRole | 默认的ClusterRoleBinding | 描述 |
|---|---|---|
| system:auth-delegator | None | 允许对授权和认证进行托管,通常用于附加的API服务器 |
| system:heapster | None | Heapster组件的角色 |
| system:kube-aggregator | None | kube-aggregator的角色 |
| system:kube-dns | 在kube-system namespace中kube-dns的Service Account | kube-dns角色 |
| system:node-bootstrapper | None | 允许访问kubelet TLS启动所需的资源 |
| system:node-problem-detector | None | 允许访问node-problem-detector组件所需的资源 |
| system:persistent-volume-provisioner | None | 允许访问多数动态卷供给所需的资源 |
4、对 Controller 角色的说明如下表所示
| Controller角色 | |
|---|---|
| system:controller:attachdetach-controller | |
| system:controller:certificate-controller | |
| system:controller:cronjob-controller | |
| system:controller:daemon-set-controller | |
| system:controller:deployment-controller | |
| system:controller:disruption-controller | |
| system:controller:endpoint-controller | |
| system:controller:generic-garbage-collector | |
| system:controller:horizontal-pod-autoscaler | |
| system:controller:job-controller | |
| system:controller:namespace-controller | |
| system:controller:node-controller | |
| system:controller:persistent-volume-binder | |
| system:controller:pod-garbage-collector | |
| system:controller:replicaset-controller | |
| system:controller:replication-controller | |
| system:controller:route-controller | |
| system:controller:service-account-controller | |
| system:controller:service-controller | |
| system:controller:statefulset-controller | |
| system:controller:ttl-controller |
K8s Controller Manager负责的是核心控制流。如果启用--user-service-account-credentials,则每个控制过程都会使用不同的Service Account启动。因此就有了对应各个控制过程的角色,前缀是system:controller。如果未启用这一功能,则将使用各自的凭据运行各个控制流程,这就需要为该凭据授予所有相关角色。
5、授权注意事项:预防提权和授权初始化
RBAC API拒绝用户利用编辑角色或者角色绑定的方法进行提权。这一限制是在API层面做出的,因此即使RBAC没有启动也仍然有效。
用户只能在拥有一个角色的所有权限,且与该角色的生效范围一致的前提下,才能对角色进行创建和更新。要让一个用户能够创建或更新角色,需要:
- 为其授予一个允许创建/更新Role或ClusterRole资源对象的角色;
- 为用户授予角色,要覆盖该用户所能控制的所有权限范围。用户如果尝试创建超出其自身权限的角色或集群角色,则该API调用会被禁止。
如果一个用户的权限包含了一个角色的所有权限,那么就可以为其创建和更新角色绑定。或者如果被授予了针对某个角色的绑定授权,则也有权完成此操作。
要使用户能够创建、更新这一角色绑定或者集群角色绑定的角色,需要有如下做法:
- 为其授予一个允许其创建和更新角色绑定或者集群角色绑定的角色;
- 为其授予绑定某一角色的权限。
需要注意的是,在进行第1个角色绑定时,必须让初始用户具备其尚未被授予的权限,要进行初始的角色和角色绑定设置,有以下两种办法:
- 使用属于system:masters组的身份,这一群组默认具有cluster:admin这一超级角色的绑定。
- 如果API Server以–insecure-port参数运行,则客户端通过这个非安全端口进行接口调用,这一端口没有认证鉴权的限制。
6、对 Service Account 的授权管理
默认的RBAC策略为控制平台组件、节点和控制器授予有限范围的权限,但是在"kube-system"之外的Service Account是没有任何权限的。除了所有认证用户都具有的discovery权限。
在使用中,要求用户为Service Account赋予所需的权限。细粒度的角色分配能够提高安全性,但也会提高管理成本。粗放的授权方式可能会给Service Account多余的权限,但会更易于管理。
下面的实践以安全性递减的方式排序。
(1)为一个应用专属的Service Account赋权(最佳实践)
这个应用需要在Pod的Spec中指定一个serviceAccountName,用API、Application Manifest、kubectl create serviceaccount命令等创建Service Account,例如为"my-namespace"中的"my-sa"Service Account授予只读权限:
kubectl create rolebinding my-sa-view --clusterrole=view --serviceaccount=my-namespace:my-sa --namespace=my-namespace
(2)为一个命名空间中的"default" Service Account授权
如果一个应用没有指定serviceAccountName,则会使用"default" Service Account。注意:赋给"default" Service Account的权限会让所有没指定serviceAccountName的Pod都具有这些权限。
例如在"my-namespace"命名空间里为"default" Service Account授予只读权限:
kubectl create rolebinding default-view --clusterrole=view --serviceaccount=my-namespace:default --namespace=my-namespace
目前不少Add-Ons在"kube-system"命名空间中用"default" Service Account运行。要让这些Add-Ons能够使用超级用户权限,则可以把cluster-admin权限赋予"kube-system"的"default" Service Account。
注意:这一操作意味着"kube-system"命名空间包含了通向API超级用户的一个捷径!
kubectl create clusterrolebinding add-on-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default
(3)为命名空间内的所有Service Account授予一个角色
例如,为"my-namespace"命名空间中的所有Service Account赋予只读权限:
kubectl create rolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts:my-namespace --namespace=my-namespace
(4)为集群范围内的所有Service Account授予一个低权限角色
例如,为所有命名空间中的所有Service Account授予只读权限:
kubectl create clusterrolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts
(5)为所有Service Account授予超级用户权限(非常危险)
kubectl create clusterrolebinding serviceaccouns-cluster-admin --clusterrole=cluster-admin --group=system:serviceaccounts
8)使用kubectl 命令工具创建资源对象
除了使用yaml配置文件来创建这些资源对象,也可以直接使用kubectl工具对它们进行创建。
下面通过几个例子进行说明。
(1)在命名空间acme内为用户bob授权admin ClusterRole
kubectl create rolebinding bob-admin-binding --clusterrole=admin --user=bob --namespace=acme
(2)在命名空间acme内为名为myapp的Service Account授予view ClusterRole
kubectl create rolebinding myapp-view-binding --clusterrole=view --serviceaccount=acme:myapp --namespace=acme
(3)在全集群范围内为用户root授权cluster-admin ClusterRole
kubectl create clusterrolebinding root-cluster-admin-binding --clusterrole=cluster-admin --user=root
(4)在全集群范围内为用户kubelet授予system:node ClusterRole
kubectl create clusterrolebinding kubelet-node-binding --clusterrole=system:node --user=kubelet
(5)在全集群范围内为名为myapp的Service Account授予view ClusterRole
kubectl create clusterrolebinding myapp-view-binding --clusterrole=view --serviceaccount=acme:myapp
9)RBAC的Auto-reconciliation(自动恢复)功能
自动恢复从k8s v1.6版本开始引入,每次启动时,API Server都会更新默认的集群角色的缺失权限,也会刷新默认的角色绑定中缺失的主体,以防止一些破坏性的修改,保证在集群升级的情况下,相关内容也能够及时更新。
如果不希望使用这一功能,则可以将一个默认的集群角色(ClusterRole)或者角色绑定(RoleBinding)的Annotation注解"rbac.authorization.kubernetes.io/autoupdate"值设置为false。
10)从旧版本的授权策略升级到RBAC
在k8s v1.6之前,很多Deployment都使用了比较宽松的ABAC策略,包含为所有Service Account开放完全API访问。
而默认的RBAC策略是为控制台组件、节点和控制器授予了范围受限的权限,且不会为"kube-system"以外的Service Account授予任何权限。
这样一来,可能会对现有的一些工作负载造成影响,有两种办法来解决这一问题:
(1)并行认证。RBAC和ABAC同时进行,并包含传统的ABAC策略:
--authorization-mode=RBAC,ABAC --authorization-policy-file=mypolicy.jsonl
首先会由RBAC尝试对请求进行鉴权,如果未通过,那么就轮到ABAC生效。这样所有的应用只要满足RBAC或ABAC之一即可工作。
通过输出更详细的日志信息,查看以上鉴权过程和结果。直到某一天,再也不输出RBAC鉴权失败的日志了,就可以移除ABAC了。
(2)粗放管理
可以使用RBAC的角色绑定,复制一个粗话的策略。
下面的策略会让所有Service Account都具备了集群管理员权限,所有容器运行的应用都会自动接收到Service Account的认证,能够对任何API做任何事情,包括查看Secret和修改授权。这一策略无疑是比较凶险的。
$ kubectl create clusterrolebinding permissive-binding --clusterrole=cluster-admin --user=admin --user=kubelet --group=system:serviceaccounts
=测试=
创建用户
# useradd tiger
# cd /home/tiger/
1、创建一个私钥
# openssl genrsa -out tiger.key 2048
2、用私钥创建一个CSR
# openssl req -new -key tiger.key -out tiger.csr -subj "/CN=tiger"
3、用这个cluster的CA 生成一个签名 [注意证书位置]
# openssl x509 -req -in tiger.csr -CA /etc/kubernetes/pki/ca.crt \
-CAkey /etc/kubernetes/pki/ca.key \
-CAcreateserial \
-out tiger.crt -days 45
4、创建config文件
# mkdir /home/tiger/.kube
# vim /home/tiger/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority: /etc/kubernetes/pki/ca.crt
server: https://10.3.148.12:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: default
user: tiger
name: tiger@kubernetes
current-context: tiger@kubernetes
kind: Config
preferences: {}
users:
- name: tiger
user:
client-certificate: /home/tiger/tiger.crt
client-key: /home/tiger/tiger.key
5、创建角色并绑定user
6、测试权限
kubectl auth can-i list pod -n default
或者
kubectl get po -n default --kubeconfig=./.kube/config
HPA实现应用横向扩展
手动扩缩容
kubectl scale
扩容或缩容 Deployment、ReplicaSet、Replication Controller或 Job 中Pod数量。
scale也可以指定多个前提条件,如:当前副本数量或 --resource-version ,
进行伸缩比例设置前,系统会先验证前提条件是否成立。
语法
$ scale [--resource-version=version] [--current-replicas=count] --replicas=COUNT (-f FILENAME | TYPE NAME)
示例
将名为foo中的pod副本数设置为3。
kubectl scale --replicas=3 rs/foo
将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3。
kubectl scale --replicas=3 -f foo.yaml
如果当前副本数为2,则将其扩展至3。
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
设置多个RC中Pod副本数量。
kubectl scale --replicas=5 rc/foo rc/bar rc/baz
Kubernetes平台上应用的自动化横着扩展(水平自动伸缩)是通过HPA(Horizontal Pod Autoscaler)来实现的,基于观测CPU使用率(v1版本,v2beta版本也支持memory或者其他自定义性能属性),当业务负载上升超过HPA设定值,创建新的POD保障业务对资源的需求,当负载下降后可以通过销毁POD释放资源来提高利用率。
HPA控制器的工作流程(V1版本)
更详细的介绍参考官方文档 Horizontal Pod Autoscaler
- 流程
- 创建HPA资源对象,关联对应资源例如Deployment,设定目标CPU使用率阈值,最大,最小replica数量。 前提:pod一定要设置资源限制,参数request,HPA才会工作。
- HPA控制器每隔15秒钟(可以通过设置controller manager的–horizontal-pod-autoscaler-sync-period参数设定,默认15s)通过观测metrics值获取资源使用信息
- HPA控制器将获取资源使用信息与HPA设定值进行对比,计算出需要调整的副本数量
- 根据计算结果调整副本数量,使得单个POD的CPU使用率尽量逼近期望值,但不能超过设定的最大,最小值。
- 以上2,3,4周期循环
- 周期
- HPA控制器观测资源使用率并作出决策是有周期的,执行是需要时间的,在执行自动伸缩过程中metrics不是静止不变的,可能降低或者升高,如果执行太频繁可能导致资源的使用快速抖动,因此控制器每次决策后的一段时间内不再进行新的决策。对于扩容这个时间是3分钟,缩容则是5分钟,对应调整参数
--horizontal-pod-autoscaler-downscale-delay
--horizontal-pod-autoscaler-upscale-delay
- 自动伸缩不是一次到位的,而是逐渐逼近计算值,每次调整不超过当前副本数量的2倍或者1/2 本记录是对kubernetes HPA功能的验证,参考kubernetes官方文档,使用的是官方文档提供的镜像php-apache进行测试。
metrics server
kubernetes集群需要配置好metrics server 参考kuboard的方案
docker镜像服务器
因文档中测试镜像 php-apache 的获取需要梯子,所以镜像下载下来放在私有服务器上。
当然也可以自己制作镜像,保存在本地进行测试
为了演示Horizontal Pod Autoscaler,我们将使用基于php-apache镜像的自定义docker镜像。Dockerfile具有以下内容:
FROM daoloud.io/library/php:5-apache
ADD index.php /var/www/html/index.php
RUN chmod a+rx index.php
它定义了一个index.php页面,该页面执行一些CPU密集型计算:
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
docker build -t tigerfive/php-apache-for-hpa:v1
当然也可以使用 mirrorgooglecontainers/hpa-example:latest 这个镜像也可使用
配置HPA实现应用横向扩展
创建deployment,并将服务映射出来:
application/php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: tigerfive/php-apache-for-hpa:v1
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
运行下列命令:
# kubectl apply -f php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
配置hpa:php-apache-hpa
官方创建方式:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
yaml方式
cat php-apache-hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache-hpa
labels:
app: hpa-test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
创建并检查 autoscaler 运行状态
# kubectl apply -f php-apache-hpa.yaml
horizontalpodautoscaler.autoscaling/php-apache-hpa created
[root@k8s-1 HPA]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache-hpa Deployment/php-apache 0%/50% 1 10 1 17s
压力测试,观察HPA效果
产生压测客户端
# kubectl run --generator=run-pod/v1 -it --rm load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ #
/ # while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK
观察压测效果
Within a minute or so, we should see the higher CPU load by executing:
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache-hpa Deployment/php-apache 250%/50% 1 10 1 5m37s
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache-hpa Deployment/php-apache 53%/50% 1 10 5 6m41s
# kubectl describe hpa php-apache-hpa
Name: php-apache-hpa
Namespace: default
Labels: app=hpa-test
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"autoscaling/v1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"labels":{"app":"hpa-test"},"name":"php-apach...
CreationTimestamp: Fri, 28 Feb 2020 01:09:02 +0800
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 50% (101m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 5 current / 5 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 2m30s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 2m15s horizontal-pod-autoscaler New size: 5; reason: cpu resource utilization (percentage of request) above target
结论:随着压力测试进行,deployment下pod的CPU使用率增加,超过HPA设定的百分比50%,之后逐次翻倍扩容replicaset。达到上限停止扩容。根据replicaset设置的request QoS逐渐稳定资源的使用率。
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache-hpa Deployment/php-apache 53%/50% 1 10 5 8m42s
停止压测
# while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
OK!OK!OK!OK!OK!OK!OK!OK!^C
/ # exit
Session ended, resume using 'kubectl attach load-generator -c load-generator -i -t' command when the pod is running
pod "load-generator" deleted
CPU使用率恢复到最初值20%,controller会周期观测,逐次缩容到最小值。
#再次等待几分钟后(默认5分钟),
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 5/5 5 5 17m
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache-hpa Deployment/php-apache 0%/50% 1 10 1 15m
#再次等待几分钟后(默认5分钟),稳定在最小副本数量
# kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 21m
其他
以上测试验证了HPA功能,使用的API版本是autoscaling/v1。通过kubectl api-versions可以查看到存在3个版本。v1版本只支持CPU,v2beta2版本支持多metrics(CPU,memory)以及自定义metrics。基于autoscaling/v2beta2的hpa yaml文件写法
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache-hpa
labels:
app: hpa-test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
请注意,该targetCPUUtilizationPercentage字段已被称为metrics的数组替换。CPU利用率度量是资源度量,因为它表示为Pod容器上指定的资源的百分比。 请注意,您可以指定除CPU之外的其他资源指标。默认情况下,唯一受支持的其他资源指标是内存。这些资源不会在群集之间更改名称,只要metrics.k8s.ioAPI 可用,这些资源就应该始终可用。
更多用法请参考官网
玩转 Service
Service 是 Kubernetes 的核心概念,通过创建 Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端各个容器应用上。接下来对 Service 的使用进行详细说明,包括Service的负载均衡机制、如何访问 Service、Headless、Service、DNS 服务的机制和实践、Ingress 7层路由机制等。
1. Service 定义详解
YAML 格式的 Service 定义文件的完整内容如下:
apiVersion: v1 //Required
kind: Service //Required
metadata: //Required
name: string //Required
namespace: string //Required
labels:
- name: string
annotations:
- name: string
spec: //Required
selector: [] //Required
type: string //Required
clusterIP: string
sessionAffinity: string
ports:
- name: string
protocol: string
port: int
targetPort: int
nodePort: int
status:
loadBalancar:
ingerss:
ip: string
hostname: string
对各属性的说明如表4.1所示。
对Service的定义文件模板的各属性的说明
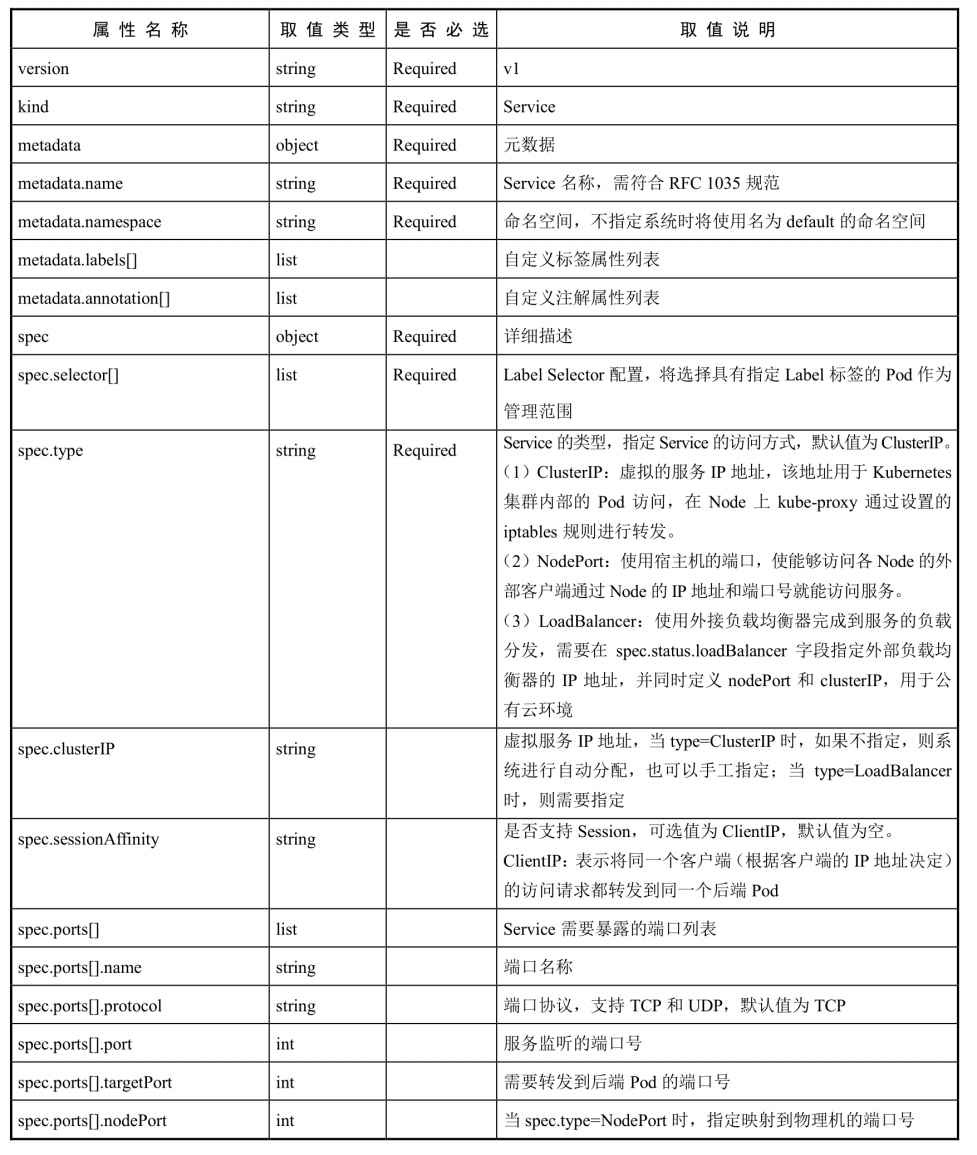
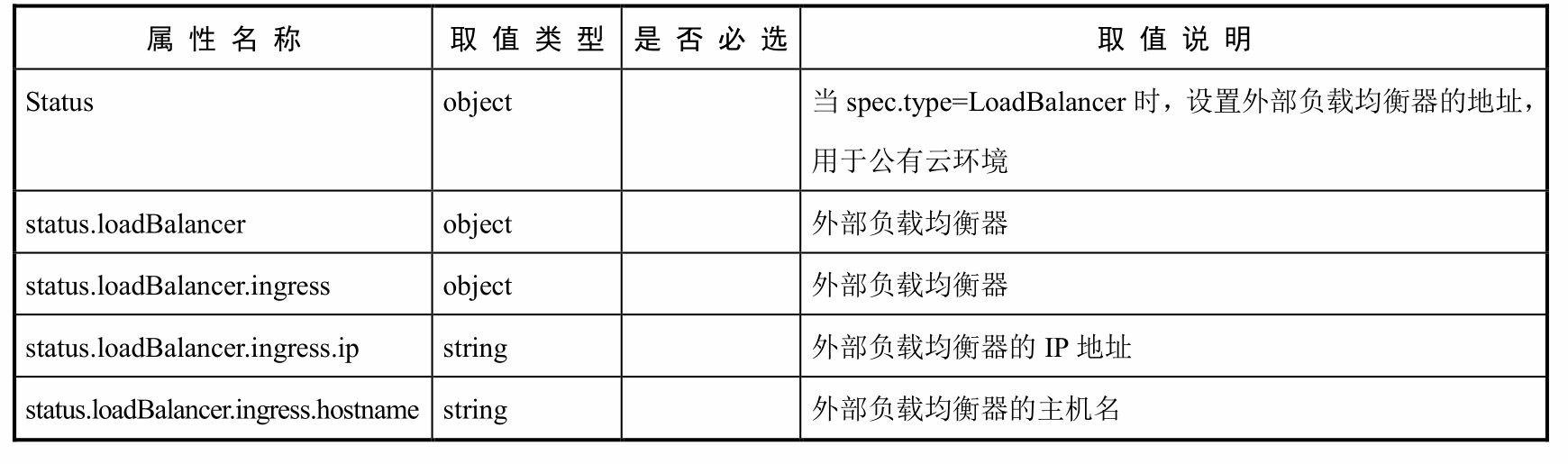
2. Service 基本用法
一般来说,对外提供服务的应用程序需要通过某种机制来实现,对于容器应用最简便的方式就是通过TCP/IP机制及监听IP和端口号来实现。例如,定义一个提供Web服务的RC,由两个nginx容器副本组成,每个容器都通过containerPort设置提供服务的端口号为8080:
# vim webapp-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: webapp
spec:
replicas: 2
template:
metadata:
name: webapp
labels:
app: webapp
spec:
containers:
- name: webapp
image: nginx:1.10
ports:
- containerPort: 80
创建RC:
# kubectl apply -f webapp-rc.yaml
replicationcontroller/webapp created
获取Pod的IP地址
kubectl get po -l app=webapp -o yaml |grep " podIP:"
podIP: 10.244.2.5
podIP: 10.244.1.7
可以直接通过这两个Pod的IP地址和端口号访问Tomcat服务:
# curl 10.244.2.5:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
# curl 10.244.1.7:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
直接通过Pod的IP地址和端口号可以访问到容器应用内的服务,但是Pod的IP地址是不可靠的,例如当Pod所在的Node发生故障时,Pod将被Kubernetes重新调度到另一个Node,Pod的IP地址将发生变化。更重要的是,如果容器应用本身是分布式的部署方式,通过多个实例共同提供服务,就需要在这些实例的前端设置一个负载均衡器来实现请求的分发。Kubernetes中的Service就是用于解决这些问题的核心组件。
以前面创建的webapp应用为例,为了让客户端应用访问到两个Tomcat Pod实例,需要创建一个Service来提供服务。Kubernetes提供了一种快速的方法,即通过kubectl expose命令来创建Service:
# kubectl expose rc webapp
service/webapp exposed
查看新创建的Service,可以看到系统为它分配了一个虚拟的IP地址(ClusterIP),Service所需的端口号则从Pod中的containerPort复制而来:
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp ClusterIP 10.0.0.147 <none> 80/TCP 6s
接下来就可以通过Service的IP地址和Service的端口号访问该Service了
# curl 10.0.0.147
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
......
这里,对Service地址10.0.0.147:80的访问被自动负载分发到了后端两个Pod之一:10.244.2.5或10.244.1.7
除了使用kubectl expose命令创建Service,我们也可以通过配置文件定义Service,再通过kubectl create命令进行创建。例如对于前面的webapp应用,我们可以设置一个Service,代码如下:
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- port: 8081
targetPort: 80
selector:
app: webapp
Service定义中的关键字段是ports和selector。本例中ports定义部分指定了Service所需的虚拟端口号为8081,由于与Pod容器端口号8080不一样,所以需要再通过targetPort来指定后端Pod的端口号。selector定义部分设置的是后端Pod所拥有的label:app=webapp。
创建该Service并查看其ClusterIP地址:
#kubectl apply -f webapp-svc.yaml
service/webapp created
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp ClusterIP 10.0.0.98 <none> 8081/TCP 7s
通过Service的IP地址和Service的端口号进行访问:
# curl 10.0.0.98:8081
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
。。。
同样,对Service地址 10.0.0.98:8081的访问被自动负载分发到了后端两个Pod之一:10.244.2.5或10.244.1.7。目前Kubernetes提供了两种负载分发策略:RoundRobin和SessionAffinity,具体说明如下。
RoundRobin:轮询模式,即轮询将请求转发到后端的各个Pod上。
SessionAffinity:基于客户端IP地址进行会话保持的模式,即第1次将某个客户端发起的请求转发到后端的某个Pod上,之后从相同的客户端发起的请求都将被转发到后端相同的Pod上。
在默认情况下,Kubernetes采用RoundRobin模式对客户端请求进行负载分发,但我们也可以通过设置service.spec.sessionAffinity=ClientIP来启用SessionAffinity策略。这样,同一个客户端IP发来的请求就会被转发到后端固定的某个Pod上了。
通过Service的定义,Kubernetes实现了一种分布式应用统一入口的定义和负载均衡机制。Service还可以进行其他类型的设置,例如设置多个端口号、直接设置为集群外部服务,或实现为HeadlessService(无头服务)模式(将在4.3节介绍)。
2.1 多端口服务
有时一个容器应用也可能提供多个端口的服务,那么在Service的定义中也可以相应地设置为将多个端口对应到多个应用服务。在下面的例子中,Service设置了两个端口号,并且为每个端口号都进行了命名:
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- port: 80
targetPort: 80
name: http
- port: 443
targetPort: 443
name: https
selector:
app: webapp
另一个例子是两个端口号使用了不同的4层协议—TCP和UDP:
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "KubeDns"
spec:
selector:
k8s-app: kube-app
clusterIP: 172.0.0.10
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
2.2 外部服务Service
在某些环境中,应用系统需要将一个外部数据库作为后端服务进行连接,或将另一个集群或Namespace中的服务作为服务的后端,这时可以通过创建一个无Label Selector的Service来实现:
apiVersion: v1
kind: Service
metadata:
name: my-cluster
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
通过该定义创建的是一个不带标签选择器的Service,即无法选择后端的Pod,系统不会自动创建Endpoint,因此需要手动创建一个和该Service同名的Endpoint,用于指向实际的后端访问地址。创建Endpoint的配置文件内容如下:
apiVersion: v1
kind: Endpoints
metadata:
name: my-cluster
subsets:
- addresses:
- ip: 1.2.3.4
ports:
- port: 80
如下图所示,访问没有标签选择器的Service和带有标签选择器的Service一样,请求将会被路由到由用户手动定义的后端Endpoint上。

Service指向外部服务
2.3 kubernetes中pod通过svc访问其他服务
apiVersion: v1
kind: Pod
metadata:
name: cdh
spec:
containers:
- name: centos7-1
image: centos:7
args:
- /bin/sh
- -c
- ping my-cluster.default.svc.cluster.local
ports:
- containerPort: 22
hostPort: 30022
# kubectl exec -it cdh /bin/bash
curl webapp.default.svc.cluster.local:8081
2.4 kubernetes集群外节点通过svc访问服务
方案一: ingress
方案二: NodePort
apiVersion: v1
kind: Service
metadata:
name: kuboard
namespace: kube-system
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 32567
selector:
k8s.kuboard.cn/layer: monitor
k8s.kuboard.cn/name: kuboard
#访问方式 node-ip:server-port
2.5 把一个svc请求转发到两个不同端口的pod
svc 80---> nginx:80 tomcat:8080
常见nginx-pod
# cat deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx1
spec:
replicas: 1
selector:
matchLabels:
app: web1
template:
metadata:
labels:
app: web1
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: webport //重点
containerPort: 80
创建tomcat-pod
# cat deploy3.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat
spec:
replicas: 1
selector:
matchLabels:
app: web1
template:
metadata:
labels:
app: web1
spec:
containers:
- name: tomcat
image: tomcat:8.5.89-jdk17
imagePullPolicy: IfNotPresent
ports:
- name: webport
containerPort: 8080
# kubectl get po -l app=web1 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx1-7d7458bfd8-b4rs2 1/1 Running 0 79m 10.244.1.58 k8s2 <none> <none>
tomcat-79d9f8bf46-q7kbb 1/1 Running 0 3m54s 10.244.1.63 k8s2 <none> <none>
# kubectl exec tomcat-79d9f8bf46-q7kbb -- mkdir /usr/local/tomcat/webapps/ROOT
# kubectl exec tomcat-79d9f8bf46-q7kbb -- bash -c "echo abc > /usr/local/tomcat/webapps/ROOT/index.jsp"
# cat svc3.yaml
---
apiVersion: v1
kind: Service
metadata:
name: nginxtomcat
namespace: default
spec:
selector:
app: web1
ports:
- name: webport
port: 99
targetPort: webport
# kubectl describe svc nginxtomcat
Name: nginxtomcat
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=web1
Type: ClusterIP
IP Families: <none>
IP: 10.1.251.42
IPs: 10.1.251.42
Port: webport 99/TCP
TargetPort: webport/TCP
Endpoints: 10.244.1.63:8080,10.244.1.58:80
Session Affinity: None
Events: <none>
# curl 10.1.251.42:99
ngx1
# curl 10.1.251.42:99
abc
# curl 10.1.251.42:99
ngx1
# curl 10.1.251.42:99
abc
# curl 10.1.251.42:99
ngx1
# curl 10.1.251.42:99
abc
nginx-ingress
特性状态: Kubernetes v1.19 [stable]
Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。
Ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟托管。
Ingress 是什么?
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。
下面是一个将所有流量都发送到同一 Service 的简单 Ingress 示例:
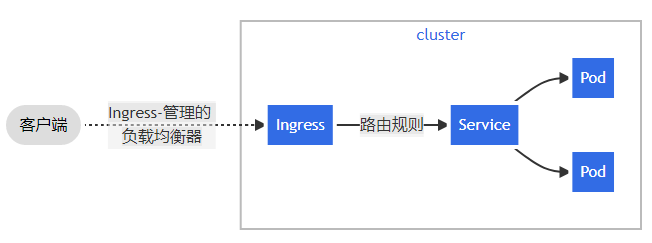
clusterIngress-管理的
负载均衡器路由规则IngressPodServicePod客户端
Ingress 可为 Service 提供外部可访问的 URL、负载均衡流量、终止 SSL/TLS,以及基于名称的虚拟托管。 Ingress 控制器 通常负责通过负载均衡器来实现 Ingress,尽管它也可以配置边缘路由器或其他前端来帮助处理流量。
Ingress 不会公开任意端口或协议。 将 HTTP 和 HTTPS 以外的服务公开到 Internet 时,通常使用 Service.Type=NodePort] 或 Service.Type=LoadBalancer类型的 Service。
部署Nginx ingress控制器
There are multiple ways to install the NGINX ingress controller:
- with Helm, using the project repository chart;
- with
kubectl apply, using YAML manifests;
A few pods should start in the ingress-nginx namespace:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.2/deploy/static/provider/cloud/deploy.yaml
kubernetes1.18
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/provider/baremetal/service-nodeport.yaml
After a while, they should all be running. The following command will wait for the ingress controller pod to be up, running, and ready:
# kubectl get all -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-admission-create-snxhg 0/1 Completed 0 12d
pod/ingress-nginx-controller-68466b9c78-m6bj9 1/1 Running 1 11d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller NodePort 10.1.225.159 <none> 80:30730/TCP,443:32086/TCP 12d
service/ingress-nginx-controller-admission ClusterIP 10.1.184.209 <none> 443/TCP 12d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-nginx-controller 1/1 1 1 12d
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-nginx-controller-65bf56f7fc 0 0 0 12d
replicaset.apps/ingress-nginx-controller-68466b9c78 1 1 1 11d
NAME COMPLETIONS DURATION AGE
job.batch/ingress-nginx-admission-create 1/1 1s 12d
job.batch/ingress-nginx-admission-patch 1/1 1s 12d
ingress-demo
创建所需资源
# cat test-ingress.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
spec:
replicas: 2
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/hello-server
ports:
- containerPort: 9000
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-demo
name: nginx-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: nginx-demo
spec:
containers:
- image: nginx
name: nginx
---
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-demo
name: nginx-demo
spec:
selector:
app: nginx-demo
ports:
- port: 8000
protocol: TCP
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
labels:
app: hello-server
name: hello-server
spec:
selector:
app: hello-server
ports:
- port: 8000
protocol: TCP
targetPort: 9000
ingress规则
每个 HTTP 规则都包含以下信息:
- 可选的
host。在此示例中,未指定host,因此该规则适用于通过指定 IP 地址的所有入站 HTTP 通信。 如果提供了host(例如 foo.bar.com),则rules适用于该host。 - 路径列表 paths(例如,
/testpath),每个路径都有一个由serviceName和servicePort定义的关联后端。 在负载均衡器将流量定向到引用的服务之前,主机和路径都必须匹配传入请求的内容。 backend(后端)是 Service 文档]中所述的服务和端口名称的组合。 与规则的host和path匹配的对 Ingress 的 HTTP(和 HTTPS )请求将发送到列出的backend。
通常在 Ingress 控制器中会配置 defaultBackend(默认后端),以服务于无法与规约中 path 匹配的所有请求。
默认后端
没有设置规则的 Ingress 将所有流量发送到同一个默认后端,而 .spec.defaultBackend 则是在这种情况下处理请求的那个默认后端。 defaultBackend 通常是 Ingress 控制器的配置选项,而非在 Ingress 资源中指定。 如果未设置任何的 .spec.rules,那么必须指定 .spec.defaultBackend。 如果未设置 defaultBackend,那么如何处理所有与规则不匹配的流量将交由 Ingress 控制器决定(请参考你的 Ingress 控制器的文档以了解它是如何处理那些流量的)。
如果没有 hosts 或 paths 与 Ingress 对象中的 HTTP 请求匹配,则流量将被路由到默认后端。
资源后端
Resource 后端是一个引用,指向同一命名空间中的另一个 Kubernetes 资源,将其作为 Ingress 对象。 Resource 后端与 Service 后端是互斥的,在二者均被设置时会无法通过合法性检查。 Resource 后端的一种常见用法是将所有入站数据导向带有静态资产的对象存储后端。
路径类型
Ingress 中的每个路径都需要有对应的路径类型(Path Type)。未明确设置 pathType 的路径无法通过合法性检查。当前支持的路径类型有三种:
-
ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClass。 具体实现可以将其作为单独的pathType处理或者与Prefix或Exact类型作相同处理。 -
Exact:精确匹配 URL 路径,且区分大小写。 -
Prefix:基于以/分隔的 URL 路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。 路径元素指的是由/分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。说明: 如果路径的最后一个元素是请求路径中最后一个元素的子字符串,则不会匹配 (例如:
/foo/bar匹配/foo/bar/baz, 但不匹配/foo/barbaz)。
# cat domain-test.yaml
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.tiger.cn"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server
port:
number: 8000
- host: "demo.tiger.cn"
http:
paths:
- pathType: Prefix
path: "/" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-demo ## java,比如使用路径重写,去掉前缀nginx
port:
number: 8000
---
--kubernetes1.18写法----
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.gz2203.cn"
http:
paths:
- pathType: Prefix
path: "/"
backend:
serviceName: hello-server
servicePort: 8000
- host: "demo.gz2203.cn"
http:
paths:
- pathType: Prefix
path: "/" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
serviceName: nginx-demo ## java,比如使用路径重写,去掉前缀nginx
servicePort: 8000
创建ingress规则
# kubectl apply -f domain-test.yaml
# kubectl describe ingress ingress-host-bar
Name: ingress-host-bar
Namespace: default
Address: 192.168.18.131
Default backend: default-http-backend:80 (<error: endpoints "default-http-backend" not found>)
Rules:
Host Path Backends
---- ---- --------
hello.tiger.cn
/ hello-server:8000 (<none>)
demo.tiger.cn
/ nginx-demo:8000 (<none>)
Annotations: <none>
Events: <none>
做域名解析
192.168.18.131 hello.tiger.cn demo.tiger.cn
访问测试
# curl hello.tiger.cn
Hello World!
# curl demo.tiger.cn
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
共享存储原理
存储资源作为容器云平台的另一个核心基础设施,需要为不同的容器资源提供可靠的存储服务。 在基于 Kubernetes 的容器云平台上,对存储资源的使用通常包括以下几方面:
- 应用配置文件、密钥文件
- 应用数据持久化
- 在不同的应用间共享数据存储
Kubernets 的 Volume 抽象概念就是针对这些问题提出的解决方案。 Kubernetes 的 Volume 类型非常丰富,从临时目录、宿主机目录、ConfigMap、Secret、共享存储(PV 和 PVC) ,到 从 v1.9 引入的 CSI (Container Storage Interface)机制,都可以满足容器应用对资源的需求。
共享存储机制概述
Kubemetes 对于有状态的容器应用或者对数据需要持久化的应用,不仅需要将容器内的目录挂载到宿主机的目录或者 emptyDir 临时存储卷,而且需要更加可靠的存储来保存应用产生的重要数据,以便容器应用在重建之后 ,仍然可以使用之前的数据 。 不过,存储资源和计算资源(CPU/内存〉的管理方式完全不同。为了能够屏蔽底层存储实现的细节,让用户方便使用,同时能让管理员方便管理, Kubemetes 就引入PersistentVolume 和 PersistentVolumeClaim两个资源对象来实现对存储的管理子系统。
PersistentVolume (PV )是对底层网络共享存储的抽象,将共享存储定义为一种“资源”,比如节点( Node )也是一种容器应用可以“消费”的资源。 PV 由管理员进行创建和配置,它与共享存储的具体实现直接相关。
PersistentVolumeClaim (PVC )则是用户对于存储资源的一个“申请”。 就像 Pod “消费”Node 的资源一样, PVC 会“消费” PV 资源。 PVC 可以申请特定的存储空间和访 问模式。
使用 PVC “申请”到一定的存储空间仍然不足以满足应用对于存储设备的各种需求。通常应用程序都会对存储设备的特性和性能有不同的要求,包括读写速度、井发性能、数据冗余等更高的要求, Kubernetes 开始引入了一个新的资源对象 StorageClass ,用于标记存储资源的特性和性能。到 v1.6 版本时, StorageClass 和动态资源供应的机制得到了完善,实现了存储卷的按需创建,在共享存储的自动化管理进程中实现了重要的一步。
通过 StorageClass 的定义,管理员可以将存储资源定义为某种类别( Class ),正如存储设备对于自身的配置描述( Profile ),例如“快速存储”“慢速存储”“有数据冗余”“无数据冗余”等。用户根据 StorageClass 的描述就能够直观得知各种存储资源的特性,就可以根据应用对存储资源的需求去申请存储资源了。
Kubernetes 从 1.9 版本开始引入容器存储接口 CSI 机制,目标是在 Kubernets 和外部存储系统自建建立一套标准的存储管理接口,通过该接口为容器提供存储服务,类似 CRI (容器运行时接口)和 CNI (容器网络接口)
PV 详解
PV 作为存储资源,主要包括存储能力、访问模式、存储类型、回收策略、后端存储类型等关键信息的设置。
下面的例子声明的 PV 具有如下属性: 5Gi 存储空间,访问模式为“ ReadWriteOnce ”,存储类型为“ slow ”(要求系统中己存在名为 slow 的 StorageClass ),回收策略为“Recycle ”,并且后端存储类型为nfs(设置了 NFS Server 的 IP 地址和路径):
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
nfs:
path: /tmp
server: 10.3.50.111
pv 的关键配置参数
-
存储能力
描述存储设备具备的能力,目前仅支持对存储空间的设置( storage=xx ) ,未来可能加入 IOPS、吞吐率等指标的设置
-
存储卷模式
kubernetes 从1.13版本开始引入存储卷类型的设置 (volumeMode=xxx), 可选类型包括 Filesystem (文件系统) 和 Block (块设备),默认值为 Filesystem
下面的例子为使用块设备的PV的定义
apiVersion: v1 kind: PersistentVolume metadata: name: block-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain volumeMode: Block fc: targetWWNs: ["50060e801049cfd1"] lun: 0 readOnly: false
3.访问模式
对 PV 进行访问模式的设置,用于描述用户的应用对存储资源的访问权限。访问模式如下:
- ReadWriteOnce (RWO): 读写权限,并且只能被单个Node 挂载
- ReadOnlyMany (ROX) : 只读权限,允许被多个Node 挂载
- ReadWriteMany (RWX) : 读写权限,允许被多个Node 挂载
某些 PV 可能指出多种访问模式,但 PV 再挂载是只能使用一种访问模式,多种访问模式不能同时生效
4.存储类别
PV 可以设定其存储的类型,通过 StorageClassName 参数指定一个 StorageClass 资源对象的名称。具有特定类别的 PV 只能与请求了该类别的 PVC 进行绑定。 未设定类别的 PV 则只能与不请求任何类别的 PVC 进行绑定
5.回收策略
通过 PV 定义中 persistenVolumeReclaimPolicy 字段进行设置,可选项如下:
- 保留: 保留数据,需要手工处理[Retain]
- 回收空间: 简单清楚文件的操作 (例如执行 rm -rf /thevolume/* 命令) [Recycle]
- 删除: 与 PV 相连的后端存储完成 Volume 的删除操作
目前,只有 NFS和HostPath 两种类型的存储支持 Recycle 策略; AWS EBS、GCE PD、Azure Disk 和 Cinder volumes支持 Delete 策略
6.挂载参数**(Mount Options)**
在将PV挂载到一个Node上时,根据后端存储的特点,可能需要设置额外的挂载参数,可以根据PV定义中的mountOptions字段进行设置。下面的例子为对一个类型为gcePersistentDisk的PV设置挂载参数:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv01
labels:
name: nfs-pv01
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs-pv-01
nfs:
server: IP
path: /nfs/data/data01
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
nfs:
path: /tmp
server: 172.17.0.2
7.节点亲和性
PV可以设置节点亲和性来限制只能通过某些Node访问Volume,可以在PV定义中的nodeAffinity字段进行设置。使用这些Volume的Pod将被调度到满足条件的Node上。
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-local-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- my-node
公有云提供的存储卷(如AWS EBS、GCE PD、Azure Disk等)都由公有云自动完成节点亲和性设置,无须用户手工设置。
PV生命周期的各个阶段
某个PV在生命周期中可能处于以下4个阶段(Phaes)之一。
Available:可用状态,还未与某个PVC绑定。
Bound:已与某个PVC绑定。
Released:绑定的PVC已经删除,资源已释放,但没有被集群回收。
Failed:自动资源回收失败。
定义了PV以后如何使用呢?这时就需要用到PVC了。接下来将对PVC进行详细说明。
PVC详解
PVC作为用户对存储资源的需求申请,主要包括存储空间请求、访问模式、PV选择条件和存储类别等信息的设置。下例声明的PVC具有如下属性:申请8GiB存储空间,访问模式为ReadWriteOnce,PV选择条件为包含标签“release=stable”并且包含条件为“environmentIn [dev]”的标签,存储类别为“slow”(要求在系统中已存在名为slow的StorageClass):
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
PVC的关键配置参数说明如下。
资源请求(Resources):描述对存储资源的请求,目前仅支持request.storage的设置,即存储空间大小。`
访问模式(Access Modes):PVC也可以设置访问模式,用于描述用户应用对存储资源的访问权限。其三种访问模式的设置与PV的设置相同。`
存储卷模式(Volume Modes):PVC也可以设置存储卷模式,用于描述希望使用的PV存储卷模式,包括文件系统和块设备。
PV选择条件(Selector):通过对Label Selector的设置,可使PVC对于系统中已存在的各种PV进行筛选。系统将根据标签选出合适的PV与该PVC进行绑定。选择条件可以使用matchLabels和matchExpressions进行设置,如果两个字段都设置了,则Selector的逻辑将是两组条件同时满足才能完成匹配。
存储类别(Class):PVC 在定义时可以设定需要的后端存储的类别(通过storageClassName字段指定),以减少对后端存储特性的详细信息的依赖。只有设置了该Class的PV才能被系统选出,并与该PVC进行绑定。
PVC也可以不设置Class需求。如果storageClassName字段的值被设置为空(storageClassName=""),则表示该PVC不要求特定的Class,系统将只选择未设定Class的PV与之匹配和绑定。PVC也可以完全不设置storageClassName字段,此时将根据系统是否启用了名为DefaultStorageClass的admission controller进行相应的操作。
未启用DefaultStorageClass:等效于PVC设置storageClassName的值为空(storageClassName=""),即只能选择未设定Class的PV与之匹配和绑定。
启用DefaultStorageClass:要求集群管理员已定义默认的StorageClass。如果在系统中不存在默认的StorageClass,则等效于不启用DefaultStorageClass的情况。如果存在默认的StorageClass,则系
统将自动为PVC创建一个PV(使用默认StorageClass的后端存储),并将它们进行绑定。集群管理员设置默认StorageClass的方法为,在StorageClass的定义中加上一个annotation“storageclass.kubernetes.io/is-
default-class= true”。如果管理员将多个StorageClass都定义为default,则由于不唯一,系统将无法为PVC创建相应的PV。
注意,PVC和PV都受限于Namespace,PVC在选择PV时受到Namespace的限制,只有相同Namespace中的PV才可能与PVC绑定。Pod在引用PVC时同样受Namespace的限制,只有相同Namespace中的PVC才能挂载到Pod内。
当Selector和Class都进行了设置时,系统将选择两个条件同时满足的PV与之匹配。
另外,如果资源供应使用的是动态模式,即管理员没有预先定义PV,仅通过StorageClass交给系统自动完成PV的动态创建,那么PVC再设定Selector时,系统将无法为其供应任何存储资源。
在启用动态供应模式的情况下,一旦用户删除了PVC,与之绑定的PV也将根据其默认的回收策略“Delete”被删除。如果需要保留PV(用户数据),则在动态绑定成功后,用户需要将系统自动生成PV的回收策略从“Delete”改成“Retain”。
PV 和 PVC 生命周期
我们可以将PV看作可用的存储资源,PVC则是对存储资源的需求,PV和PVC的相互关系遵循如图8.1所示的生命周期。
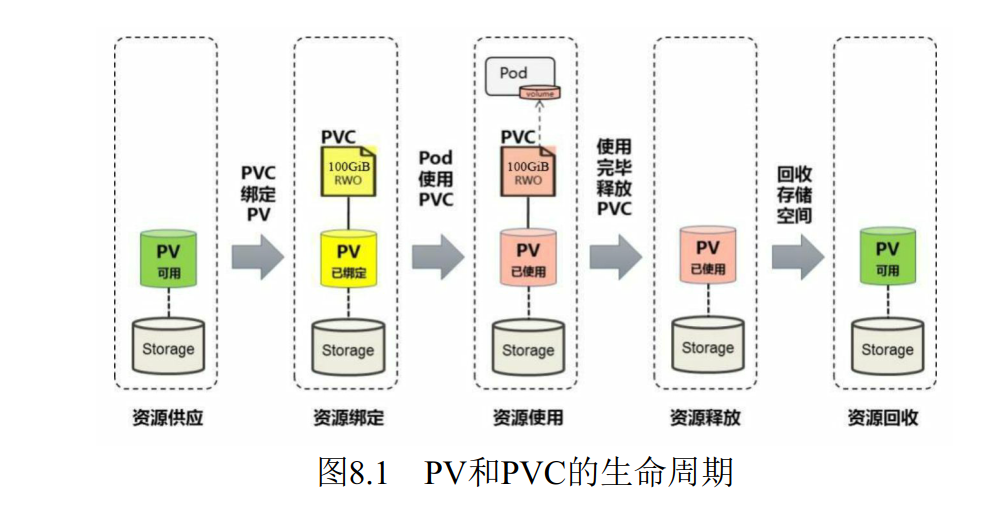
资源供应
Kubernetes支持两种资源的供应模式:静态模式(Static)和动态模式(Dynamic)。资源供应的结果就是创建好的PV。
◎ 静态模式:集群管理员手工创建许多PV,在定义PV时需要将后端存储的特性进行设置。
◎ 动态模式:集群管理员无须手工创建PV,而是通过StorageClass的设置对后端存储进行描述,标记为某种类型。此时要求PVC对存储的类型进行声明,系统将自动完成PV的创建及与PVC的绑定。PVC可以声明Class为"",说明该PVC禁止使用动态模式。
资源绑定
在用户定义好PVC之后,系统将根据PVC对存储资源的请求(存储空间和访问模式)在已存在的PV中选择一个满足PVC要求的PV,一旦找到,就将该PV与用户定义的PVC进行绑定,用户的应用就可以使用这个PVC了。如果在系统中没有满足PVC要求的PV,PVC则会无限期处于Pending状态,直到等到系统管理员创建了一个符合其要求的PV。PV一旦绑定到某个PVC上,就会被这个PVC独占,不能再与其他PVC进行绑定了。在这种情况下,当PVC申请的存储空间比PV的少时,整个PV的空间就都能够为PVC所用,可能会造成资源的浪费。如果资源供应使用的是动态模式,则系统在为PVC找到合适的StorageClass后,将自动创建一个PV并完成与PVC的绑定。
资源使用
Pod使用Volume的定义,将PVC挂载到容器内的某个路径进行使用。Volume的类型为persistentVolumeClaim,在后面的示例中再进行详细说明。在容器应用挂载了一个PVC后,就能被持续独占使用。不过,多个Pod可以挂载同一个PVC,应用程序需要考虑多个实例共同访问一块存储空间的问题。
资源释放
当用户对存储资源使用完毕后,用户可以删除PVC,与该PVC绑定的PV将会被标记为“已释放”,但还不能立刻与其他PVC进行绑定。通过之前PVC写入的数据可能还被留在存储设备上,只有在清除之后该PV才能再次使用。
资源回收
对于PV,管理员可以设定回收策略,用于设置与之绑定的PVC释放资源之后如何处理遗留数据的问题。只有PV的存储空间完成回收,才能供新的PVC绑定和使用。回收策略详见下节的说明。
下面通过两张图分别对在静态资源供应模式和动态资源供应模式下,PV、PVC、StorageClass及Pod使用PVC的原理进行说明。
图8.2描述了在静态资源供应模式下,通过PV和PVC完成绑定,并供Pod使用的存储管理机制。
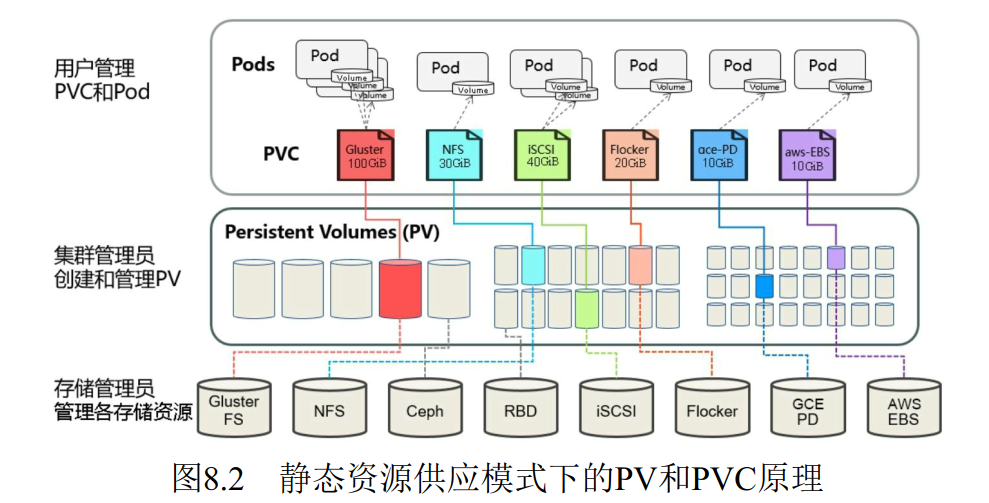
图8.3描述了在动态资源供应模式下,通过StorageClass和PVC完成资源动态绑定(系统自动生成PV),并供Pod使用的存储管理机制。
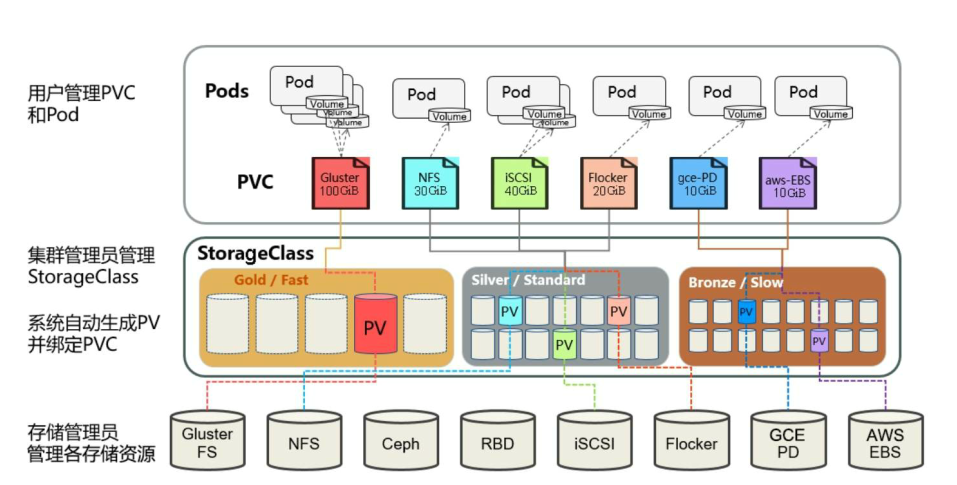
pv和pvc使用案例
1)准备nfs共享路径
1.准备nfs存储路径
[root@nfs ~]# mkdir /data/nfs/nfs{1..3} -p
2.配置nfs将新建的路径提供共享存储
[root@nfs ~]# vim /etc/exports
/data/nfs/nfs1 192.168.18.0/24(rw,sync,no_root_squash)
/data/nfs/nfs2 192.168.18.0/24(rw,sync,no_root_squash)
/data/nfs/nfs3 192.168.18.0/24(rw,sync,no_root_squash)
3.重启nfs
[root@nfs ~]# systemctl restart nfs
4.查看共享存储路径列表
[root@nfs ~]# showmount -e
Export list for nfs
/data/nfs/nfs3 192.168.18.0/24
/data/nfs/nfs2 192.168.18.0/24
/data/nfs/nfs1 192.168.18.0/24
2)编写pv yaml文件
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-1
spec:
capacity:
storage: 1Gi #存储空间大小
accessModes: #访问模式
- ReadWriteMany #多主机读写
persistentVolumeReclaimPolicy: Retain #回收策略为保留
nfs: #使用nfs存储类型
path: /data/nfs/nfs1 #nfs共享路径
server: 192.168.18.132 #nfs服务器地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-2
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /data/nfs/nfs2
server: 192.168.18.132
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-3
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
path: /data/nfs/nfs3
server: 192.168.18.132
# kubectl create -f pv.yaml
persistentvolume/pv-1 created
persistentvolume/pv-2 created
persistentvolume/pv-3 created
# kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-1 1Gi RWX Retain Available 72s Filesystem
pv-2 2Gi RWX Retain Available 72s Filesystem
pv-3 3Gi RWX Retain Available 72s Filesystem
# kubectl describe pv pv-1
Name: pv-1
Labels: <none>
Annotations: <none>
Finalizers: [kubernetes.io/pv-protection]
StorageClass:
Status: Available
Claim:
Reclaim Policy: Retain
Access Modes: RWX
VolumeMode: Filesystem
Capacity: 1Gi
Node Affinity: <none>
Message:
Source:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: 192.168.18.132
Path: /data/nfs/nfs1
ReadOnly: false
Events: <none>
3)编写pvc yaml文件
# cat pvc1.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-1
#namespace: tiger
spec:
accessModes: #设置访问模式
- ReadWriteMany #多节点可读可写
resources: #设置请求的PV容量
requests:
storage: 1Gi #设置容量为1G,`可以匹配到pv-1`
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-2
#namespace: tiger
spec:
accessModes: #设置访问模式
- ReadWriteMany #多节点可读可写
resources: #设置请求的PV容量
requests:
storage: 1Gi \#设置容量为1G,`可以匹配到pv-2`
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-3
#namespace: tiger
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi \#设置容量为5G,`应该是无法匹配到任何pv`
# kubectl create -f pvc-suiji.yaml
persistentvolumeclaim/pvc-1 created
persistentvolumeclaim/pvc-2 created
persistentvolumeclaim/pvc-3 created
# kubectl get pvc -n dev
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-1 Bound pv-1 1Gi RWX 2m16s
pvc-2 Bound pv-2 2Gi RWX 2m16s
pvc-3 Pending 2m16s
#由于pv-3设置的请求容量为5G,没有任何pv的容量在5G以上,因此pvc-3一直处于penging状态,无法匹配pvc
4)编写指定pv的pvc yaml文件
# vim pvc-zhiding.yaml
apiVersion: v1
kind: PersistentVolume #控制器类型为pv
metadata:
name: pv-1
labels: #定义一组标签,用于pvc调用
pv: pv-1 #标签pv值为pv-1
spec:
capacity: #定义pv的容量
storage: 2Gi
accessModes: #定义访问模式为多主机可读可写
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain #定义回收策略
nfs: #定义使用的存储类型
path: /data/nfs/nfs1 #共享存储路径
server: 192.168.18.132 #nfs地址
---
apiVersion: v1
kind: PersistentVolumeClaim #控制器类型为pvc
metadata:
name: pvc-1
namespace: dev #指定所在的namespace
spec:
accessModes: #定义访问模式,多主机可读可写,和pv的访问模式保持一致
- ReadWriteMany
resources: #定义申请pv资源的大小
requests:
storage: 1Gi
selector: #定义标签选择器,用于关联具体使用哪个pv资源
matchLabels:
pv: pv-1
5) 创建Pod资源使用PVC高级存储
# vim pod-pv-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-pvc1
namespace: dev
spec:
containers:
- name: nginx-1
image: nginx:1.17.1
ports:
- containerPort: 80
volumeMounts: #定义持久卷挂载路径
- name: volume-1 #指定pvc名称
mountPath: /usr/share/nginx/html #指定pvc挂载到容器的路径
volumes: #定义持久卷信息
- name: volume-1 #定义持久卷名称
persistentVolumeClaim: #使用pvc类型
claimName: pvc-1 #指定使用的pvc名称
readOnly: false #关闭只读
# kubectl describe po pod-pvc1
Name: pod-pvc1
Namespace: default
Priority: 0
Node: k8s3/192.168.18.131
Start Time: Sun, 17 Apr 2022 22:11:53 +0800
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.244.2.200
IPs:
IP: 10.244.2.200
Containers:
nginx-1:
Container ID: docker://f4875f30918a366309bf300af9caf76f4282960f09aba73d9b5526b23fedde0e
Image: nginx:1.17.1
Image ID: docker-pullable://nginx@sha256:b4b9b3eee194703fc2fa8afa5b7510c77ae70cfba567af1376a573a967c03dbb
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sun, 17 Apr 2022 22:11:59 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/usr/share/nginx/html from volume-1 (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-9wzjf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
volume-1:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: pvc-1
ReadOnly: false
default-token-9wzjf:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-9wzjf
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 103s default-scheduler Successfully assigned default/pod-pvc1 to k8s3
Normal Pulling 102s kubelet Pulling image "nginx:1.17.1"
Normal Pulled 97s kubelet Successfully pulled image "nginx:1.17.1" in 4.875663s
Normal Created 97s kubelet Created container nginx-1
Normal Started 97s kubelet Started container nginx-1
在/data/nfs/nfs1/ 下添加index.html文件,并修改权限
测试访问pod
# curl 10.244.2.200
cicd pv pvc pod-use-pvc test
6)将PV的回收策略设置为Recycle观察生命周期
# vim pv-recycle.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-3
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle #将PV回收策略设置为Recycle
nfs:
path: /data/nfs/nfs3
server: 192.168.18.192
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-3
namespace: tiger
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi
2.创建资源
kubectl create -f pv-recycle.yaml
persistentvolume/pv-3 created
persistentvolumeclaim/pvc-3 created
3.查看pv和pvc的状态
# kubectl get pv,pvc -n dev
#可以看到pvc-3绑定了pv-3
4.删除pvc-3
# kubectl delete persistentvolumeclaim/pvc-3 -n dev
persistentvolumeclaim "pvc-3" deleted
5.持续观察pv的状态
# kubectl get pv -w
总结:当pvc-3删除后,对应吃pv-3首先处于released状态,当回收策略完成后,pv-3再次处于available状态。
StorageClass 详解
StorageClass作为对存储资源的抽象定义,对用户设置的PVC申请屏蔽后端存储的细节,一方面减少了用户对于存储资源细节的关注,另一方面减轻了管理员手工管理PV的工作,由系统自动完成PV的创建和绑定,实现了动态的资源供应。基于StorageClass的动态资源供应模式将逐步成为云平台的标准存储配置模式。
StorageClass的定义主要包括名称、后端存储的提供者(provisioner)和后端存储的相关参数配置。StorageClass一旦被创建出来,则将无法修改。如需更改,则只能删除原StorageClass的定义重建。下例定义了一个名为standard的StorageClass,提供者为aws-ebs,其参数设置了一个type,值为gp2:
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
StorageClass的关键配置参数
1.提供者(Provisioner)
描述存储资源的提供者,也可以看作后端存储驱动。目前Kubernetes支持的Provisioner都以“kubernetes.io/”为开头,用户也可以使用自定义的后端存储提供者。为了符合StorageClass的用法,自定义Provisioner需要符合存储卷的开发规范,详见 https://github.com/kubernetes/community/blob/master/contributors/design-proposals/volume-provisioning.md 的说明。
2.参数(Parameters)
后端存储资源提供者的参数设置,不同的Provisioner包括不同的参数设置。某些参数可以不显示设定,Provisioner将使用其默认值。接下来通过几种常见的Provisioner对StorageClass的定义进行详细说明。
1)AWS EBS存储卷
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
zone: us-east-1d
iopsPerGB: "10"
参数说明如下(详细说明请参考AWS EBS文档)。
◎ type:可选项为io1,gp2,sc1,st1,默认值为gp2。
◎ zone:AWS zone的名称。
◎ iopsPerGB:仅用于io1类型的Volume,意为每秒每GiB的I/O操作数量。
◎ encrypted:是否加密。
◎ kmsKeyId:加密时的Amazon Resource Name。
2)GCE PD存储卷
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
zone: us-central1-a
参数说明如下(详细说明请参考GCE文档)。
◎ type:可选项为pd-standard、pd-ssd,默认值为pd-standard。
◎ zone:GCE zone名称。
3)GlusterFS存储卷
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/glusterfs
parameters:
resturl: "http://127.0.0.1:8081"
clusterid: "630372ccdc720a92c681fb928f27b53f"
restauthenabled: "true"
restuser: "admin"
secretNamespace: "default"
secretName: "heketi-secret"
gidMin: "40000"
gidMax: "50000"
volumetype: "replicate:3"
参数说明如下(详细说明请参考GlusterFS和Heketi的文档)。
◎ resturl:Gluster REST服务(Heketi)的URL地址,用于自动完成GlusterFSvolume的设置。
◎ restauthenabled:是否对Gluster REST服务启用安全机制。
◎ restuser:访问Gluster REST 服务的用户名。
◎ secretNamespace和secretName:保存访问Gluster REST服务密码的Secret资源对象名。
◎ clusterid:GlusterFS的Cluster ID。
◎ gidMin和gidMax:StorageClass的GID范围,用于动态资源供应时为PV设置的GID。
◎ volumetype:设置GlusterFS的内部Volume类型,例如replicate:3(Replicate类型,3份副本);disperse:4:2(Disperse类型,数据4份,冗余两份;“none”(Distribute类型)。
4)OpenStack Cinder存储卷
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
provisioner: kubernetes.io/cinder
parameters:
type: fast
availability: nova
参数说明如下。
◎ type:Cinder的VolumeType,默认值为空。
◎ availability:Availability Zone,默认值为空。
其他Provisioner的StorageClass相关参数设置请参考它们各自的配置手册。
设置默认的StorageClass
要在系统中设置一个默认的StorageClass,则首先需要启用名为DefaultStorageClass的admission controller,即在kube-apiserver的命令行参数–admission-control中增加:
--admission-control=...,DefaultStorageClass
然后,在StorageClass的定义中设置一个annotation:
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
annotations:
storageclass.beta.kubernetes.io/is-default-class="true"
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
通过kubectl create命令创建成功后,查看StorageClass列表,可以看到名为gold的StorageClass被标记为default:
#kubectl get sc
NAME TYPE
gold(default) kubernetes.io/gce-pd
k8s之StorageClass+NFS
一、什么是StorageClass
Kubernetes提供了一套可以自动创建PV的机制,即:Dynamic Provisioning.而这个机制的核心在于:StorageClass这个API对象.
StorageClass对象会定义下面两部分内容:
1,PV的属性.比如,存储类型,Volume的大小等.
2,创建这种PV需要用到的存储插件
有了这两个信息之后,Kubernetes就能够根据用户提交的PVC,找到一个对应的StorageClass,之后Kubernetes就会调用该StorageClass声明的存储插件,进而创建出需要的PV.
但是其实使用起来是一件很简单的事情,你只需要根据自己的需求,编写YAML文件即可,然后使用kubectl create命令执行即可
二、为什么需要StorageClass
在一个大规模的Kubernetes集群里,可能有成千上万个PVC,这就意味着运维人员必须实现创建出这个多个PV,此外,随着项目的需要,会有新的PVC不断被提交,那么运维人员就需要不断的添加新的,满足要求的PV,否则新的Pod就会因为PVC绑定不到PV而导致创建失败.而且通过 PVC 请求到一定的存储空间也很有可能不足以满足应用对于存储设备的各种需求
而且不同的应用程序对于存储性能的要求可能也不尽相同,比如读写速度、并发性能等,为了解决这一问题,Kubernetes 又为我们引入了一个新的资源对象:StorageClass,通过 StorageClass 的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,用户根据 StorageClass 的描述就可以非常直观的知道各种存储资源的具体特性了,这样就可以根据应用的特性去申请合适的存储资源了。
三、StorageClass运行原理及部署流程
要使用 StorageClass,我们就得安装对应的自动配置程序,比如我们这里存储后端使用的是 nfs,那么我们就需要使用到一个 nfs-client 的自动配置程序,我们也叫它 Provisioner,这个程序使用我们已经配置好的 nfs 服务器,来自动创建持久卷,也就是自动帮我们创建 PV。
1.自动创建的 PV 以${namespace}-${pvcName}-${pvName}这样的命名格式创建在 NFS 服务器上的共享数据目录中
2.而当这个 PV 被回收后会以archieved-${namespace}-${pvcName}-${pvName}这样的命名格式存在 NFS 服务器上。
1.原理及部署流程说明
详细的运作流程可以参考下图:
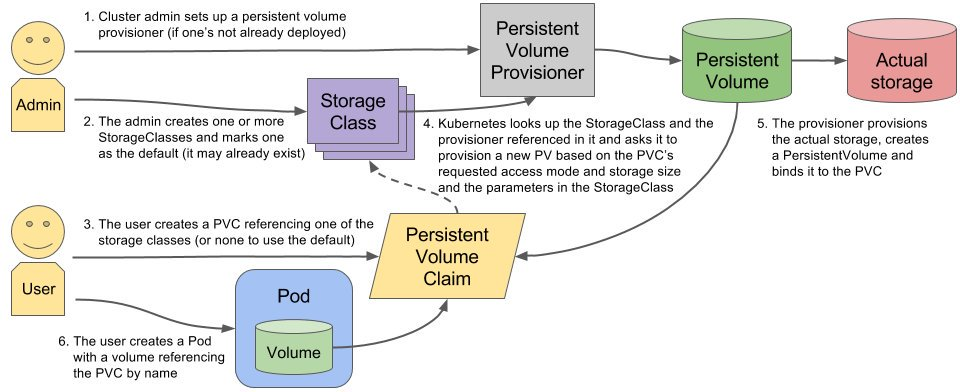
搭建StorageClass+NFS,大致有以下几个步骤:
1.创建一个可用的NFS Server
2.创建Service Account.这是用来管控NFS provisioner在k8s集群中运行的权限
3.创建StorageClass.负责建立PVC并调用NFS provisioner进行预定的工作,并让PV与PVC建立管理
4.创建NFS provisioner.有两个功能,一个是在NFS共享目录下创建挂载点(volume),另一个则是建了PV并将PV与NFS的挂载点建立关联
四、创建StorageClass
1.创建NFS共享服务
准备空磁盘
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 100G 0 disk
分区
# gdisk /dev/sdb
做文件系统
# mkfs.xfs /dev/sdb
挂载
# mkdir -pv /data/nfs
# mount /dev/sdb1 /data/nfs/
[root@storage ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 100G 0 disk
└─sdb1 8:17 0 100G 0 part /data/nfs
上述步骤也可以使用现有的磁盘创建新的目录,进行下列步骤
# mkdir -pv /data/nfs
------------
# 在服务端 创建共享目录/data/nfs/,并且属主和属组都为:nfsnobody,其中nfsnobody是安装nfs服务时默认的用户;
yum -y install nfs-utils rpcbind
# chown -R nfsnobody.nfsnobody /data/nfs/
# chmod 666 /data/nfs/
# ll /data/
total 0
drw-rw-rw- 2 nfsnobody nfsnobody 6 Dec 30 17:46 nfs
编辑配置 NFS 配置文件 ;
# cat /etc/exports
/data/nfs 10.3.133.0/24(rw,sync,no_root_squash)
其中:/data/nfs 是服务器端共享的目录
10.3.133.0/24共享目录的客户端ip地址
配置详解:
复制
ro 只读访问
rw 读写访问
sync 所有数据在请求时写入共享
async NFS在写入数据前可以相应请求
secure NFS通过1024以下的安全TCP/IP端口发送
insecure NFS通过1024以上的端口发送
wdelay 如果多个用户要写入NFS目录,则归组写入(默认)
no_wdelay 如果多个用户要写入NFS目录,则立即写入,当使用async时,无需此设置。
Hide 在NFS共享目录中不共享其子目录
no_hide 共享NFS目录的子目录
subtree_check 如果共享/usr/bin之类的子目录时,强制NFS检查父目录的权限(默认)
no_subtree_check 和上面相对,不检查父目录权限
all_squash 共享文件的UID和GID映射匿名用户anonymous,适合公用目录。
no_all_squash 保留共享文件的UID和GID(默认)
root_squash root用户的所有请求映射成如anonymous用户一样的权限(默认)
no_root_squas root用户具有根目录的完全管理访问权限
anonuid=xxx 指定NFS服务器/etc/passwd文件中匿名用户的UID
# exportfs -r #让配置文件生效
启动RPC 和 NFS 服务
# systemctl start rpcbind
# systemctl enable rpcbind
# systemctl start nfs
# systemctl enable nfs
查看NFS服务是否向rpc注册端口信息,主端口号是:111
# rpcinfo -p localhost
program vers proto port service
100000 4 tcp 111 portmapper
100000 3 tcp 111 portmapper
100000 2 tcp 111 portmapper
100000 4 udp 111 portmapper
100000 3 udp 111 portmapper
100000 2 udp 111 portmapper
-----
客户端配置
yum -y install nfs-utils rpcbind
启动RPC 和 NFS 服务
# systemctl start rpcbind
# systemctl enable rpcbind
# systemctl start nfs
# systemctl enable nfs
查看共享
# showmount -e 10.3.133.14
Export list for 10.3.133.14:
/data/nfs 10.3.133.0/24
当前环境NFS server及共享目录信息
IP: 172.16.155.227
Export PATH: /data/volumes/
2.使用以下文档配置account及相关权限
rbac.yaml: #唯一需要修改的地方只有namespace,根据实际情况定义
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default #根据实际环境设定namespace,下面类同
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
3.创建NFS资源的StorageClass
nfs-StorageClass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: tigerfive-nfs-storage #这里的名称要和provisioner配置文件中的环境变量PROVISIONER_NAME保持一致
parameters:
archiveOnDelete: "false"
4.创建NFS provisioner
nfs-provisioner.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default #与RBAC文件中的namespace保持一致
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: tigerfive-nfs-storage #provisioner名称,请确保该名称与 nfs-StorageClass.yaml文件中的provisioner名称保持一致
- name: NFS_SERVER
value: 172.16.155.227 #NFS Server IP地址
- name: NFS_PATH
value: /data/volumes #NFS挂载卷
volumes:
- name: nfs-client-root
nfs:
server: 172.16.155.227 #NFS Server IP地址
path: /data/volumes #NFS 挂载卷
使用nfs storageclass遇到的问题
方法一
我在部署jenkins的时候创建了pvc,一直是pending的状态,然后describe pvc:
waiting for a volume to be created, either by external provisioner “fuseim.pri/ifs” or manually created by system administrator
搜索无果,然后查看nfs-client-provisioner的logs:
Kubernetes v1.20.0 报"unexpected error getting claim reference: selfLink was empty, can’t make reference"
最后从这里找到了解决办法
https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner/issues/25
在kube-apiserver.yaml文件的这个位置添加一行:- --feature-gates=RemoveSelfLink=false
保存文件后,然后kubectl apply -f kube-apiserver.yaml
这是由于v1.20.0中禁用了selfLink的原因!
方法二:
新的不基于 SelfLink 功能的 provisioner 镜像:
国外的:gcr.io/k8s-staging-sig-storage/nfs-subdir-external-provisioner:v4.0.0
国内:
registry.cn-beijing.aliyuncs.com/pylixm/nfs-subdir-external-provisioner:v4.0.0
五、创建测试pod,检查是否部署成功
1.Pod+PVC
创建PVC
test-claim.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
annotations:
volume.beta.kubernetes.io/storage-class: "managed-nfs-storage" #与nfs-StorageClass.yaml metadata.name保持一致
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
确保PVC状态为Bound
[root@k8s-master-155-221 deploy]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-claim Bound pvc-aae2b7fa-377b-11ea-87ad-525400512eca 1Mi RWX managed-nfs-storage 2m48s
[root@k8s-master-155-221 deploy]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-aae2b7fa-377b-11ea-87ad-525400512eca 1Mi RWX Delete Bound default/test-claim managed-nfs-storage 4m13s
创建测试pod,查看是否可以正常挂载
test-pod.yaml
kind: Pod
apiVersion: v1
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: busybox:1.24
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1" #创建一个SUCCESS文件后退出
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim #与PVC名称保持一致
检查结果:
[root@nginx-keepalived-155-227 ~]# ll /data/volumes/default-test-claim-pvc-aae2b7fa-377b-11ea-87ad-525400512eca/ #文件规则是按照${namespace}-${pvcName}-${pvName}创建的
总用量 0
-rw-r--r-- 1 root root 0 2020-01-15 17:51 SUCCESS #下面有一个 SUCCESS 的文件,证明我们上面的验证是成功
评论区